全连接的BP神经网络
Posted tina_ttl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全连接的BP神经网络相关的知识,希望对你有一定的参考价值。
《全连接的BP神经网络》
本文主要描述全连接的BP神经网络的前向传播和误差反向传播,所有的符号都用Ng的Machine learning的习惯。下图给出了某个全连接的神经网络图。
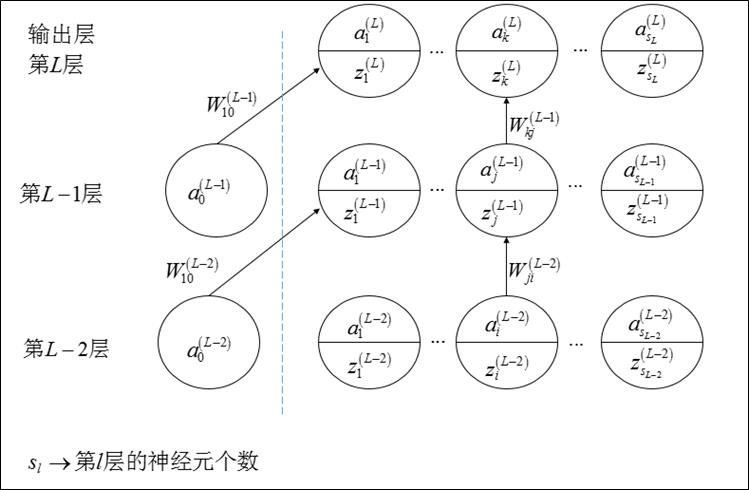
1前向传播
1.1前向传播
分别计算第l层神经元的输入和输出;
1.1.1偏执项为1时
向量整体形式:
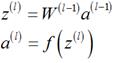
分量形式:
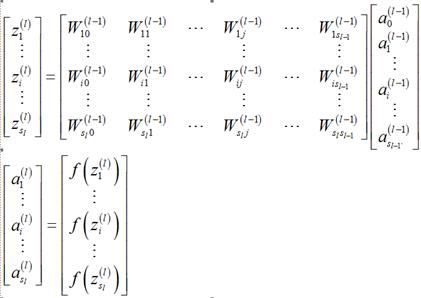
1.1.2偏执项为b时
向量整体形式:
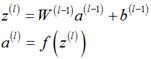
分量形式:
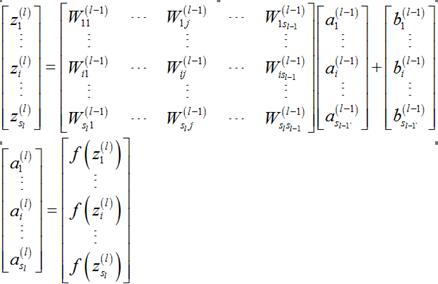
1.2网络误差
1.2.1偏执项为1时
对于某一个输入样本,它的输出为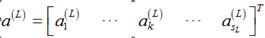 ,它所对应的真实输出应该为
,它所对应的真实输出应该为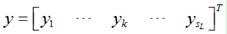 ,那么,该样本对应的误差E为
,那么,该样本对应的误差E为
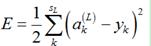 (1)
(1)
注意到输出层的第k个神经元的输出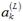 可以计算如下:
可以计算如下:
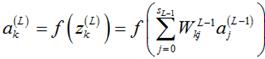 (2)
(2)
那么,误差E可以展开至隐藏层(第L-1层)的形式
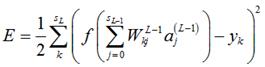 (3)
(3)
又注意到隐藏层(第L-1层)的第j个神经元的输出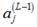 可以计算如下:
可以计算如下:
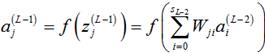 (4)
(4)
那么,误差E进一步展开至隐藏层(第L-2层)
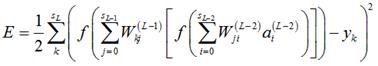 (5)
(5)
可以发现,E是权值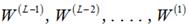 的函数。
的函数。
1.2.2偏执项为b时
对于某一个输入样本,它的输出为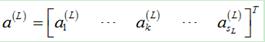 ,它所对应的真实输出应该为
,它所对应的真实输出应该为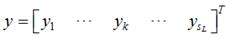 ,那么,该样本对应的误差E为
,那么,该样本对应的误差E为
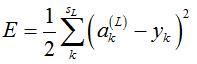 (6)
(6)
注意到输出层的第k个神经元的输出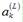 可以计算如下:
可以计算如下:
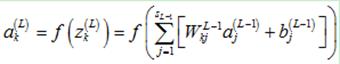 (7)
(7)
那么,误差E可以展开至隐藏层(第L-1层)的形式
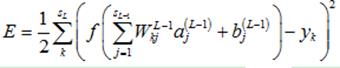 (8)
(8)
又注意到隐藏层(第L-1层)的第j个神经元的输出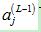 可以计算如下:
可以计算如下:
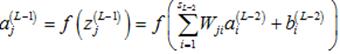 (9)
(9)
那么,误差E进一步展开至隐藏层(第L-2层)
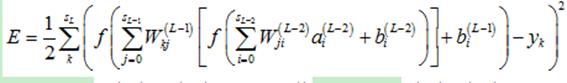 (10)
(10)
可以发现,E是权值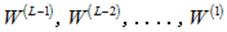 和偏执项
和偏执项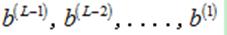 的函数。
的函数。
2误差反向传播中的敏感度
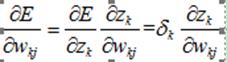
某一层的敏感度的定义为:网络的误差对该层的输入的偏导数,即
2.1偏执项为1时的敏感度
2.1.1输出层的敏感度
输出层(第L层)的第k个神经元的敏感度定义如下:
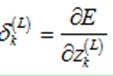
为了计算该敏感度,利用链式法则,引入中间变量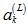 (第L层的第k个神经元的输出):
(第L层的第k个神经元的输出):
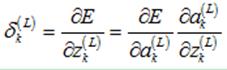 (11)
(11)
首先,计算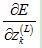 :
:
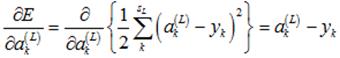
然后,计算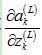 :
:
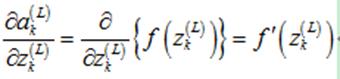
这里的f为sigmoid函数,有: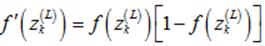
从而可以得到:
 (12)
(12)
那么,第L层的所有神经元的敏感度为:
 (13)
(13)
2.1.2其他层
计算第L-1层的第j个神经元的敏感度,定义如下:
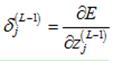
为了计算该敏感度,利用链式法则,引入中间变量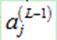 (第L-1层的第j个神经元的输出):
(第L-1层的第j个神经元的输出):
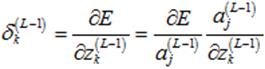 (14)
(14)
首先,计算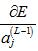 :
:
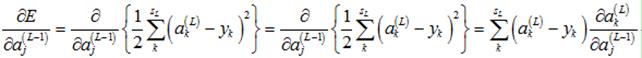
其中: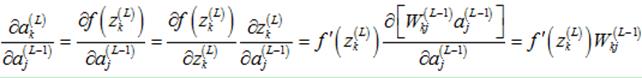
则有: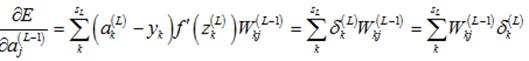
然后,计算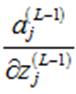 :
:
从而可以得到:
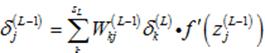 (15)
(15)
其中: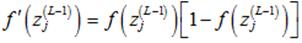
那么,第L-1层的所有神经元的敏感度为
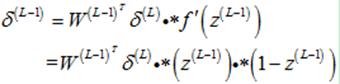 (16)
(16)
以上推导是由第L层的敏感度计算第L-1层的敏感度,那么,利用递推方法可以得到第l层的敏感度的计算方法(l=L-1,…,2):
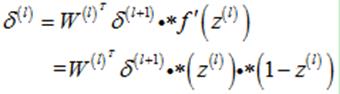 (17)
(17)
2.2偏执项为b时的敏感度
推导过程中,只有一处发生改变,即隐藏层的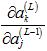 计算式发生如下改变,但结果并没有改变,所以不会对最终的敏感度的计算公式造成影响:
计算式发生如下改变,但结果并没有改变,所以不会对最终的敏感度的计算公式造成影响:
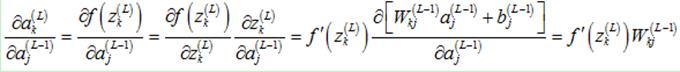
3梯度的计算
3.1单个样本(偏执项为1时)的梯度
此时的待优化参数只有权值矩阵中的元素,计算误差E对第l层的权值矩阵的偏导数:
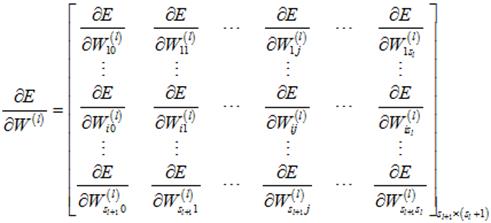
对于其中的某一个元素,计算如下:
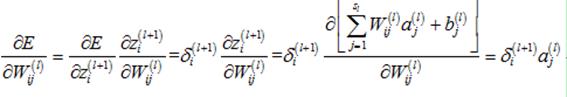
那么,整个求导矩阵计算如下:
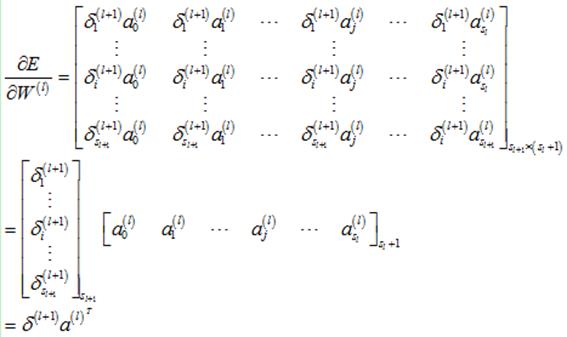
即: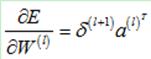
3.2单个样本(偏执项为b时)的梯度
此时的待优化参数为权值矩阵中的元素和偏执项b;
首先计算误差E对第l层的权值矩阵的偏导数:
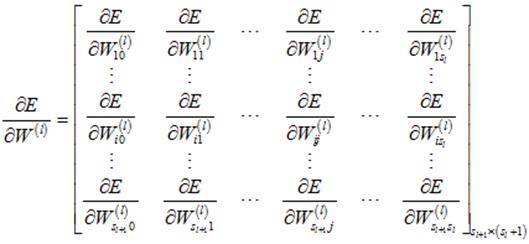
对于其中的某一个元素,计算如下:
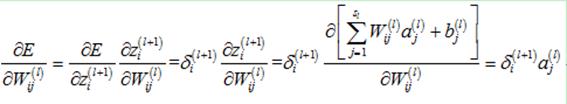
那么,整个求导矩阵计算如下:
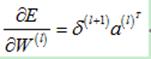
接下来,计算误差E对第l层的偏执项矩阵的偏导数:
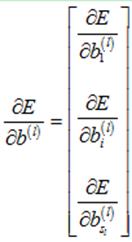
对于其中的某一个元素,计算如下:
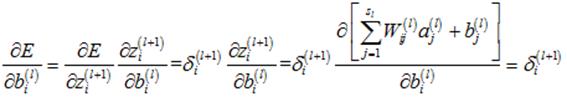
所以,整个偏执项求得到计算如下:
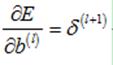
3.3m个样本的梯度求解(未加入其他惩罚项)
如前所述,对于单个样本而言,它的代价函数为E,现在有m个训练样本,它的代价函数应该为所有样本的代价函数的均值,用Ei表示第i个训练样本的代价函数(也就是前文一直使用的代价函数),E表示所有样本的代价函数,则它们有如下关系:
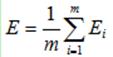
则有:
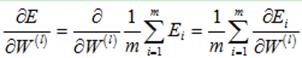 (18)
(18)
如果有偏执项b的话,则有
 (19)
(19)
如果有m个样本,前面计算所得得到的 和
和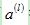 都是矩阵,它们的每一列是每个样本对应的第l层的敏感度和输出值。那么,可以按照如下方式计算m个样本所对应的梯度值:
都是矩阵,它们的每一列是每个样本对应的第l层的敏感度和输出值。那么,可以按照如下方式计算m个样本所对应的梯度值:
(1)偏执项为1
 (20)
(20)
(2)偏执项为b
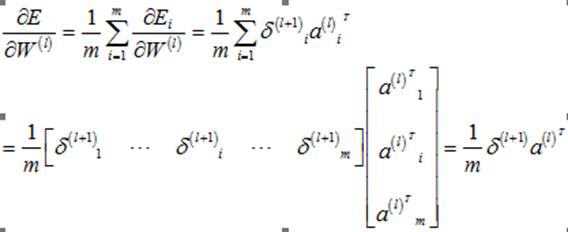 (21)
(21)
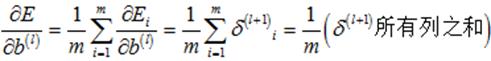 (22)
(22)
4加了正则化项和稀疏项后
4.1网络误差
加入了正则化项和稀疏项后的网络误差计算公式如下:
 (23)
(23)
其中:

J1、J2和J3的计算方法分别如下:
 第k个隐藏层中j个神经元的相对熵
第k个隐藏层中j个神经元的相对熵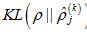 的计算公式如下:
的计算公式如下:
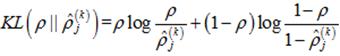 (24)
(24)
其中: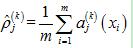 ,
,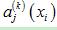 为第k个隐藏层中j个神经元相对于第i个输入样本的激励值,而
为第k个隐藏层中j个神经元相对于第i个输入样本的激励值,而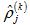 为第k个隐藏层中j个神经元相对于所有输入样本激励值的均值。
为第k个隐藏层中j个神经元相对于所有输入样本激励值的均值。
4.2网络代价函数的偏导数
网络代价函数的偏导数:
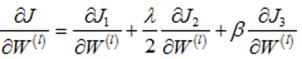
其中:
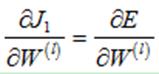
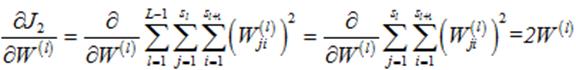
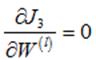
(1)偏执项为1时
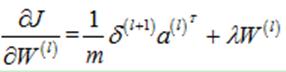 (25)
(25)
(2)偏执项为b时
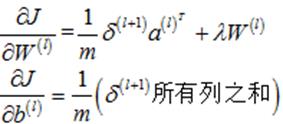 (26)
(26)
4.3敏感度的计算
加入了权值惩罚项和稀疏项后,输出层的敏感度计算不发生变化,而其余各层的敏感度公式变为如下:
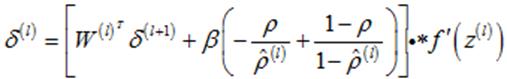 (27)
(27)
5计算流程
-
利用前向传播算法计算各层的激励值

-
计算整个网络的代价函数
利用式 (23)

-
利用反向传播算法计算各层的敏感度

-
计算代价函数对权值矩阵和偏执项的梯度
利用式(26)计算代价函数对权值矩阵和偏执项的梯度

以上是关于全连接的BP神经网络的主要内容,如果未能解决你的问题,请参考以下文章