进程内存和内存损坏
Posted HacTF
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进程内存和内存损坏相关的知识,希望对你有一定的参考价值。
本教程的这一部分的先决条件是对ARM汇编的基本了解(在第一个教程系列“ ARM汇编基础 ”中有介绍)。在本章中,您将了解32位Linux环境中进程的内存布局。之后,您将学习堆栈和堆相关的内存损坏的基本原理,以及它们在调试器中的样子。
- 缓冲区溢出
- 堆栈溢出
- 堆溢出
- 摇摇欲坠的指针
- 格式字符串
本教程中使用的示例是在ARMv6 32位处理器上编译的。如果您无法访问ARM设备,则可以按照以下教程创建自己的实验室并在VM中模拟Raspberry Pi发行版:使用QEMU模拟Raspberry Pi。此处使用的调试器是具有GEF(GDB增强功能)的GDB。如果您对这些工具不熟悉,可以查看本教程:使用GDB和GEF进行调试。
每次我们启动一个程序,该程序的内存区域都被保留。这个地区然后分裂成多个地区。这些地区然后分裂成更多地区(细分市场),但我们将坚持总体概述。所以,我们感兴趣的部分是:
- 程序图像
- 堆
- 堆
在下面的图片中,我们可以看到这些部分是如何在流程内存中进行布置的一般表示。用于指定内存区域的地址仅仅是为了举例,因为它们会因环境而异,特别是在使用ASLR时。
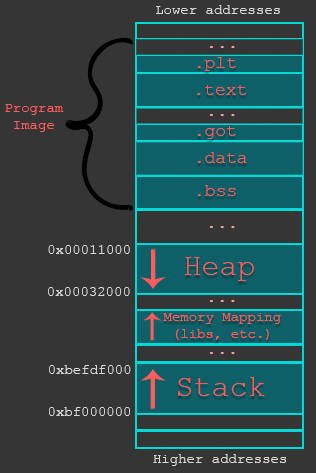 程序图像区域基本上保存了程序的可执行文件,该文件被加载到内存中。这个内存区域可以分成不同的部分:.plt,.text,.got,.data,.bss等等。这些是最相关的。例如,.text包含程序的可执行部分以及所有程序集指令,.data和.bss包含应用程序中使用的变量的变量或指针,.plt和.got存储指向各种导入函数的特定指针,for例如,共享库。从安全角度来看,如果攻击者可能影响.text部分的完整性(重写),他可以执行任意代码。同样,程序链接表(.plt)和全局偏移表(.got)的损坏可能会在特定情况下导致执行任意代码。
程序图像区域基本上保存了程序的可执行文件,该文件被加载到内存中。这个内存区域可以分成不同的部分:.plt,.text,.got,.data,.bss等等。这些是最相关的。例如,.text包含程序的可执行部分以及所有程序集指令,.data和.bss包含应用程序中使用的变量的变量或指针,.plt和.got存储指向各种导入函数的特定指针,for例如,共享库。从安全角度来看,如果攻击者可能影响.text部分的完整性(重写),他可以执行任意代码。同样,程序链接表(.plt)和全局偏移表(.got)的损坏可能会在特定情况下导致执行任意代码。
的栈和堆区域是由应用程序使用来存储和对被该程序的执行期间使用的临时数据(变量)进行操作。攻击者通常会利用这些区域,因为堆栈和堆区域中的数据通常可以通过用户的输入进行修改,如果处理不当,可能会导致内存损坏。我们将在本章后面介绍这种情况。
除了内存的映射之外,我们需要知道与不同内存区域相关的属性。内存区域可以具有以下属性中的一个或组合:R ead,W rite,e X ecute。该读取属性允许程序从一个特定区域读取数据。同样,Write允许程序将数据写入特定的内存区域,并执行 - 执行该内存区域中的指令。我们可以看到GEF中的进程内存区域(强烈推荐的GDB扩展),如下所示:
azeria @ labs:?/ exp $ gdb程序 ... gef> gef config context.layout“code” gef> break main 断点1在0x104c4:文件program.c,第6行。 gef>运行 ... gef> nexti 2 -------------------------------------------------- --------------------------------------- [code:arm] ---- ... 0x104c4 <main + 20> mov r0,#8 0x104c8 <main + 24> bl 0x1034c <malloc @ plt> - > 0x104cc <main + 28> mov r3,r0 0x104d0 <主+ 32> str r3,[r11,#-8] ... gef> vmmap 开始 结束 偏移 Perm路径 0x00010000 0x00011000 0x00000000 rx / home / azeria / exp / program <---- Program Image 0x00020000 0x00021000 0x00000000 rw- / home / azeria / exp / program <---- Program Image continue ... 0x00021000 0x00042000 0x00000000 rw- [堆] <---- HEAP 0xb6e74000 0xb6f9f000 0x00000000 rx /lib/arm-linux-gnueabihf/libc-2.19.so <----共享库(libc) 0xb6f9f000 0xb6faf000 0x0012b000 --- /lib/arm-linux-gnueabihf/libc-2.19.so <---- libc继续... 0xb6faf000 0xb6fb1000 0x0012b000 r-- /lib/arm-linux-gnueabihf/libc-2.19.so <---- libc继续... 0xb6fb1000 0xb6fb2000 0x0012d000 rw- /lib/arm-linux-gnueabihf/libc-2.19.so <---- libc继续... 0xb6fb2000 0xb6fb5000 0x00000000 rw- 0xb6fcc000 0xb6fec000 0x00000000 rx /lib/arm-linux-gnueabihf/ld-2.19.so <----共享库(ld) 0xb6ffa000 0xb6ffb000 0x00000000 rw- 0xb6ffb000 0xb6ffc000 0x0001f000 r-- /lib/arm-linux-gnueabihf/ld-2.19.so <---- ld继续... 0xb6ffc000 0xb6ffd000 0x00020000 rw- /lib/arm-linux-gnueabihf/ld-2.19.so <---- ld继续... 0xb6ffd000 0xb6fff000 0x00000000 rw- 0xb6fff000 0xb7000000 0x00000000 rx [sigpage] 0xbefdf000 0xbf000000 0x00000000 rw- [stack] <---- STACK 0xffff0000 0xffff1000 0x00000000 rx [vectors]
vmmap命令输出中的Heap部分仅在使用了一些Heap相关函数后才会出现。在这种情况下,我们看到 正在使用malloc函数在堆区域中创建一个缓冲区。所以如果你想尝试一下这个,你需要调试一个调用malloc的程序(你可以在这个页面找到一些例子,向下滚动或者使用find函数)。
另外,在Linux中,我们可以通过访问特定于进程的“文件”来检查进程的内存布局:
azeria @ labs:?/ exp $ ps aux | grep程序 azeria 31661 12.3 12.1 38680 30756 pts / 0 S + 23:04 0:10 gdb program azeria 31665 0.1 0.2 1712 748 pts / 0 t 23:04 0:00 / home / azeria / exp / program azeria 31670 0.0 0.7 4180 1876 pts / 1 S + 23:05 0:00 grep --color = auto program azeria @ labs:?/ exp $ cat / proc / 31665 / maps 00010000-00011000 r-xp 00000000 08:02 274721 / home / azeria / exp / program 00020000-00021000 rw -p 00000000 08:02 274721 / home / azeria / exp / program 00021000-00042000 rw-p 00000000 00:00 0 [堆] b6e74000-b6f9f000 r-xp 00000000 08:02 132394 /lib/arm-linux-gnueabihf/libc-2.19.so b6f9f000-b6faf000 --- p 0012b000 08:02 132394 /lib/arm-linux-gnueabihf/libc-2.19.so b6faf000-b6fb1000 r - p 0012b000 08:02 132394 /lib/arm-linux-gnueabihf/libc-2.19.so b6fb1000-b6fb2000 rw-p 0012d000 08:02 132394 /lib/arm-linux-gnueabihf/libc-2.19.so b6fb2000-b6fb5000 rw-p 00000000 00:00 0 b6fcc000-b6fec000 r-xp 00000000 08:02 132358 /lib/arm-linux-gnueabihf/ld-2.19.so b6ffa000-b6ffb000 rw-p 00000000 00:00 0 b6ffb000-b6ffc000 r - p 0001f000 08:02 132358 /lib/arm-linux-gnueabihf/ld-2.19.so b6ffc000-b6ffd000 rw-p 00020000 08:02 132358 /lib/arm-linux-gnueabihf/ld-2.19.so b6ffd000-b6fff000 rw-p 00000000 00:00 0 b6fff000-b7000000 r-xp 00000000 00:00 0 [sigpage] befdf000-bf000000 rw-p 00000000 00:00 0 [stack] ffff0000-ffff1000 r-xp 00000000 00:00 0 [矢量]
大多数程序都是以使用共享库的方式进行编译的。这些库不是程序映像的一部分(即使可以通过静态链接包含它们 ),因此必须动态引用(包含)。因此,我们看到库(libc,ld等)被加载到进程的内存布局中。粗略地说,共享库被加载到内存的某处(在进程的控制之外),我们的程序只是创建虚拟的“链接”到那个内存区域。这样我们可以节省内存,而无需在程序的每个实例中加载相同的库。
内存损坏是一种软件错误类型,允许以程序员不想要的方式修改内存。在大多数情况下,这个条件可以被利用来执行任意代码,禁用安全机制等。这是通过制作和注入有效负载来完成的,该有效负载改变正在运行的程序的某些存储器部分。以下列表包含最常见的内存损坏类型/漏洞:
- 缓冲区溢出
- 堆栈溢出
- 堆溢出
- 悬挂指针(免费使用)
- 格式字符串
在本章中,我们将尝试熟悉缓冲区溢出内存损坏漏洞的基础知识(其余部分将在下一章中介绍)。在我们将要讨论的例子中,我们将会看到,内存损坏漏洞的主要原因是用户输入验证不正确,有时还会有一个逻辑缺陷。对于一个程序来说,输入(或者恶意负载)可能以用户名,文件被打开,网络包等形式出现,并且通常会受到用户的影响。如果程序员没有把潜在有害的用户输入的安全措施,目标程序经常会遇到某种内存相关的问题。
缓冲区溢出是最普遍的内存损坏类之一,通常是由于编程错误导致用户提供的数据多于目标变量(缓冲区)的数据量。例如,在使用易受攻击的函数(如get,strcpy,memcpy等)以及用户提供的数据时,会发生这种情况。这些函数不会检查用户数据的长度,这可能会导致写入(溢出)分配的缓冲区。为了更好地理解,我们将研究 基于堆栈和堆的缓冲区溢出的基础知识。
堆栈溢出
正如名称所示,堆栈溢出是影响堆栈的内存破坏。尽管在大多数情况下,堆栈的任意损坏很可能导致程序崩溃,但精心设计的堆栈缓冲区溢出会导致任意代码执行。下图显示了堆栈如何被损坏的抽象概述。
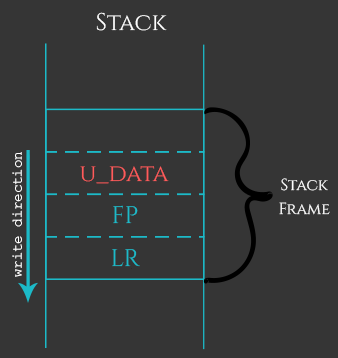
如上图所示,堆栈帧(整个堆栈专用于特定功能的一小部分)可以具有各种组件:用户数据,先前的帧指针,先前的链接寄存器等。如果用户也提供控制变量的大部分数据,FP和LR字段可能会被覆盖。这会中断程序的执行,因为用户破坏了当前函数完成后应用程序将返回/跳转的地址。
为了检查它在实践中的样子,我们可以使用这个例子:
/ * azeria @ labs:?/ exp $ gcc stack.c -o stack * / #include“stdio.h” int main(int argc,char ** argv) { 字符缓冲区[8]; 得到(缓冲液); }
我们的示例程序使用变量“buffer”,长度为8个字符,并为用户输入一个函数“gets”,它简单地将变量“buffer”的值设置为用户提供的任何输入。这个程序的反汇编代码如下所示:
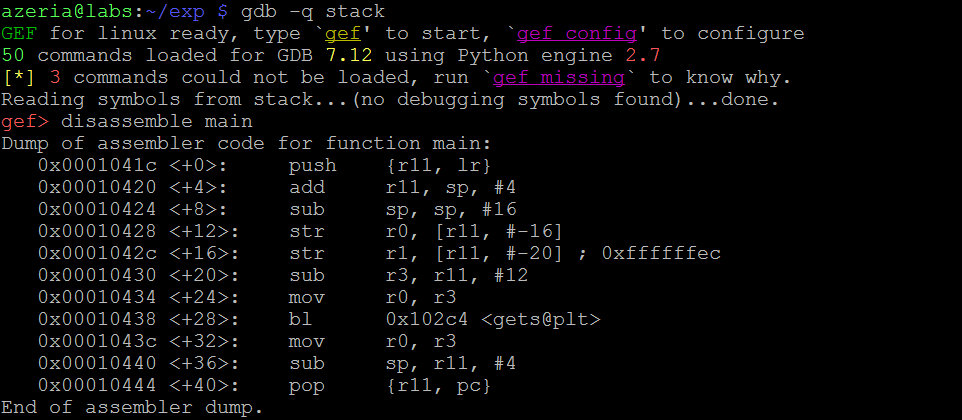
在这里,我们怀疑在“gets”函数完成后,内存损坏可能会发生。为了调查这一点,我们在调用“gets”函数的分支指令之后放置一个断点 - 在我们的例子中,地址为0x0001043c。为了减少噪音,我们配置GEF的布局,只显示代码和堆栈(见下图中的命令)。一旦设置了断点,我们继续执行程序,并提供7个A作为用户的输入(我们使用7个A,因为空字节将被函数“gets”自动附加)。
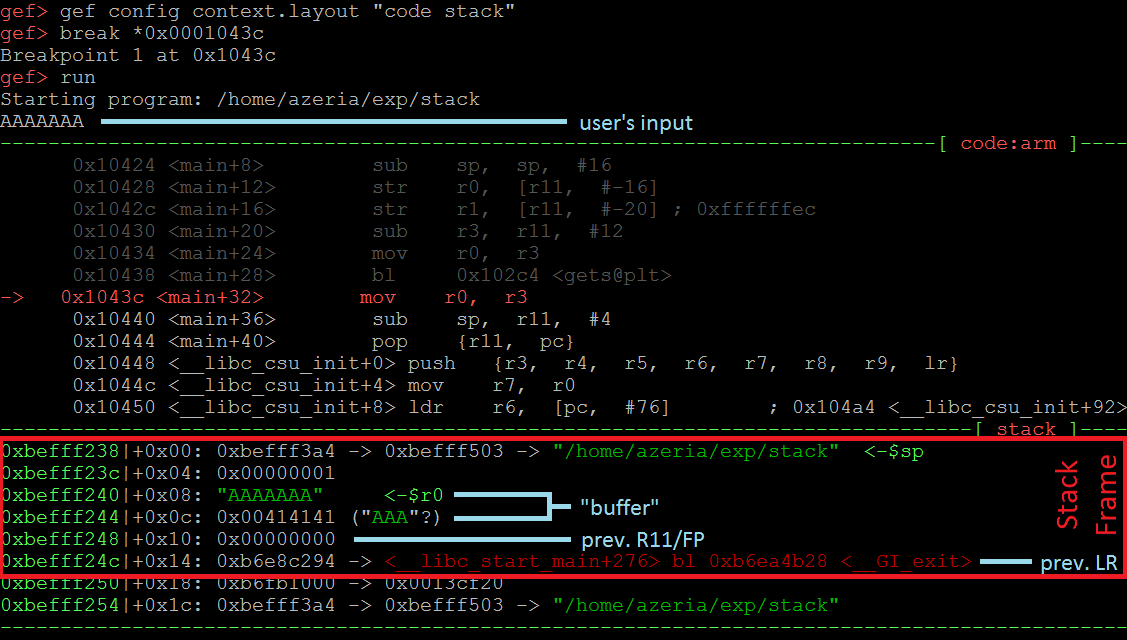
当我们调查我们的例子的堆栈时,我们看到(上图)堆栈帧没有被破坏。这是因为用户提供的输入符合预期的8字节缓冲区,并且堆栈帧中的前一个FP和LR值没有被破坏。现在我们提供16个A,看看会发生什么。
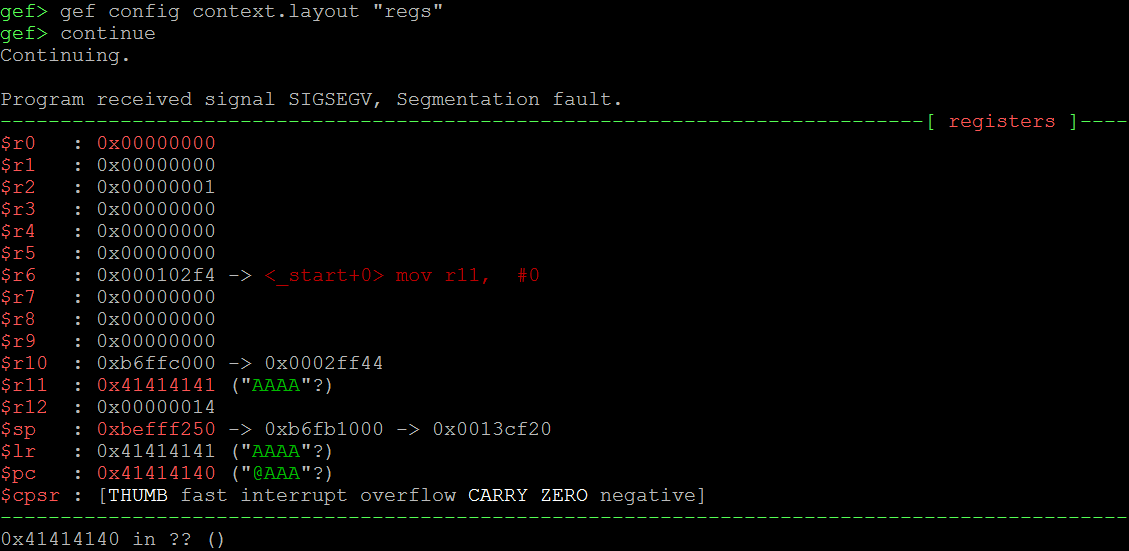
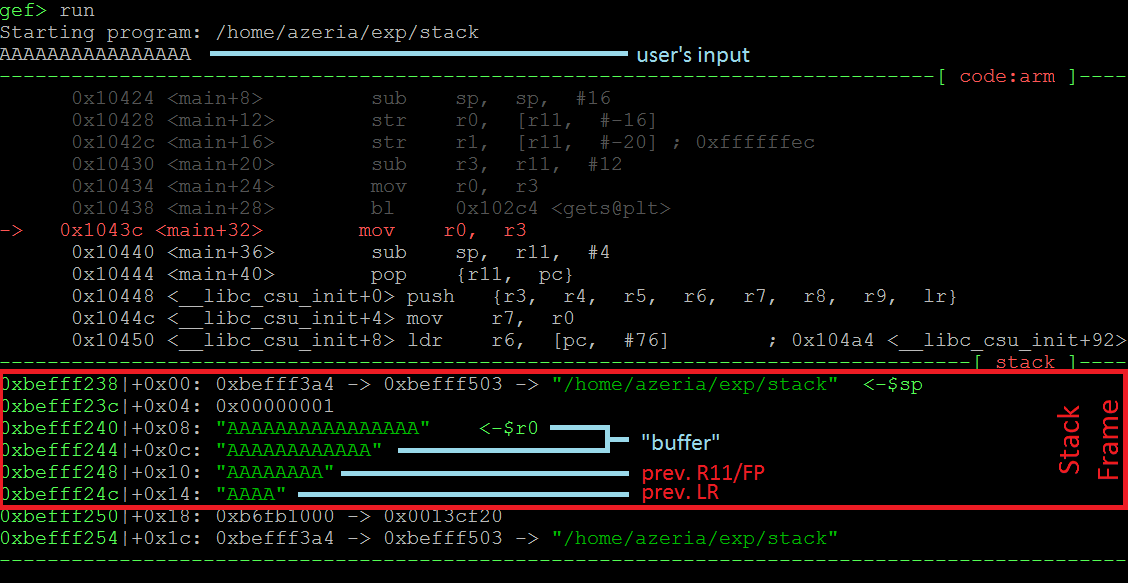 在第二个例子中,我们看到(上图),当我们为函数“gets”提供太多的数据时,它不会停留在目标缓冲区的边界处,而是一直写下“堆栈”。这导致我们以前的FP和LR值被破坏。当我们继续运行程序时,程序崩溃(导致“分段错误”),因为在当前函数的结尾处,FP和LR的先前值被“堆栈”到R11和PC寄存器中,迫使程序跳转到地址0x41414140(由于切换到Thumb模式,最后一个字节自动转换为0x40),在这种情况下,这是非法地址。下面的图片显示了在崩溃时寄存器的值(看看$ pc)。
在第二个例子中,我们看到(上图),当我们为函数“gets”提供太多的数据时,它不会停留在目标缓冲区的边界处,而是一直写下“堆栈”。这导致我们以前的FP和LR值被破坏。当我们继续运行程序时,程序崩溃(导致“分段错误”),因为在当前函数的结尾处,FP和LR的先前值被“堆栈”到R11和PC寄存器中,迫使程序跳转到地址0x41414140(由于切换到Thumb模式,最后一个字节自动转换为0x40),在这种情况下,这是非法地址。下面的图片显示了在崩溃时寄存器的值(看看$ pc)。
堆溢出
首先,堆是一个更复杂的内存位置,主要是因为它的管理方式。为了简单起见,我们坚持这样一个事实,即放在堆内存部分的每个对象都被“打包”成一个包含头部和用户数据(有时用户完全控制)两部分的“块”。在堆的情况下,当用户能够写入比预期更多的数据时,会发生内存损坏。在这种情况下,损坏可能发生在块的边界内(块内堆溢出),或跨两个(或更多)块的边界(块间堆溢出)发生。为了更好地理解,下面我们来看看下面的插图。
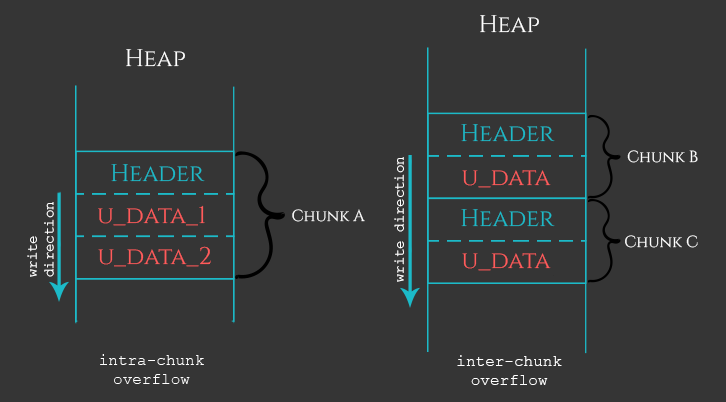
如上图所示,当用户有能力向u_data_1提供更多数据并跨越u_data_1和u_data_2之间的边界时,会发生块内堆溢出。这样当前对象的字段/属性就会被破坏。如果用户提供的数据比当前堆大小可容纳的数据多,则溢出会变成块间并导致相邻块的损坏。
块内堆溢出
为了演示块内堆溢出在实际中的样子,我们可以使用下面的例子,并用“-O”(优化标志)编译它,使其具有更小的(二进制)程序(更易于查看)。
/ * azeria @ labs:?/ exp $ gcc intra_chunk.c -o intra_chunk -O * / #include“stdlib.h” #include“stdio.h” struct u_data //对象模型:名称为8个字节,数字为4个字节 { char name [8]; int数字 }; int main(int argc,char * argv []) { struct u_data * objA = malloc(sizeof(struct u_data)); //在堆中创建对象 objA-> number = 1234; //将我们的对象的数量设置为一个静态值 得到(objA->名); //根据用户的输入设置我们的对象的名字 if(objA-> number == 1234)//检查静态值是否完整 { puts(“Memory valid”); } 否则//在静态值被破坏的情况下继续 { 放(“内存损坏”); } }
上述程序执行以下操作:
- 用两个字段定义数据结构(u_data)
- 创建类型为u_data的对象(在堆内存区域中)
- 将静态值分配给对象的数字字段
- 提示用户为对象的名称字段提供一个值
- 根据数字字段的值打印字符串
所以在这种情况下,我们也怀疑贪污可能发生在“获取”功能之后。我们分解目标程序的主要功能来获取断点的地址。
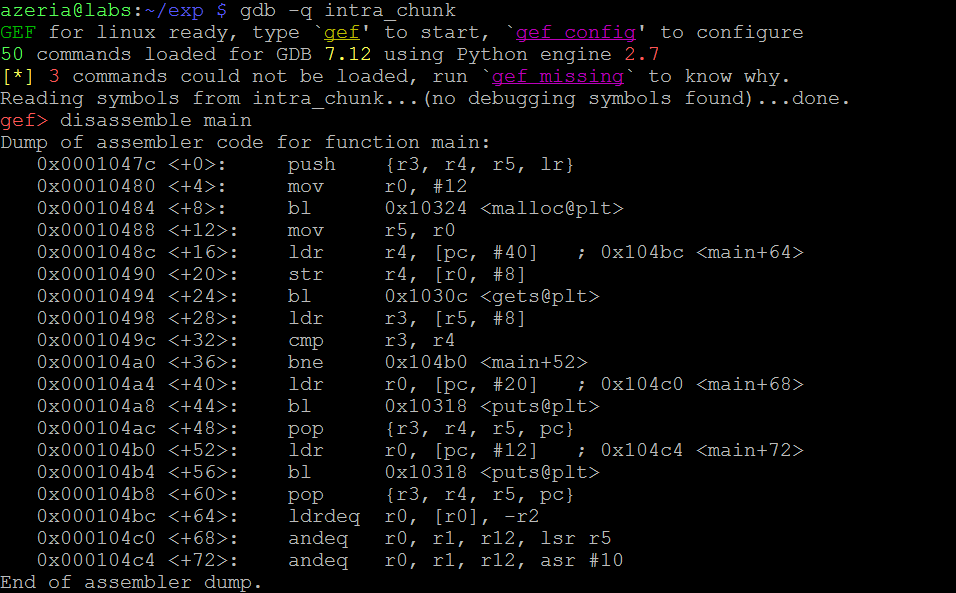
在这种情况下,我们在地址0x00010498处设置断点 - 在函数“gets”完成之后。我们配置GEF只显示我们的代码。然后我们运行该程序并提供7个A作为用户输入。
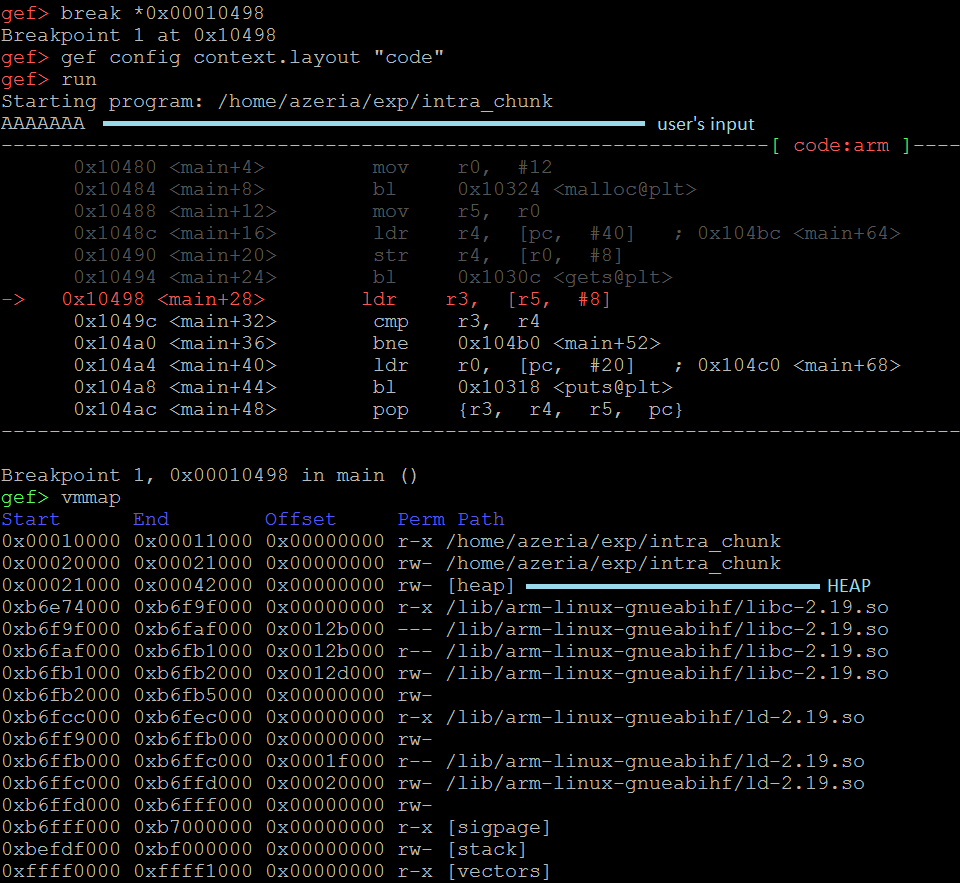
一旦中断点被击中,我们快速查找我们的程序的内存布局,以找到我们的堆是在哪里。我们使用vmmap命令,看到我们的Heap从地址0x00021000开始。考虑到我们的对象(objA)是程序创建的第一个也是唯一的对象,我们将从头开始分析堆。
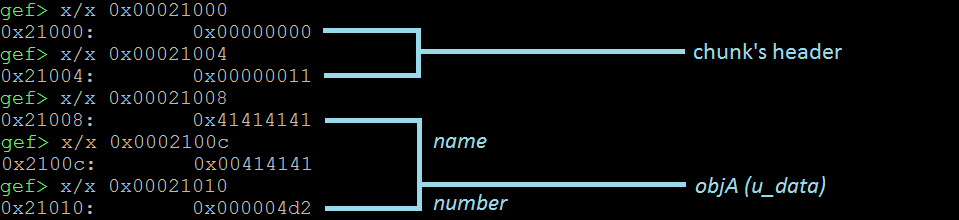
上面的图片向我们展示了与我们的对象相关的Heap块的详细分解。该块有一个头(8字节)和用户的数据部分(12字节)存储我们的对象。我们看到name字段正确存储了提供的7个字符串,以空字节结尾。数字字段存储0x4d2(十进制数1234)。到现在为止还挺好。让我们重复这些步骤,但在这种情况下输入8个A的。
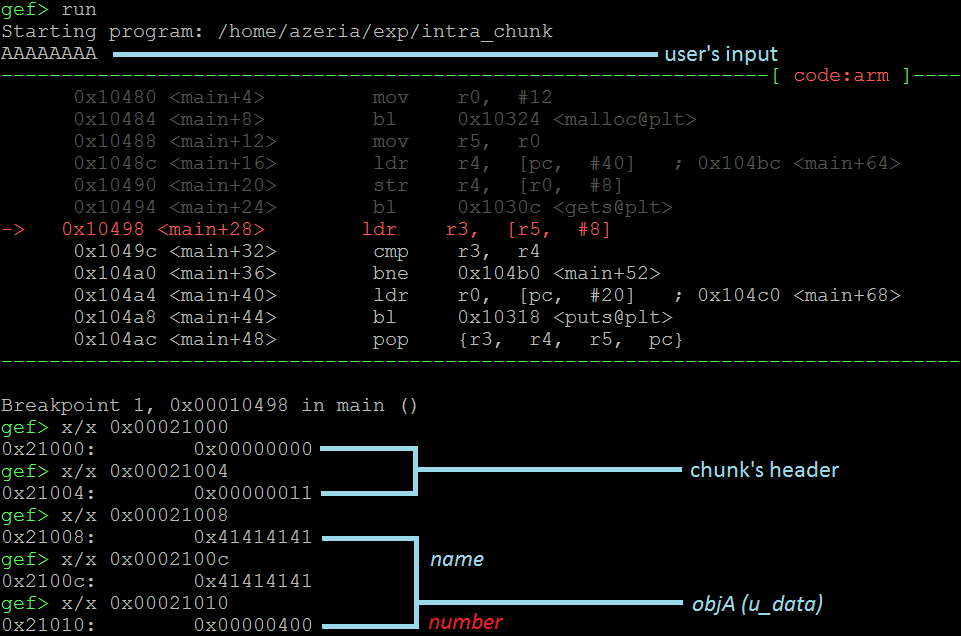
在这次检查堆时,我们看到数字的字段被破坏了(现在等于0x400而不是0x4d2)。空字节终结符覆盖了数字字段的一部分(最后一个字节)。这会导致内部块堆内存损坏。在这种情况下,这种腐败的影响并不是破坏性的,而是可见的。从逻辑上讲,代码中的else语句永远不会达到,因为数字的字段是静态的。但是,我们刚刚观察到的内存损坏使得可能达到这部分代码。这可以通过下面的示例轻松确认。

块间??堆溢出
为了说明在实际中如何实现块间堆溢出,我们可以使用下面的例子,我们现在编译时没有优化标记。
/ * azeria @ labs:?/ exp $ gcc inter_chunk.c -o inter_chunk * / #include“stdlib.h” #include“stdio.h” int main(int argc,char * argv []) { char * some_string = malloc(8); //在堆中创建some_string“对象” int * some_number = malloc(4); //在堆中创建some_number“object” * some_number = 1234; //为some_number分配一个静态值 得到(some_string); //请求用户输入some_string 如果(* some_number == 1234)//检查(some_number的)静态值是否有效 { puts(“Memory valid”); } 否则//在静态some_number被破坏的情况下继续 { 放(“内存损坏”); } }
这里的过程和以前的过程类似:在函数“gets”之后设置一个断点,运行程序,提供7个A,调查Heap。
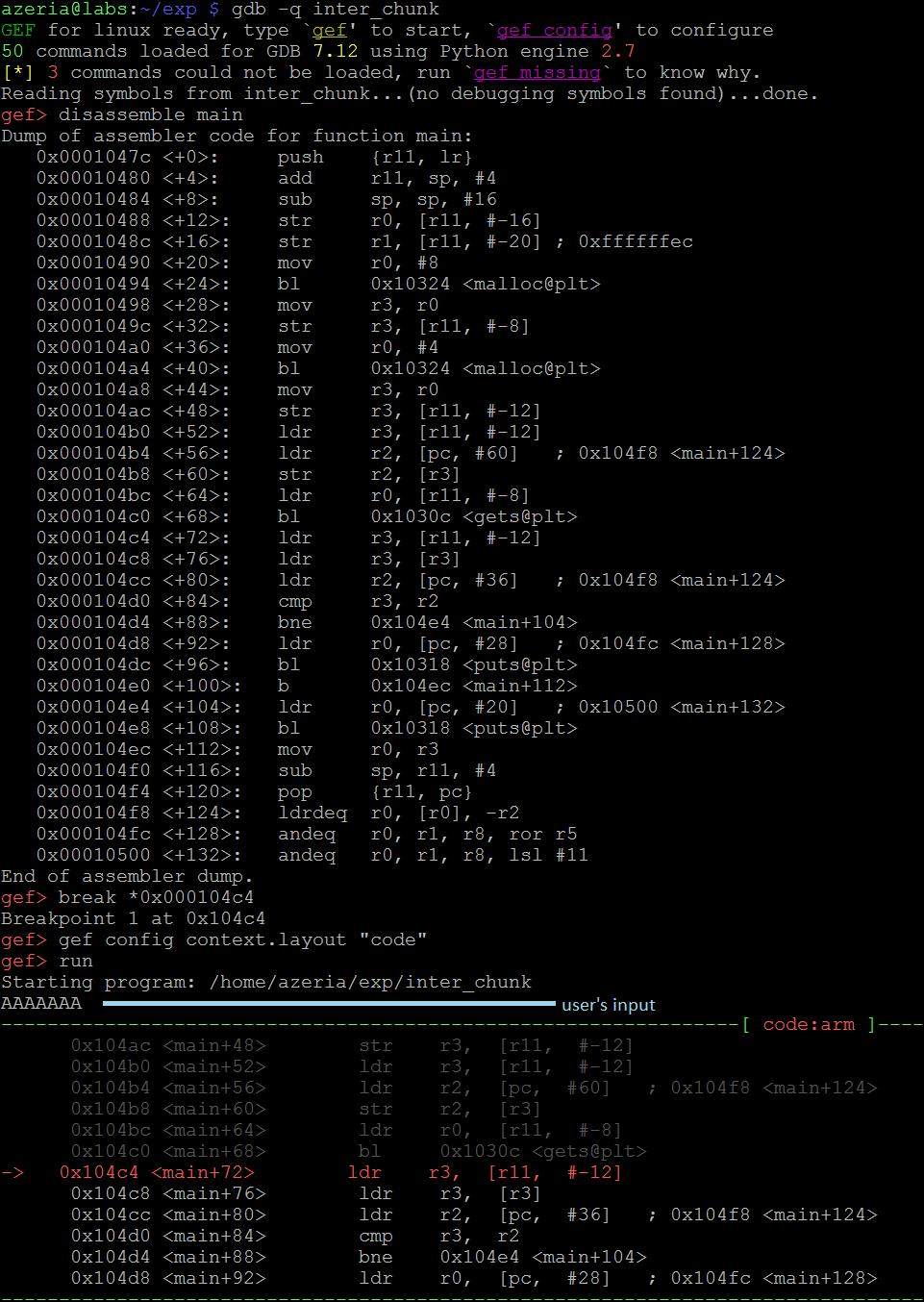
一旦中断点被击中,我们检查堆。在这种情况下,我们有两个块。我们看到(下图),它们的结构是一致的:some_string在其边界内,some_number等于0x4d2。
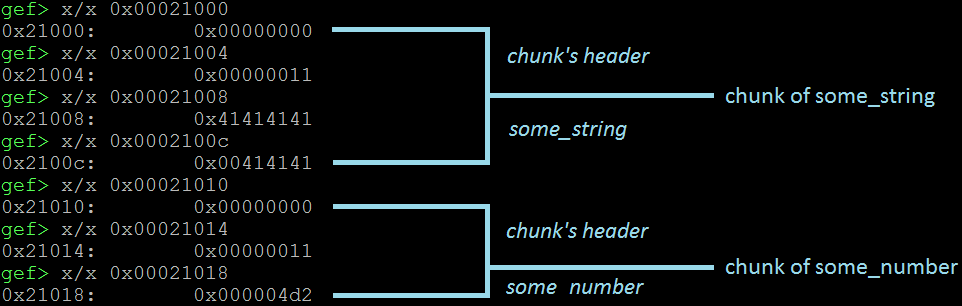
现在,我们提供16个A,看看会发生什么。
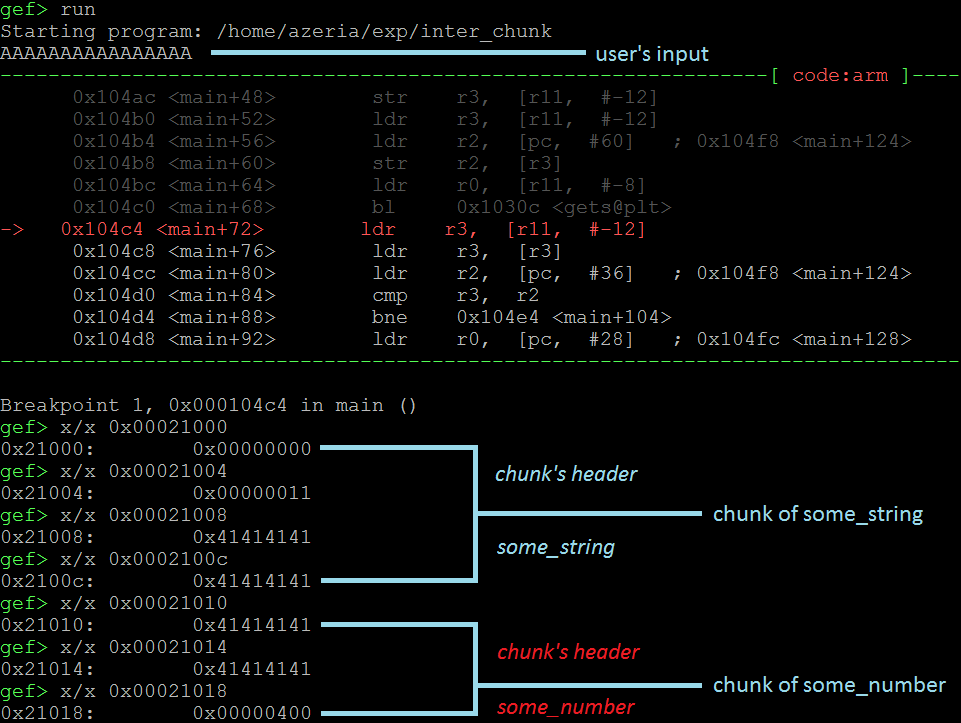
正如您可能已经猜到的那样,提供太多的输入会导致溢出导致相邻块的损坏。在这种情况下,我们看到我们的用户输入损坏了头部和some_number字段的第一个字节。再次,通过破坏some_number我们设法达到逻辑上永远不应该达到的代码部分。

在本教程的这一部分,我们熟悉了进程内存布局以及堆栈和堆相关内存损坏的基础知识。在本教程系列的下一部分,我们将介绍其他内存损坏:悬挂指针和格式字符串。一旦我们覆盖了最常见的内存损坏类型,我们将准备好学习如何编写工作漏洞。
以上是关于进程内存和内存损坏的主要内容,如果未能解决你的问题,请参考以下文章
libtorrent-rasterbar 和 QGuiApplication 导致内存损坏