静觅爬虫学习笔记2-urllib库的基本使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了静觅爬虫学习笔记2-urllib库的基本使用相关的知识,希望对你有一定的参考价值。
1.什么是Urllib
它是Python内置的Http请求库
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
2.urlopen 帮助我们发送request请求
![]()
第一个参数为网站的url,第2个参数是一些额外i的数据,例如post的数据,第3个是超时的设置,其他自行百度
举个简单的例子:
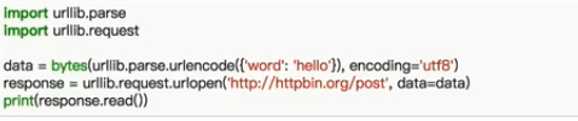
3.响应
响应只要注意响应类型,状态码和响应头
例:
![]()
4.Request 用于加入一些更为复杂的信息
例:

5。设置代理
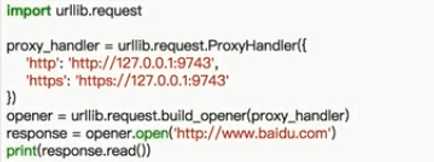
6.cookie
import http.cookiejar,urllib.request filename = ‘cookie.txt‘ cookier = http.cookiejar.MozillaCookieJar(filename) handler=urllib.request.HTTPCookieProcessor(cookier) opener = urllib.request.build_opener(handler) response = opener.open("http://www.baidu.com") cookier.save(ignore_discard=True,ignore_expires=True)
# ignore_discard的意思是即使cookies将被丢弃也将它保存下来,
# ignore_expires的意思是如果cookies已经过期也将它保存并且文件已存在时将覆盖
7.异常处理

8.url解析
1.urlparse,用于解析url

2.urlunparse
用于将字符处理成url

3.urlencode 将信息加入到url中
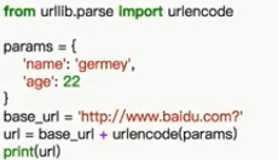
以上是关于静觅爬虫学习笔记2-urllib库的基本使用的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫学习笔记.Beautiful Soup库的使用