爬取N个网页,并将其记录
Posted 温酒待君归
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取N个网页,并将其记录相关的知识,希望对你有一定的参考价值。
挖的坑,终于能填上了,先共享出来,大家有个对比参考。也帮忙找找错误。我也正在看,看看原来是哪里出了问题。
下面这段代码已经实现了网页的爬取:
其效果为:
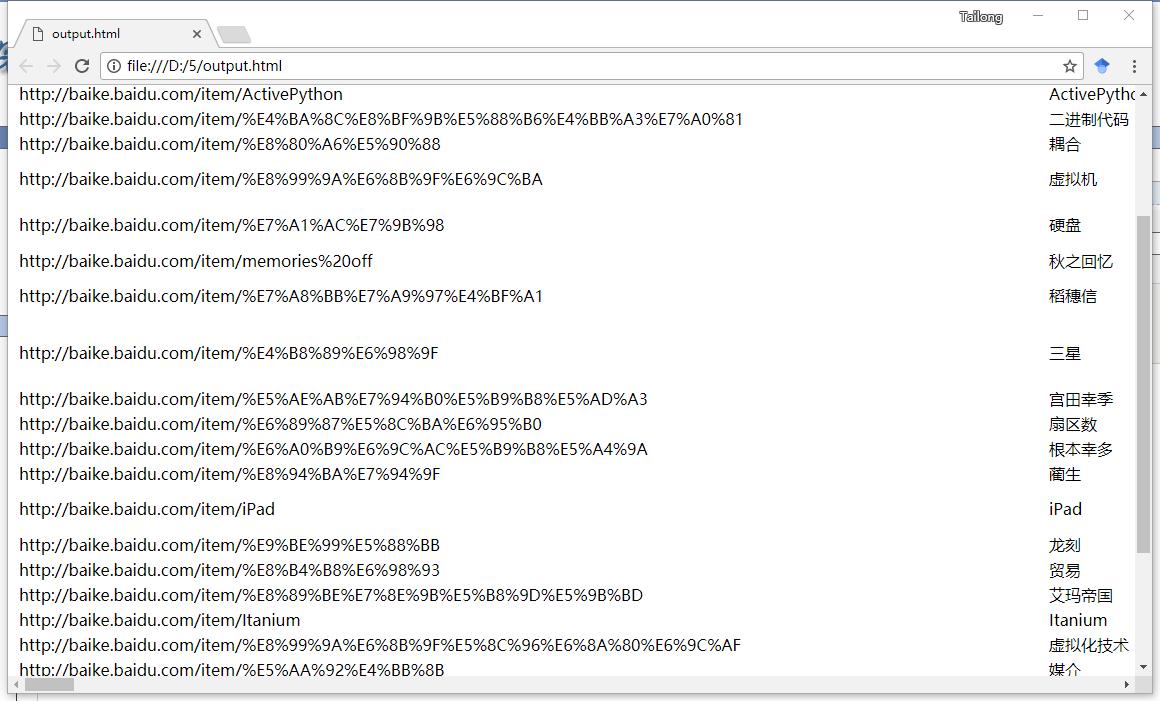
下面给出详细说明:
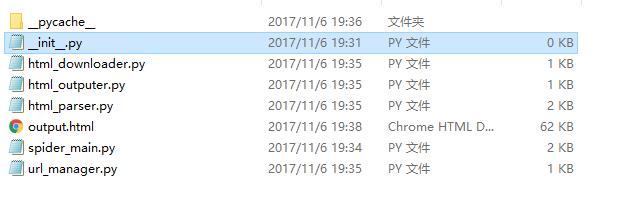
上图中出现的 __init__.py 文件,是一个空的,但是必须建立(我也没想明白为啥)。
程序结束后,打开output.html 就可以了。
1.这是网页管理模块 url_manager.py (点击+号,看代码)


class UrlManager(object): def __init__(self): self.new_urls=set() self.old_urls=set() #向管理器中添加一个新的url def add_new_url(self,url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) #向管理器中添加多个新的url def add_new_urls(self,urls): if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) #判断管理器中是否还有新的待爬取的url def has_new_url(self): return len(self.new_urls)!=0 #从管理器中获取一个新的待爬取的url def get_new_url(self): new_url=self.new_urls.pop()#获取并移除 self.old_urls.add(new_url)#添加至旧的集合 return new_url
2.这是下载网页模块 html_downloader.py
import urllib.request class HtmlDownloader(object): #下载一个url里的数据 def download(self,url): if url is None: return None response=urllib.request.urlopen(url)#注意py2和py3不同 if response.getcode()!=200:#状态码200表示获取成功 return None return response.read()#返回下载好的内容
3.这是网页解析模块 html_parser.py
from bs4 import BeautifulSoup import re import urllib.parse #py3中urlparse在urllib中 class HtmlParser(object): #返回新的url集合 def _get_new_urls(self,page_url,soup): new_urls=set() #获取所有的链接,用正则匹配 links=soup.find_all(\'a\',href=re.compile(r"/item/")) for link in links: new_url=link[\'href\']#获取它的链接(不完全) #将不完整的new_url按照page_url的格式拼成完整的 new_full_url=urllib.parse.urljoin(page_url,new_url) new_urls.add(new_full_url) return new_urls #返回对soup的解析结果 def _get_new_data(self,page_url,soup): res_data={} #url res_data[\'url\']=page_url #<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1> #获取词条名(用了两次find) title_node=soup.find(\'dd\',class_="lemmaWgt-lemmaTitle-title").find("h1") #注意这里先split再做join,将\\\\变成了\\ res_data[\'title\']=\'\\\\\'.join(title_node.get_text().split(\'\\\\\\\\\'))#加入字典中 #<div class="lemma-summary"> #获取摘要文字 summary_node=soup.find(\'div\',class_="lemma-summary") #注意这里先split再做join,将\\\\变成了\\ res_data[\'summary\']=\'\\\\\'.join(summary_node.get_text().split(\'\\\\\\\\\'))#加入字典中 return res_data #解析一个下载好的页面的数据,并返回新的url列表和解析结果 def parse(self,page_url,html_cont): if page_url is None or html_cont is None: return #创建一个bs对象(将网页字符串html_cont加载成一棵DOM树) soup=BeautifulSoup(html_cont,\'html.parser\') new_urls=self._get_new_urls(page_url,soup) new_data=self._get_new_data(page_url,soup) return new_urls,new_data
4.下面是网页输出模块 html_outputer.py
class HtmlOutputer(object): def __init__(self): self.datas=[] #收集解析好的数据 def collect_data(self,data): if data is None: return self.datas.append(data) #输出所有收集好的数据 def output_html(self): with open(\'output.html\',\'w\') as fout: fout.write("<html>") \'\'\'fout.write("<head>") fout.write("<meta charset=\\"utf-8\\">") fout.write("</head>")\'\'\' fout.write("<body>") fout.write("<table>") for data in self.datas: fout.write("<tr>") fout.write("<td>%s</td>"%data[\'url\']) fout.write("<td>%s</td>"%data[\'title\']) fout.write("<td>%s</td>"%data[\'summary\'].encode(\'utf-8\')) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</html>") fout.close()
5.主函数,运行这个就可以了
import url_manager,html_downloader,html_parser,html_outputer class SpiderMain(object): def __init__(self):#在构造器中初始化所需要的对象 self.urls=url_manager.UrlManager()#url管理器 self.downloader=html_downloader.HtmlDownloader()#下载器 self.parser=html_parser.HtmlParser()#解析器 self.outputer=html_outputer.HtmlOutputer()#价值数据的输出 def craw(self,root_url): count=1#记录当前爬取的是第几个url self.urls.add_new_url(root_url)#先将入口url给url管理器 #启动爬虫的循环 while self.urls.has_new_url():#如果管理器中还有url try: new_url=self.urls.get_new_url()#就从中获取一个url print (\'craw %d : %s\'%(count,new_url))#打印正在爬的url html_cont=self.downloader.download(new_url)#然后用下载器下载它 #调用解析器去解析这个页面的数据 new_urls,new_data=self.parser.parse(new_url,html_cont) self.urls.add_new_urls(new_urls)#新得到的url补充至url管理器 self.outputer.collect_data(new_data)#收集数据 if count==30:#如果已经爬了30个直接退出 break count+=1 except: print (\'craw failed\')#标记这个url爬取失败 self.outputer.output_html()#循环结束后输出收集好的数据 if __name__=="__main__": root_url="http://baike.baidu.com/item/Python"#入口url obj_spider=SpiderMain() obj_spider.craw(root_url)
以上内容,来自:http://blog.csdn.net/shu15121856/article/details/72903146
以上是关于爬取N个网页,并将其记录的主要内容,如果未能解决你的问题,请参考以下文章
python如何爬取单个网页数据,并将数据保存到相应文件当中