HDFS设计之namenode和datanode
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS设计之namenode和datanode相关的知识,希望对你有一定的参考价值。
HDFS 集群节点以master/slave(管理者-工作者模式)运行,namenode就是一个master , 而datanode就是slave 。
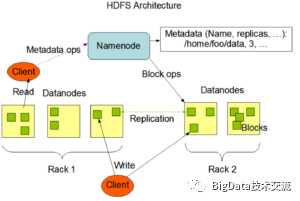
namenode 管理文件系统的命名空间,记录着文件的元数据信息 ,它维护着文件系统树及整颗树内所有文件和目录,这些信息以两个文件的方式永久存储在本地磁盘上:命名空间镜像文件(Namespace image)和编辑日志文件(edit log),namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建。
datanode负责数据的存储和检索,是文件系统的工作节点,受客户端和namenode的调度,并且定期向namenode发送它们所存储的块的列表信息。
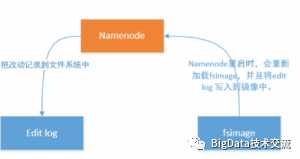
从上面的设计图中,可以得知,Namenode在每次重启时,会将edit log中的信息合并到fsimage 镜像文件中,等于说如果namenode一直不重启,会造成以下三种问题:
1):镜像文件是无法实时得到最新的文件块(block)信息的。
2):一旦namenode挂掉,那么我们的文件系统就无法进行恢复了
3):一般namenode作为master,是不会经常进行重启的,从而导致,一方面edit log 会很大,另一方面如果namenode要重启的话,将会花费很长的时间进行处理镜像操作
当然,对于这些问题,hadoop做了对应的容错措施,在下文HDFS组件之Secondary Namenode中会进行详细的概述。
二 :datanode的设计
datanode负责数据的存储和检索,是文件系统的工作节点,受客户端和namenode的调度,并且定期向namenode发送它们所存储的块的列表信息。
namenode作为hdfs的master,一旦出现故障,那么将会导致所有的文件目录丢失,因为我们不知道如何根据datanode中所存储的block进行重建文件,等同于整个文件系统将无法使用,从而,对于namenode的容错处理是非常重要的,那么为此,Hadoop 也提供了以下两种容错机制
1 :备份系统文件元数据信息文件
Hadoop可以通过配置使namenode在多个文件系统上保存元数据的持久状态,这些写操作是实时同步的,并且是原子操作,一般而言,通过将持久状态写入到本地磁盘的同时在写入到一个远程挂载的网络文件系统中
2 :运行一个辅助namenode节点(Secondary Namenode)
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
以上是关于HDFS设计之namenode和datanode的主要内容,如果未能解决你的问题,请参考以下文章