SLAM中的优化理论
Posted Jessica&jie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SLAM中的优化理论相关的知识,希望对你有一定的参考价值。
一.历史由来
Adjustment computation最早是由geodesy的人搞出来的。19世纪中期的时候,geodetics的学者就开始研究large scale triangulations(大型三角剖分)了。20世纪中期,随着camera和computer的出现,photogrammetry(照相测量法)也开始研究adjustment computation,所以他们给起了个名字叫bundle adjustment。21世纪前后,robotics领域开始兴起SLAM,最早用的recursive bayesian filter(递归贝叶斯滤波),后来把问题搞成个graph然后用least squares方法解。
这些东西归根结底就是Gauss大神“发明”的least squares method(最小二乘法)。当年天文学家Piazzi整天闲得没事看星星,在1801年1月1号早上发现了一个从来没观测到的星星,再接下来的42天里做了19次观测之后这个星星就消失了。当时的天文学家为了确定这玩意到底是什么绞尽了脑汁,这时候Gauss出现了,(最初)只用了3个观察数据,就用least squares算出了这个小行星的轨道,接下来天文学家根据Gauss的预测,也重新发现了这个小行星(虽然有小小的偏差),并将其命名为Ceres,也就是谷神星。Google的ceres-solver就是根据这个来命名的。[ref: How Gauss Determined the Orbit of Ceres]
Bundle adjustment优化的是sum of reprojection error,这是一个(geometric distance)几何距离[为什么要minimize geometric distance可以参考[Hartley00]],可以转换成一个least squares problem, 如果nosie是gaussian的话,那就是一个最大似然估计(maximum likelihood estimator),是这种情况下所能得到的最优解了。 这个reprojection error的公式是非线性的,所以这个least squares problem得用迭代法来求解:般都是用Gauss-Newton 法或者LM算法迭代求解。bundle adjustmen由于是特定的形式,所以可以化成sparse matrix 的形式,这样计算量大大减小了。不论GN,LM,中间都要解一个Ax=b形式的linear system,一般情况下算法的效率就取决于解这个linear system的效率。所以说到底这些nonlinear least squares problem最后也就是解一个linear system。这个linear system你可以直接解,也可以用QR分解,乔姆斯基分解 ,或者奇异值分解法求解来解。
现实中,并不是所有观测过程中的噪声都服从 gaussian noise的(或者可以说几乎没有),遇到有outlier的情况,这些方法非常容易挂掉,这时候就得用到robust statistics里面的robust cost(*cost也可以叫做loss, 统计学那边喜欢叫risk) function了,比较常用的有huber, cauchy等等。
|
[Triggs00] Bundle Adjustment - A Modern Synthesis, Bill Triggs, et al. |
二.Bundle Adjustment到底是什么? http://blog.csdn.net/OptSolution/article/details/64442962
译为光束法平差,或者束调整、捆集调整。
所谓bundle,来源于bundle of light,其本意就是指的光束,这些光束指的是三维空间中的点投影到像平面上的光束,而重投影误差正是利用这些光束来构建的,因此称为光束法,强调光束也正是描述其优化模型是如何建立的。剩下的就是平差,那什么是平差呢?
| 测量平差:由于测量仪器的精度不完善和人为因素及外界条件的影响,测量误差总是不可避免的。为了提高成果的质量,处理好这些测量中存在的误差问题,观测值的个数往往要多于确定未知量所必须观测的个数,也就是要进行多余观测。有了多余观测,势必在观测结果之间产生矛盾,测量平差的目的就在于消除这些矛盾而求得观测量的最可靠结果并评定测量成果的精度。测量平差采用的原理就是“最小二乘法”。 |
[1]BA模型:
BA的本质是一个优化模型,其目的是最小化重投影误差.

看!这些五颜六色的线就是我们讲的光束!那现在就该说下什么叫重投影误差了,重投影也就是指的第二次投影:
重投影误差:指的真实三维空间点在图像平面上的投影(也就是图像上的像素点)和重投影(其实是用我们的计算值得到的虚拟的像素点)的差值, 因为种种原因计算得到的值和实际情况不会完全相符,也就是这个差值不可能恰好为0,此时也就需要将这些差值的和最小化获取最优的相机位姿参数及三维空间点的坐标。 |
[2]BA的数学模型
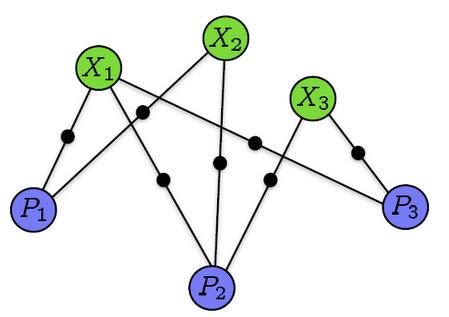
对BA有点了解的同学可能知道BA是一个图优化模型,那首先肯定要构造一个图模型了。既然是图模型那自然就有节点和边了,
这个图模型的节点由相机 和三维空间点构成
和三维空间点构成 构成,如果点投影到相机
构成,如果点投影到相机![]() 的图像上则将这两个节点连接起来。
的图像上则将这两个节点连接起来。
下图所示:

[3]计算---非线性优化
可以使用各种优化算法来进行计算,BA现在基本都是利用LM(Levenberg-Marquardt)算法并在此基础上利用BA模型的稀疏性质来进行计算的,
LM算法是最速下降法(梯度下降法)和Gauss-Newton的结合体。
(1)最速下降法
如果对梯度比较熟悉的话,那应该知道梯度方向是函数上升最快的方向,而此时我们需要解决的问题是让函数最小化。
你应该想到了,那就顺着梯度的负方向去迭代寻找使函数最小的变量值。梯度下降法就是用的这种思想,用数学表达:
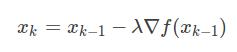
其中λ为步长。最速下降法保证了每次迭代函数都是下降的,在初始点离最优点很远的时候刚开始下降的速度非常快,
但是最速下降法的迭代方向是折线形的导致了收敛非常非常的慢。
(2)Newton型方法
现在先回顾一下中学数学,给定一个开口向上的一元二次函数,如何知道该函数何处最小?这个应该很容易就可以答上来了,对该函数求导,导数为0处就是函数最小处。
Newton型方法也就是这种思想,首先将函数利用泰勒展开到二次项:



(3)Gauss-Newton方法
既然Newton型方法计算Hessian矩阵太困难了,那有没有什么方法可以不计算Hessian矩阵呢?将泰勒展开式的二次项也去掉好像就可以避免求Hessian矩阵了吧,就像这样:


(4)LM(Levenberg-Marquadt)方法

其实LM算法的具体形式就笔者看到的就有很多种,但是本质都是通过参数λ在最速下降法和Gauss-Newton法之间切换。这里选用的是维基百科上的形式。
LM算法就由此保证了每次迭代都是下降的,并且可以快速收敛。
[4]解方程
LM算法主体就是一个方程的求解,也是其计算量最大的部分。当其近似于最速下降法的时候没有什么好讨论的,但是当其近似于Gauss-Newton法的时候,
这个最小二乘解的问题就该好好讨论一下了。以下的讨论就利用Gauss-Newton的形式来求解。
(1)稠密矩阵的最小二乘解

(2)稀疏矩阵的Cholesky分解
稀疏矩阵的话利用其稀疏的性质可以大幅减少计算量,对于稀疏矩阵的Cholesky分解就是这样。其分解形式为一个上三角矩阵的转置乘上自身:
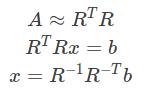
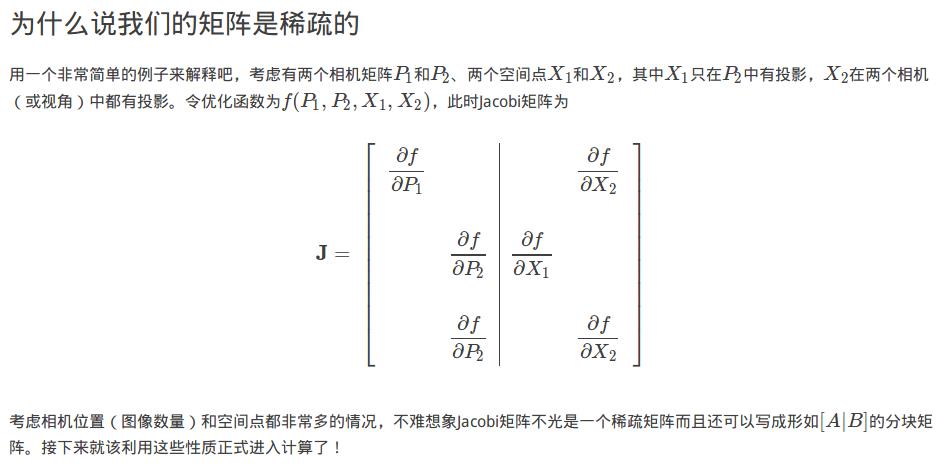
回到Gauss-Newton最后的超定参数方程吧。既然Jacobi矩阵可以分块那我们就先分块,分块可以有效降低需要计算的矩阵的维度并以此减少计算量。
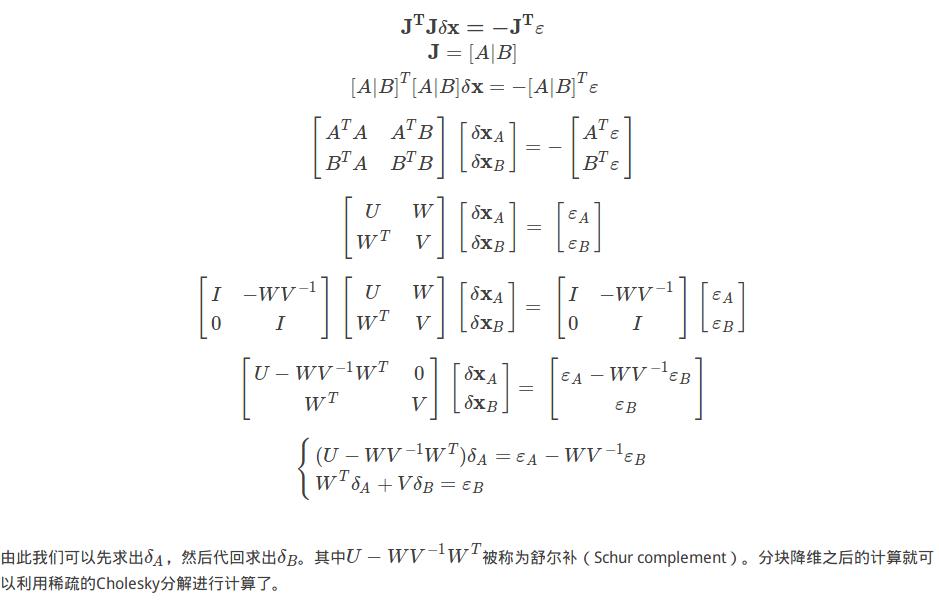
补充:

以上是关于SLAM中的优化理论的主要内容,如果未能解决你的问题,请参考以下文章