dfs序和欧拉序
Posted Styx-ferryman
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dfs序和欧拉序相关的知识,希望对你有一定的参考价值。
生命不息,学习不止,昨天学了两个算法,总结一下,然而只是略懂,请路过的大佬多多谅解。
一、dfs序
1、什么是dfs序?
其实完全可以从字面意义上理解,dfs序就是指一棵树被dfs时所经过的节点的顺序
原图来源于网络,并经过灵魂画师xhk的一发魔改。
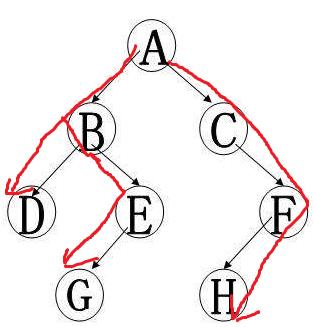
好的,这张图的dfs序显然为A-B-D-E-G-C-F-H
2、dfs序怎么写?
首先你得会写dfs(不会的请先自行学习)
然后我们都知道正常的dfs一般是长这样的(以及博主是只蒟蒻)

我们只需要多一个辅助数组来记录dfs序就行了
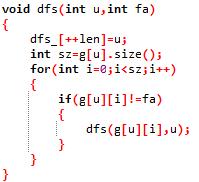
代码:
#include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[100010]; int dfs_[200020],len; void dfs(int u,int fa) { dfs_[++len]=u; int sz=g[u].size(); for(int i=0;i<sz;i++) { if(g[u][i]!=fa) { dfs(g[u][i],u); } } } int main() { int n; scanf("%d",&n); for(int i=1;i<=n;i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); for(int i=1;i<=len;i++) { printf("%d ",dfs_[i]); } printf("\\n"); }
好的,都应该可以理解了吧。
于是问题来了,我们要dfs序有什么用呢?
3、dfs序的用处
这得从dfs的优势来探讨了。
dfs是深度优先的,所以对于一个点,它会先遍历完它的所有子节点,再去遍历他的兄弟节点以及其他
所以对于一棵树的dfs序来说,这个点和他所有的子节点会被存储在连续的区间之中。
仍然是这张图:
原图来源于网络,并经过灵魂画师xhk的一发魔改。
我们都知道它的dfs序是:A-B-D-E-G-C-F-H
然后我们可以发现B字树B-D-E-G,C子树C-F-H都在一段连续的区间中。
那么这有什么好处呢?
比如说现在有一道题:给你一颗树,给出m个x和w,意为将x子树中的所有点加上一个权值w,最后询问所有点的权值
既然dfs序中x和他的所有子节点都在连续的区间上,那么我们就可以将它简化成差分的问题。
比如说给b节点加2,就可以简化为给b的差分数组+2,c的差分数组-2
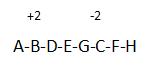
也就是说我们只需要找到第一个不包括在B的子树的位置减掉2,到时候还原回前缀和就可以求解了。
是不是很简单?
那么问题来了,我们怎么找第一个不在B子树中的点?
这里,需要引进一个新的东西
4、时间戳
时间戳也很好理解,它就好比一个标签,贴在每一个点上,记录dfs第一次开始访问这个点的时间以及最后结束访问的时间。
所以它还是和dfs结合的

不过需要注意,dfs序和1-n是不一样的
所以可千万不要像博主一样傻傻地用s[i]来表示点i的起始时间!
那么怎么保存呢?反正博主比较愚昧,只想到用另一个数组来记录一下(这就是博主自带大常数和大空间的原因)
于是变成了这样
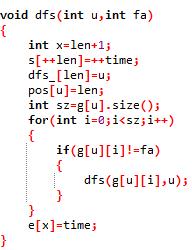
好的,那么知道了起始时间和终结时间以后我们该怎么用呢?
因为搜索进下一个点时时间增加,且结束时间逐级传递。
所以说我们的点的子节点的时间区间一定包含在这个点的时间区间内。
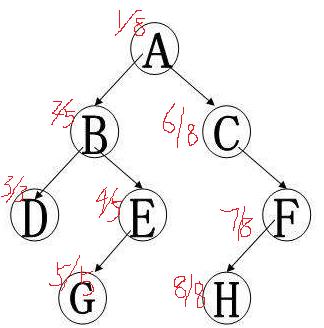

所以如果一个点的起始时间和终结时间被另一个点包括,这个点肯定是另一个点的子节点。(算导里称之为括号化定理)
因此可以判断一个点是否是另一个点的子节点。
代码:
#include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[100010]; int dfs_[200020],len,time,s[200020],e[200020],pos[200020]; void dfs(int u,int fa) { int x=len+1; s[++len]=++time; dfs_[len]=u; pos[u]=len; int sz=g[u].size(); for(int i=0;i<sz;i++) { if(g[u][i]!=fa) { dfs(g[u][i],u); } } e[x]=time; } int main() { int n,m; scanf("%d %d",&n,&m); for(int i=1;i<=n;i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); for(int i=1;i<=m;i++) { int x,y; scanf("%d%d",&x,&y); x=pos[x]; y=pos[y]; if(s[x]<=s[y]&&e[y]<=e[x]) { printf("YES\\n"); } else { printf("NO\\n"); } } }
至于如何让找出第一个?
还是上面那张图,设如果是B的子节点就为1,否则0

嗯,这玩意好像可以二分呢!
于是乎就做好了!log(n)的修改,似乎还挺可做的!
好吧假装代码是这样的:
#include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[100010]; int dfs_[200020],len,time,s[200020],e[200020],pos[200020],a[200020],b[200020],sub[200020]; void dfs(int u,int fa) { int x=len+1; s[++len]=++time; dfs_[len]=u; b[len]=a[u]; pos[u]=len; int sz=g[u].size(); for(int i=0;i<sz;i++) { if(g[u][i]!=fa) { dfs(g[u][i],u); } } e[x]=time; } int main() { int n,m,t; scanf("%d %d",&n,&m); for(int i=1;i<=n;i++) { scanf("%d",&a[i]); } for(int i=1;i<=n-1;i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); sub[1]=b[1]; for(int i=2;i<=len;i++) { sub[i]=b[i]-b[i-1]; } for(int i=1;i<=m;i++) { int x,w; scanf("%d%d",&x,&w); x=pos[x]; sub[x]+=w; int l=x,r=a[len]; while(l<r) { int mid=(l+r)>>1; if(s[x]<=s[mid]&&e[mid]<=e[x]) { l=mid+1; } else { r=mid; } } int y=r; sub[y]-=w; } for(int i=1;i<=n;i++) { sub[i]=sub[i-1]+sub[i]; } for(int i=1;i<=n;i++) { int x=pos[i]; printf("%d ",sub[x]); } }
然后还能再优化吗?当然可以,我们只需要记录一下每个点的dfs结束的位置,这样子就不用二分了,怎么写?自己想想吧先╮( ̄▽ ̄)╭,如果你能坚持看完欧拉序,也许你能找到差不多的代码哦~
二、欧拉序
1、什么是欧拉序
就是从根结点出发,按dfs的顺序在绕回原点所经过所有点的顺序
2、欧拉序有怎么写?
(1)dfs到加进,dfs回加进,总共加入度遍。

原图来源于网络,并经过灵魂画师xhk的一发魔改。
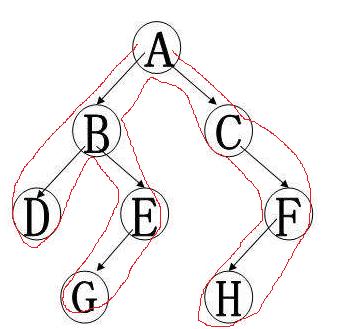
欧拉序1为A-B-D-B-E-G-E-B-A-C-F-H-F-C-A
同时需要一个辅助数组
代码1:
#include<cmath> #include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[40010]; int len,a[80020]; void dfs(int u,int fa) { a[++len]=u; int sz=g[u].size(); for(int i=0; i<sz; i++) { if(g[u][i]!=fa) { dfs(g[u][i],u); a[++len]=u; } } } int main() { int t; scanf("%d",&t); while(t--) { int n,m; len=0; memset(a,0,sizeof(a)); scanf("%d",&n); for(int i=1; i<=n; i++) { g[i].clear(); } for(int i=1; i<=n-1; i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); for(int i=1;i<=len;i++) { printf("%d ",a[i]); } } }
(2)dfs进加进,dfs最后一次回加进,总共加两遍

原图来源于网络,并经过灵魂画师xhk的一发魔改。
欧拉序2为A-B-D-D-E-G-G-E-B-C-F-H-H-F-C-A
代码2:
#include<cmath> #include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[40010]; int len,a[80020]; void dfs(int u,int fa) { a[++len]=u; int sz=g[u].size(); for(int i=0; i<sz; i++) { if(g[u][i]!=fa) dfs(g[u][i],u); } } a[++len]=u; } int main() { int t; scanf("%d",&t); while(t--) { int n,m; len=0; memset(a,0,sizeof(a)); scanf("%d",&n); for(int i=1; i<=n; i++) { g[i].clear(); } for(int i=1; i<=n-1; i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); for(int i=1;i<=len;i++) { printf("%d ",a[i]); } } }
当然还有几种写法,各有长处,不在介绍了就。
好的,那么我们来讲下这几种欧拉序的用处
三、欧拉序的用处
1、求LCA
假设我们使用欧拉序1
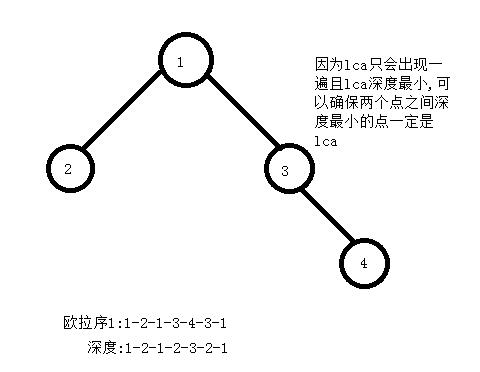
则我们要求的两个点在欧拉序中的第一个位置之间肯定包含他们的lca,因为欧拉序1上任意两点之间肯定包含从第一个点走到第二个点访问的路径上的所有点
所以只需要记录他们的深度,然后从两个询问子节点x,y第一次出现的位置之间的深度最小值即可,可能不大好理解,看张图吧。
代码:
#include<cmath> #include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int > g[40010]; int len,a[80020],dep[80020],pos[80020][17],dp[80020][17],vis[80020],cnt[80020]; void dfs(int u,int fa,int deep) { a[++len]=u; dep[len]=deep+1; if(!vis[u]) { cnt[u]=len; vis[u]=1; } int sz=g[u].size(); for(int i=0; i<sz; i++) { if(g[u][i]!=fa) { dfs(g[u][i],u,deep+1); a[++len]=u; dep[len]=deep+1; } } } int main() { int t; scanf("%d",&t); while(t--) { int n,m; len=0; memset(a,0,sizeof(a)); memset(dep,0,sizeof(dep)); memset(pos,0,sizeof(pos)); memset(dp,0,sizeof(dp)); memset(vis,0,sizeof(vis)); memset(cnt,0,sizeof(cnt)); scanf("%d%d",&n,&m); for(int i=1; i<=n; i++) { g[i].clear(); } for(int i=1; i<=n-1; i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0,0); printf("%d\\n",len); for(int i=1; i<=len; i++) { dp[i][0]=dep[i]; pos[i][0]=i; } for(int j=1; j<=17; j++) { for(int i=1; i<=len; i++) { if(i+(1<<(j-1))>=len) { break; } if(dp[i][j-1]>dp[i+(1<<(j-1))][j-1]) { dp[i][j]=dp[i+(1<<(j-1))][j-1]; pos[i][j]=pos[i+(1<<(j-1))][j-1]; } else { dp[i][j]=dp[i][j-1]; pos[i][j]=pos[i][j-1]; } } } for(int i=1; i<=m; i++) { int x,y; scanf("%d%d",&x,&y); int dx=cnt[x]; int dy=cnt[y]; if(dx>dy) { swap(dx,dy); swap(x,y); } int k=(int)(log((double)(dy-dx+1))/log(2.0)); int p; if(dp[dx][k]>dp[dy-(1<<k)+1][k]) { p=pos[dy-(1<<k)+1][k]; } else { p=pos[dx][k]; } printf("%d\\n",a[p]); } } }
例题:HDU 2586
2、求子树的权值之和
先来道滑稽题:(由于纯属手糊,如有错误,还请谅解)
给你一棵树,告诉你每个点的点权,给你m个x和w,表示将子树x中每个点的权值和加w,然后再给你t个x,表示询问x子树中所有点的权值之和.
样例输入:
7 2 7
6 5 4 2 1 8 7
1 2
2 3
2 4
4 5
1 6
6 7
5 1
3 2
1
2
3
4
5
6
7
样例输出:
36 15 6 4 2 15 7
这道题和dfs序中那道很像不是吗?
好,我们来看欧拉序2,它有什么优点呢?你可以发现,每个点都出现了两遍,而这个点第一次出现和第二次出现的位置之间就是他的所有子孙节点.
ちょっと まで!
有没有发现这就是之前记录结束位置的想法?
只不过这个更具体更好懂呢!
然后同样是差分,只不过差分时我们可以直接通过该点第二次出现的位置+1来获得第一个不是该子树的点,然后,o(1)的修改就实现了.
但是如果这样怎么查询权值和呢?
我们都知道这个点第一次出现的位置和第二次出现的位置之间是他的子树,那么我们只需要维护一遍前缀和,用第二个的位置减第一个的位置前的那个位置,就可以得到权值和了.
不过由于每个子树中的点都被算了两遍,我们要除以二.
代码:
#include<vector> #include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; vector<int> g[100010]; int euler[200020],pos[100010][2],len,a[100010],sub[200020]; void dfs(int u,int fa) { euler[++len]=u; pos[u][0]=len; int sz=g[u].size(); for(int i=0;i<sz;i++) { if(g[u][i]!=fa) { dfs(g[u][i],u); } } euler[++len]=u; pos[u][1]=len; } int main() { int n,m,t; len=0; scanf("%d%d%d",&n,&m,&t); for(int i=1;i<=n;i++) { scanf("%d",&a[i]); } for(int i=1;i<=n-1;i++) { int from,to; scanf("%d%d",&from,&to); g[from].push_back(to); g[to].push_back(from); } dfs(1,0); sub[1]=a[euler[1]]; for(int i=2;i<=len;i++) { sub[i]=a[euler[i]]-a[euler[i-1]]; } for(int i=1;i<=m;i++) { int x,w; scanf("%d %d",&x,&w); sub[pos[x][0]]+=w; sub[pos[x][1]+1]-=w; } for(int i=1;i<=len;i++) { sub[i]=sub[i-1]+sub[i]; } for(int i=1;i<=len;i++) //如果删去维护前缀和的过程,就是查询单个点的权值 { sub[i]=sub[i-1]+sub[i]; } for(int i=1;i<=t;i++) { int x; scanf("%d",&x); printf("%d\\n",(sub[pos[x][1]]-sub[pos[x][0]-1])/2); } }
沉迷学习,无法自拔......
以上是关于dfs序和欧拉序的主要内容,如果未能解决你的问题,请参考以下文章