sparkstreaming
Posted 成长路上的。。。。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sparkstreaming相关的知识,希望对你有一定的参考价值。
流(Streaming),在大数据时代为数据流处理,就像水流一样,是数据流;既然是数据流处理,就会想到数据的流入、数据的加工、数据的流出。
日常工作、生活中数据来源很多不同的地方。例如:工业时代的汽车制造、监控设备、工业设备会产生很多源数据;信息时代的电商网站、日志服务器、社交网络、金融交易系统、黑客攻击、垃圾邮件、交通监控等;通信时代的手机、平板、智能设备、物联网等会产生很多实时数据,数据流无处不在。
在大数据时代Spark Streaming能做什么?
平时用户都有网上购物的经历,用户在网站上进行的各种操作通过Spark Streaming流处理技术可以被监控,用户的购买爱好、关注度、交易等可以进行行为分析。在金融领域,通过Spark Streaming流处理技术可以对交易量很大的账号进行监控,防止罪犯洗钱、财产转移、防欺诈等。在网络安全性方面,黑客攻击时有发生,通过Spark Streaming流处理技术可以将某类可疑IP进行监控并结合机器学习训练模型匹配出当前请求是否属于黑客攻击。其他方面,如:垃圾邮件监控过滤、交通监控、网络监控、工业设备监控的背后都是Spark Streaming发挥强大流处理的地方。
大数据时代,数据价值一般怎么定义?
所有没经过流处理的数据都是无效数据或没有价值的数据;数据产生之后立即处理产生的价值是最大的,数据放置越久或越滞后其使用价值越低。以前绝大多数电商网站盈利走的是网络流量(即用户的访问量),如今,电商网站不仅仅需要关注流量、交易量,更重要的是要通过数据流技术让电商网站的各种数据流动起来,通过实时流动的数据及时分析、挖掘出各种有价值的数据;比如:对不同交易量的用户指定用户画像,从而提供不同服务质量;准对用户访问电商网站板块爱好及时推荐相关的信息。
SparkStreaming VS Hadoop MR:
Spark Streaming是一个准实时流处理框架,而Hadoop MR是一个离线、批处理框架;很显然,在数据的价值性角度,Spark Streaming完胜于Hadoop MR。
SparkStreaming VS Storm:
Spark Streaming是一个准实时流处理框架,处理响应时间一般以分钟为单位,也就是说处理实时数据的延迟时间是秒级别的;Storm是一个实时流处理框架,处理响应是毫秒级的。所以在流框架选型方面要看具体业务场景。需要澄清的是现在很多人认为Spark Streaming流处理运行不稳定、数据丢失、事务性支持不好等等,那是因为很多人不会驾驭Spark Streaming及Spark本身。在Spark Streaming流处理的延迟时间方面,Spark定制版本,会将Spark Streaming的延迟从秒级别推进到100毫秒之内甚至更少。
SparkStreaming优点:
1、提供了丰富的API,企业中能快速实现各种复杂的业务逻辑。
2、流入Spark Streaming的数据流通过和机器学习算法结合,完成机器模拟和图计算。
3、Spark Streaming基于Spark优秀的血统。
SparkStreaming能不能像Storm一样,一条一条处理数据?
Storm处理数据的方式是以条为单位来一条一条处理的,而Spark Streaming基于单位时间处理数据的,SparkStreaming能不能像Storm一样呢?答案是:可以的。
业界一般的做法是Spark Streaming和Kafka搭档即可达到这种效果,入下图:
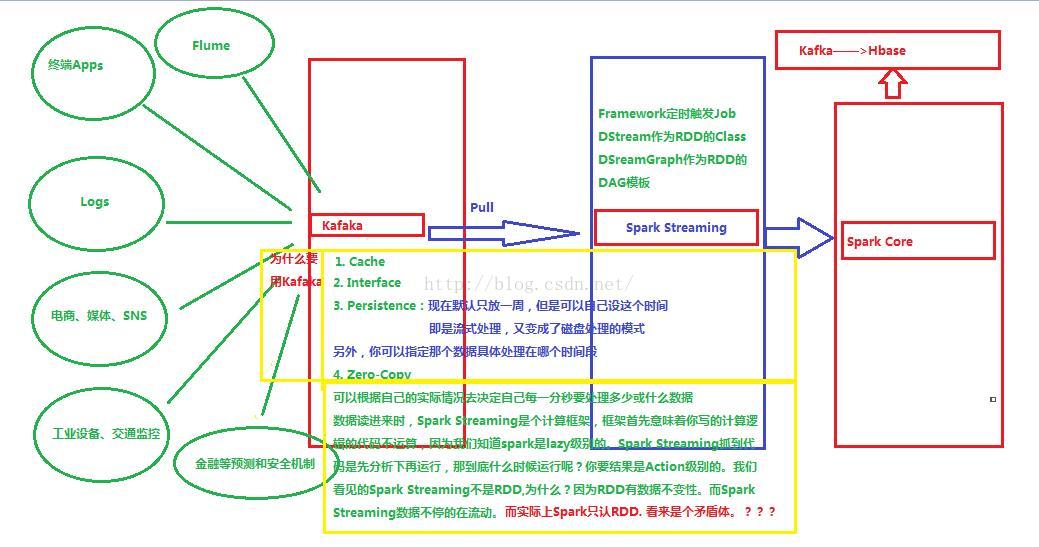
Kafka业界认同最主流的分布式消息框架,此框架即符合消息广播模式又符合消息队列模式。
Kafka内部使用的技术:
1、 Cache
2、 Interface
3、 Persistence(默认最大持久化一周)
4、 Zero-Copy技术让Kafka每秒吞吐量几百兆,而且数据只需要加载一次到内核提供其他应用程序使用
外部各种源数据推进(Push)Kafka,然后再通过Spark Streaming抓取(Pull)数据,抓取的数据量可以根据自己的实际情况确定每一秒中要处理多少数据。
通过Spark Streaming动手实战wordCount实例
这里是运行一个Spark Streaming的程序:统计这个时间段内流进来的单词出现的次数. 它计算的是:他规定的时间段内每个单词出现了多少次。
1、先启动下Spark集群:

我们从集群里面打开下官方网站


接受这个数据进行加工,就是流处理的过程,刚才那个WordCount就是以1s做一个单位。
刚才运行的时候,为什么没有结果呢?因为需要数据源。
2、获取数据源:
新开一个命令终端,然后输入:
$ nc -lk 9999
现在我们拷贝数据源进入运行:
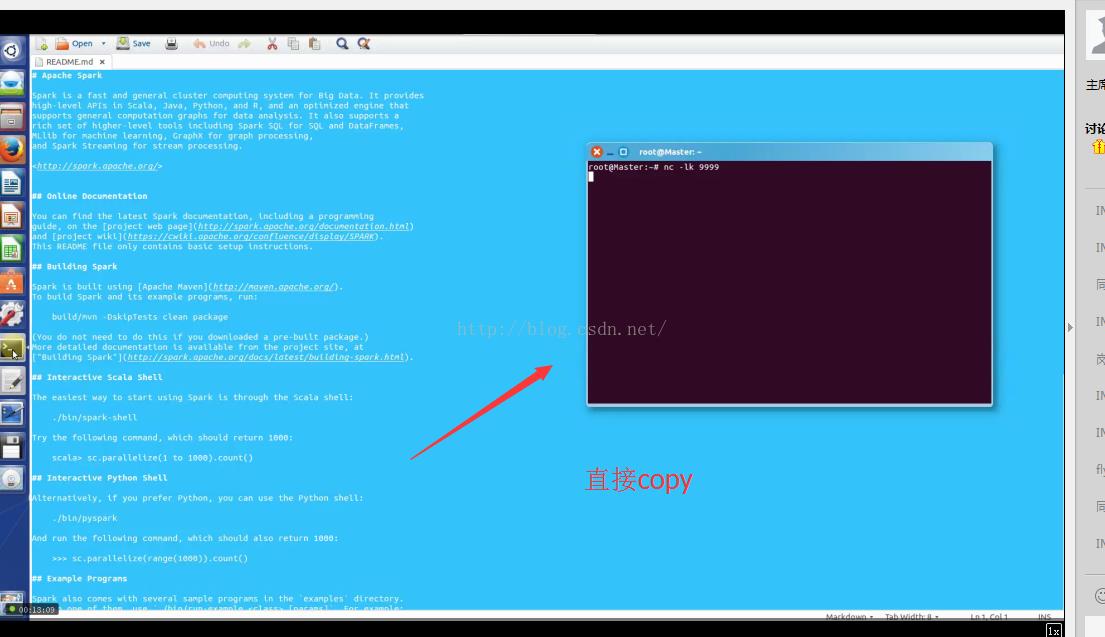
然后按回车运行

DStream和RDD关系:
没有输入数据会打印的是空结果:


但是实际上,Job的执行是Spark Streaming框架帮我们产生的和开发者自己写的Spark代码业务逻辑没有关系,而且Spark Streaming框架的执行时间间隔可以手动配置,如:每隔一秒钟就会产生一次Job的调用。所以在开发者编写好的Spark代码时(如:flatmap、map、collect),不会导致job的运行,job运行是Spark Streaming框架产生的,可以配置成每隔一秒中都会产生一次job调用。
Spark Streaming流进来的数据是DStream,但Spark Core框架只认RDD,这就产生矛盾了?
Spark Streaming框架中,作业实例的产生都是基于rdd实例来产生,你写的代码是作业的模板,即rdd是作业的模板,模板一运行rdd就会被执行,此时action必须处理数据。RDD的模板就是DStream离散流,RDD之间存在依赖关系,DStream就有了依赖关系,也就构成了DStream 有向无环图。这个DAG图,是模板。Spark Streaming只不过是在附在RDD上面一层薄薄的封装而已。你写的代码不能产生Job,只有框架才能产生Job.
如果一秒内计算不完数据,就只能调优了.

总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
Scala和Java二种方式实战Spark Streaming开发
一、Java方式开发
1、开发前准备:假定您以搭建好了Spark集群。
2、开发环境采用eclipse maven工程,需要添加Spark Streaming依赖。

3、Spark streaming 基于Spark Core进行计算,需要注意事项:
设置本地master,如果指定local的话,必须配置至少二条线程,也可通过sparkconf来设置,因为Spark Streaming应用程序在运行的时候,至少有一条线程用于不断的循环接收数据,并且至少有一条线程用于处理接收的数据(否则的话无法有线程用于处理数据),随着时间的推移,内存和磁盘都会不堪重负)。
温馨提示:
对于集群而言,每隔exccutor一般肯定不只一个Thread,那对于处理Spark Streaming应用程序而言,每个executor一般分配多少core比较合适?根据我们过去的经验,5个左右的core是最佳的(段子:分配为奇数个core的表现最佳,例如:分配3个、5个、7个core等)
接下来,让我们开始动手写写Java代码吧!
第一步:创建SparkConf对象

第二步:创建SparkStreamingContext
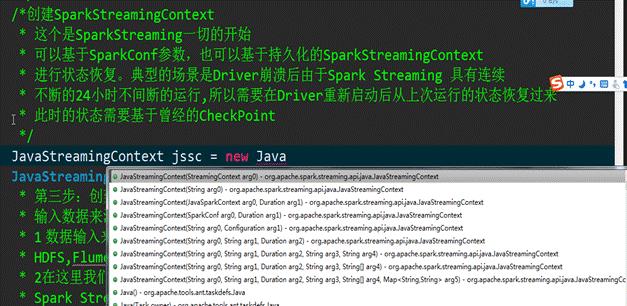
我们采用基于配置文件的方式创建SparkStreamingContext对象:

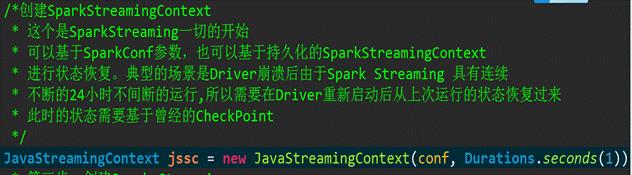
第三步,创建Spark Streaming输入数据来源:
我们将数据来源配置为本地端口9999(注意端口要求没有被占用):

第四步:我们就像对RDD编程一样,基于DStream进行编程,原因是DStream是RDD产生的模板,在Spark Streaming发生计算前,其实质是把每个Batch的DStream的操作翻译成为了RDD操作。
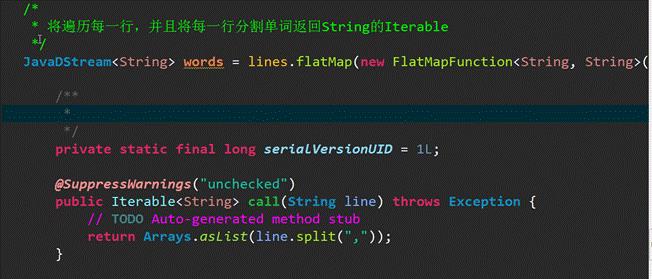
1、flatMap操作:
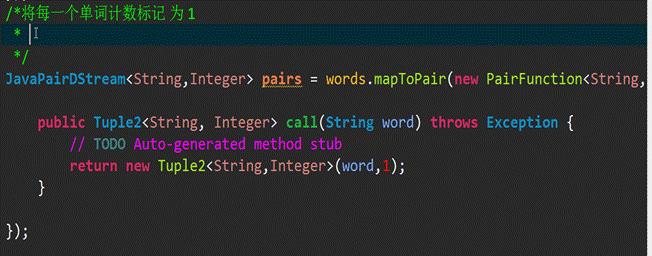
2、 mapToPair操作:
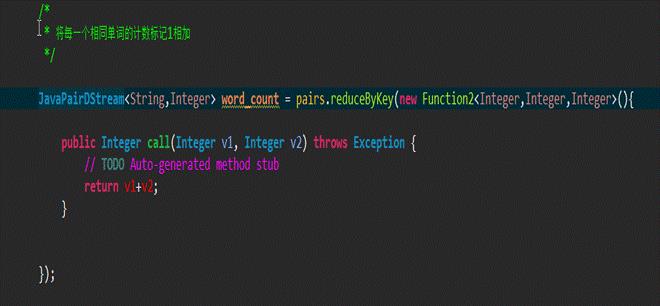
3、reduceByKey操作:
4、print等操作:
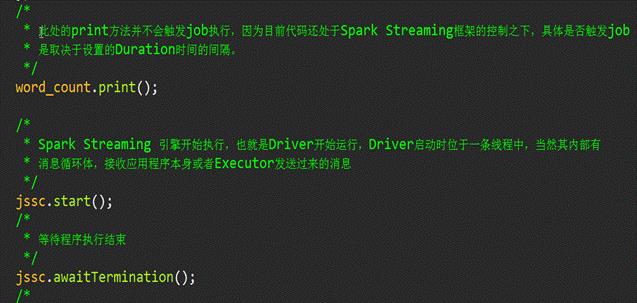
温馨提示:
除了print()方法将处理后的数据输出之外,还有其他的方法也非常重要,在开发中需要重点掌握,比如SaveAsTextFile,SaveAsHadoopFile等,最为重要的是foreachRDD方法,这个方法可以将数据写入Redis,DB,DashBoard等,甚至可以随意的定义数据放在哪里,功能非常强大。
一、Scala方式开发
第一步,接收数据源:

第二步,flatMap操作:

第三步,map操作:

第四步,reduce操作:

第五步,print()等操作:

第六步:awaitTermination操作

总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
StreamingContext、DStream、Receiver深度剖析
一、StreamingContext功能及源码剖析:
1、 通过Spark Streaming对象jssc,创建应用程序主入口,并连上Driver上的接收数据服务端口9999写入源数据:
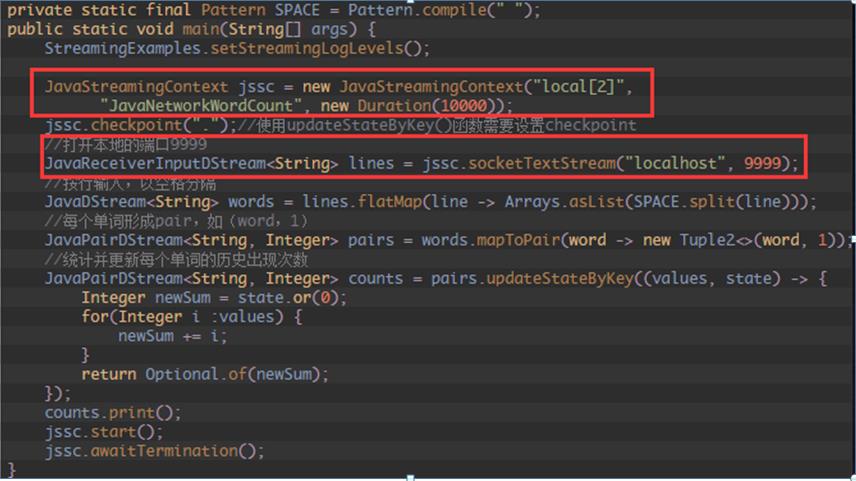
2、 Spark Streaming的主要功能有:
- 主程序的入口;
- 提供了各种创建DStream的方法接收各种流入的数据源(例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等);
- 通过构造函数实例化Spark Streaming对象时,可以指定master URL、appName、或者传入SparkConf配置对象、或者已经创建的SparkContext对象;
- 将接收的数据流传入DStreams对象中;
- 通过Spark Streaming对象实例的start方法启动当前应用程序的流计算框架或通过stop方法结束当前应用程序的流计算框架;

二、DStream功能及源码剖析:
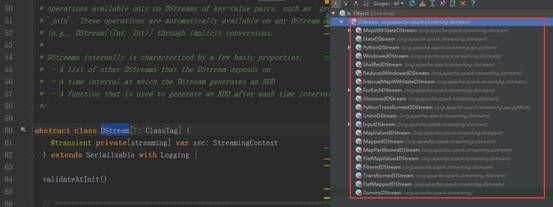
1、 DStream是RDD的模板,DStream是抽象的,RDD也是抽象
2、 DStream的具体实现子类如下图所示:
3、 以StreamingContext实例的socketTextSteam方法为例,其执行完的结果返回DStream对象实例,其源码调用过程如下图:

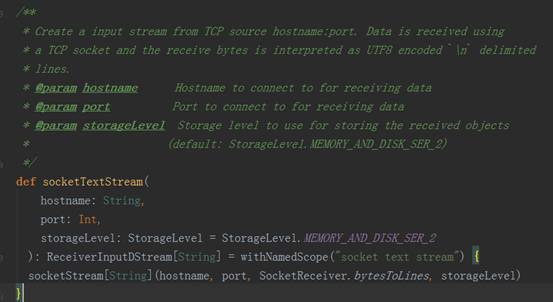
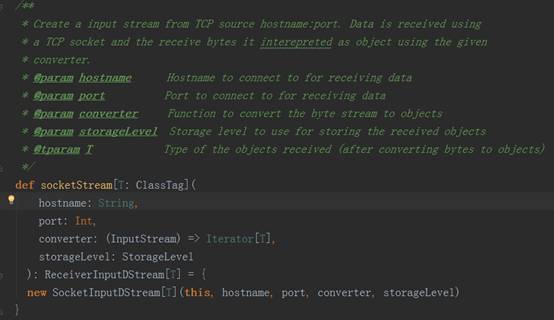

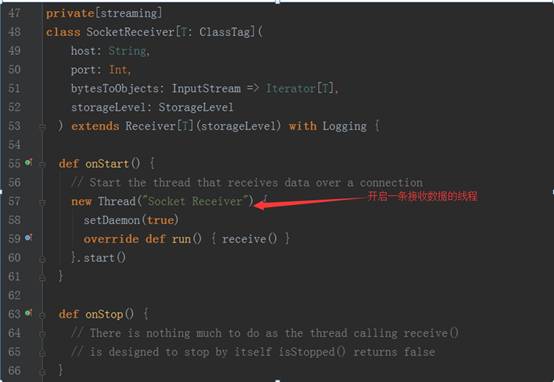
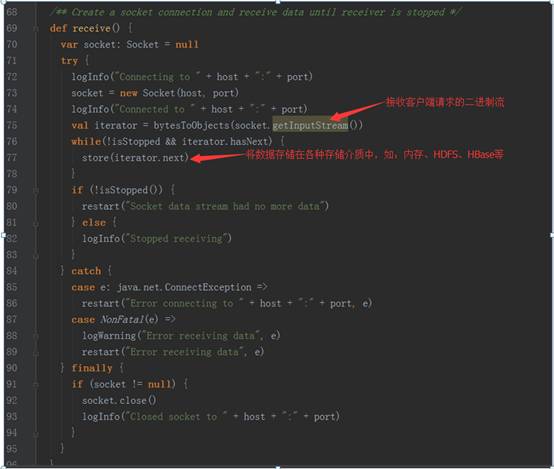
socket.getInputStream获取数据,while循环来存储储蓄数据(内存、磁盘)
三、Receiver功能及源码剖析:
1、Receiver代表数据的输入,接收外部输入的数据,如从Kafka上抓取数据;
2、Receiver运行在Worker节点上;
3、Receiver在Worker节点上抓取Kafka分布式消息框架上的数据时,具体实现类是KafkaReceiver;
4、Receiver是抽象类,其抓取数据的实现子类如下图所示:
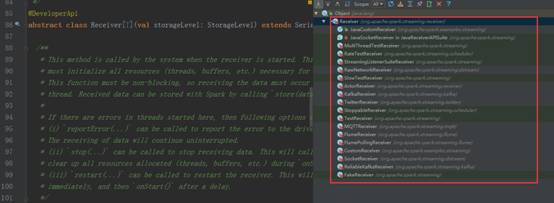
5、 如果上述实现类都满足不了您的要求,您自己可以定义Receiver类,只需要继承Receiver抽象类来实现自己子类的业务需求。
四、StreamingContext、DStream、Receiver结合流程分析:

(1)inputStream代表了数据输入流(如:Socket、Kafka、Flume等)
(2)Transformation代表了对数据的一系列操作,如flatMap、map等
(3)outputStream代表了数据的输出,例如wordCount中的println方法:



数据数据在流进来之后最终会生成Job,最终还是基于Spark Core的RDD进行执行:在处理流进来的数据时是DStream进行Transformation由于是StreamingContext所以根本不会去运行,StreamingContext会根据Transformation生成”DStream的链条”及DStreamGraph,而DStreamGraph就是DAG的模板,这个模板是被框架托管的。当我们指定时间间隔的时候,Driver端就会根据这个时间间隔来触发Job而触发Job的方法就是根据OutputDStream中指定的具体的function,例如wordcount中print,这个函数一定会传给ForEachDStream,它会把函数交给最后一个DStream产生的RDD,也就是RDD的print操作,而这个操作就是RDD触发Action。
总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
基于HDFS的SparkStreaming案例实战
一:Spark集群开发环境准备
- 启动HDFS,如下图所示:

通过web端查看节点正常启动,如下图所示:
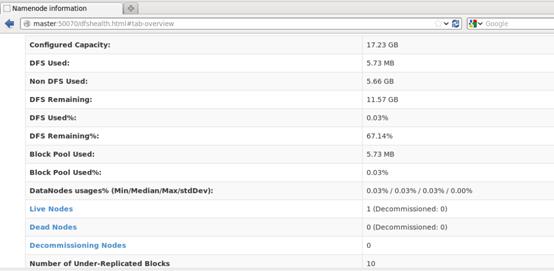
2.启动Spark集群,如下图所示:

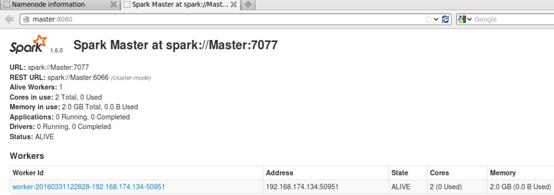
通过web端查看集群启动正常,如下图所示:
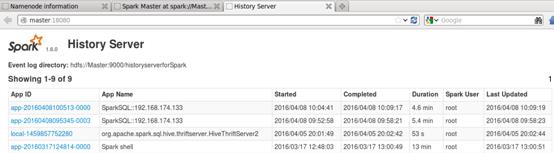
3.启动start-history-server.sh,如下图所示:
二:HDFS的SparkStreaming案例实战(代码部分)
package com.dt.spark.SparkApps.sparkstreaming;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.Java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by Jonson on 2016/4/17.
*/
public class SparkStreamingOnHDFS {
public static void main(String[] args){
/**
* 第一步:配置SparkConf
* 1. 至少两条线程:
* 因为Spark Streaming应用程序在运行的时候,至少有一条线程用于不断的循环接收数据,
* 并且至少有一条线程用于处理接收的数据(否则的话无法有线程用于处理数据,随着时间的推移,内存和磁盘都不堪重负)
* 2. 对于集群而言,每个Executor一般而言肯定不止一个线程,对于处理Spark Streaming的应用程序而言,每个Executor一般
* 分配多少个Core合适呢?根据我们过去的经验,5个左右的core是最佳的(分配为奇数个Core为最佳)。
*/
final SparkConf conf = new SparkConf().setMaster("spark://Master:7077").setAppName("SparkOnStreamingOnHDFS");
/**
* 第二步:创建SparkStreamingContext,这个是Spark Streaming应用程序所有功能的起始点和程序调度的核心
* 1,SparkStreamingContext的构建可以基于SparkConf参数,也可以基于持久化SparkStreamingContext的内容
* 来恢复过来(典型的场景是Driver崩溃后重新启动,由于Spark Streaming具有连续7*24小时不间断运行的特征,
* 所有需要在Driver重新启动后继续上一次的状态,此时状态的恢复需要基于曾经的checkpoint)
* 2,在一个Spark Streaming应用程序中可以创建若干个SparkStreamingContext对象,使用下一个SparkStreamingContext
* 之前需要把前面正在运行的SparkStreamingContext对象关闭掉,由此,我们获得一个重大启发:SparkStreamingContext
* 是Spark core上的一个应用程序而已,只不过Spark Streaming框架箱运行的话需要Spark工程师写业务逻辑
*/
// JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));//Durations.seconds(5)设置每隔5秒
final String checkpointDirectory = "hdfs://Master:9000/library/SparkStreaming/Checkpoint_Data";
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
return createContext(checkpointDirectory,conf);
}
};
/**
* 可以从失败中恢复Driver,不过还需要制定Driver这个进程运行在Cluster,并且提交应用程序的时候
* 指定 --supervise;
*/
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, factory);
/**
* 现在是监控一个文件系统的目录
* 此处没有Receiver,Spark Streaming应用程序只是按照时间间隔监控目录下每个Batch新增的内容(把新增的)
* 作为RDD的数据来源生成原始的RDD
*/
//指定从HDFS中监控的目录
JavaDStream lines = jsc.textFileStream("hdfs://Master:9000/library/SparkStreaming/Data");
/**
* 第四步:接下来就像对于RDD编程一样基于DStreaming进行编程!!!
* 原因是:
* DStreaming是RDD产生的模板(或者说类)。
* 在Spark Streaming具体发生计算前其实质是把每个batch的DStream的操作翻译成对RDD的操作!!
* 对初始的DStream进行Transformation级别的处理,例如Map,filter等高阶函数的编程,来进行具体的数据计算。
* 第4.1步:将每一行的字符串拆分成单个单词
*/
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String,String>() {
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
/**
* 第4.2步:对初始的JavaRDD进行Transformation级别的处理,例如map,filter等高阶函数等的编程,来进行具体的数据计算
* 在4.1的基础上,在单词拆分的基础上对每个单词实例计数为1,也就是word => (word,1)
*/
JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
});
/**
* 第4.3步:在每个单词实例计数的基础上统计每个单词在文件中出现的总次数
*/
JavaPairDStream<String,Integer> wordscount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
/**
* 此处的print并不会直接触发Job的执行,因为现在的一切都是在Spark Streaming框架控制下的,对于Spark而言具体是否
* 触发真正的Job运行是基于设置的Duration时间间隔的
* 一定要注意的是:Spark Streaming应用程序要想执行具体的Job,对DStream就必须有output Stream操作,
* output Stream有很多类型的函数触发,例如:print,saveAsTextFile,saveAsHadoopFiles等,其实最为重要的一个方法是
* foraeachRDD,因为Spark Streaming处理的结果一般都会放在Redis,DB,DashBoard等上面,foreachRDD主要就是用来完成这些
* 功能的,而且可以随意的自定义具体数据到底存放在哪里!!!
*/
wordscount.print();
/**
* Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的。
* 当然其内部有消息循环体用于接收应用程序本身或者Executor的消息;
*/
jsc.start();
jsc.awaitTermination();
jsc.close();
}
/**
* 工厂化模式构建JavaStreamingContext
*/
private static JavaStreamingContext createContext(String checkpointDirectory,SparkConf conf){
System.out.println("Creating new context");
SparkConf = conf;
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf,Durations.seconds(5));
ssc.checkpoint(checkpointDirectory);
return ssc;
}
}
代码打包在集群中运行
- 创建目录



2.脚本运行
脚本内容如下:

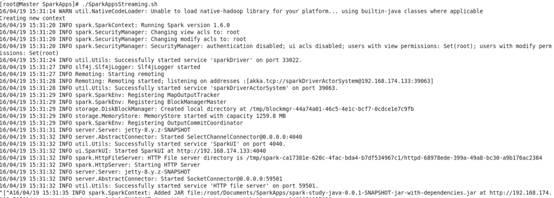
此时Spark Streaming会每隔5秒执行一次,不断的扫描监控目录下是否有新的文件。
3.上传文件到HDFS中的Data目录下

4.输出结果

三:Spark Streaming on HDFS源码解密
- JavaStreamingContextFactory的create方法可以创建JavaStreamingContext
- 而我们在具体实现的时候覆写了该方法,内部就是调用createContext方法来具体实现。上述实战案例中我们实现了createContext方法。
/*** Factory interface for creating a new JavaStreamingContext
*/
trait JavaStreamingContextFactory {
def create(): JavaStreamingContext
}
3.checkpoint:
一方面:保持容错
一方面保持状态
在开始和结束的时候每个batch都会进行checkpoint
** Sets the context to periodically checkpoint the DStream operations for master
* fault-tolerance. The graph will be checkpointed every batch interval.
* @param directory HDFS-compatible directory where the checkpoint data will be reliably stored
*/
def checkpoint(directory: String) {
ssc.checkpoint(directory)
}
4.remember:
流式处理中过一段时间数据就会被清理掉,但是可以通过remember可以延长数据在程序中的生命周期,另外延长RDD更长的时间。
应用场景:
假设数据流进来,进行ML或者Graphx的时候有时需要很长时间,但是bacth定时定条件的清除RDD,所以就可以通过remember使得数据可以延长更长时间。/**
* Sets each DStreams in this context to remember RDDs it generated in the last given duration.
* DStreams remember RDDs only for a limited duration of duration and releases them for garbage
* collection. This method allows the developer to specify how long to remember the RDDs (
* if the developer wishes to query old data outside the DStream computation).
* @param duration Minimum duration that each DStream should remember its RDDs
*/
def remember(duration: Duration) {
ssc.remember(duration)
}
5.在JavaStreamingContext中,getOrCreate方法源码如下:
如果设置了checkpoint ,重启程序的时候,getOrCreate()会重新从checkpoint目录中初始化出StreamingContext。
/* * Either recreate a StreamingContext from checkpoint data or create a new StreamingContext.
* If checkpoint data exists in the provided `checkpointPath`, then StreamingContext will be
* recreated from the checkpoint data. If the data does not exist, then the provided factory
* will be used to create a JavaStreamingContext.
*
* @param checkpointPath Checkpoint directory used in an earlier JavaStreamingContext program
* @param factory JavaStreamingContextFactory object to create a new JavaStreamingContext
* @deprecated As of 1.4.0, replaced by `getOrCreate` without JavaStreamingContextFactor.
*/
@deprecated("use getOrCreate without JavaStreamingContextFactor", "1.4.0")
def getOrCreate(
checkpointPath: String,
factory: JavaStreamingContextFactory
): JavaStreamingContext = {
val ssc = StreamingContext.getOrCreate(checkpointPath, () => {
factory.create.ssc
})
new JavaStreamingContext(ssc)
}
异常问题思考:

为啥会报错?
- Streaming会定期的进行checkpoint。
- 重新启动程序的时候,他会从曾经checkpoint的目录中,如果没有做额外配置的时候,所有的信息都会放在checkpoint的目录中(包括曾经应用程序信息),因此下次再次启动的时候就会报错,无法初始化ShuffleDStream。
总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
SparkStreaming数据源Flume实际案例
一、什么是Flume?
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
flume的一些核心概念:
Agent 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
- Client 生产数据,运行在一个独立的线程。
- Source 从Client收集数据,传递给Channel。
- Sink 从Channel收集数据,运行在一个独立线程。
- Channel 连接 sources 和 sinks ,这个有点像一个队列。
- Events 可以是日志记录、 avro 对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
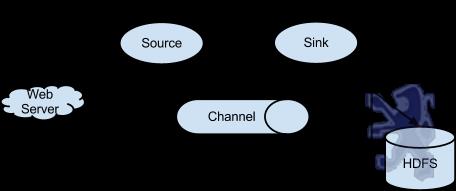
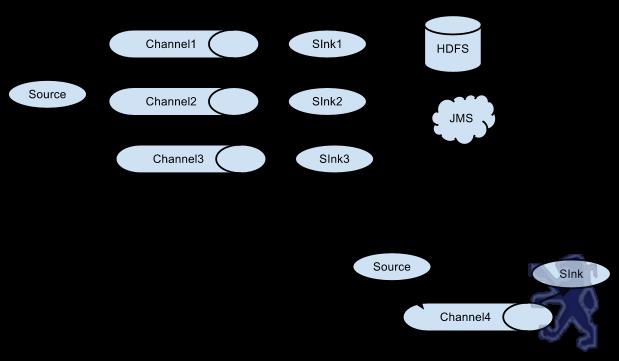
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。如下图所示:
二、Flume+Kafka+Spark Streaming应用场景:
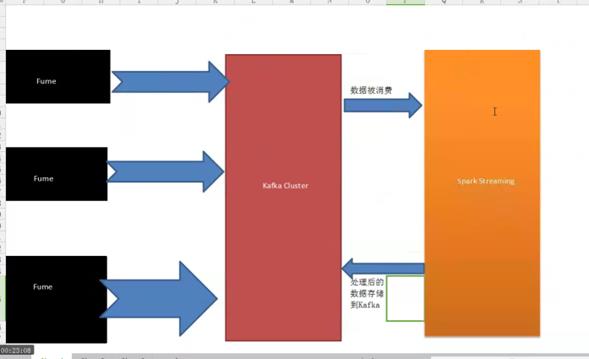
1、Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,架构如下图:
2、Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,同时将最终结果通过Ganglia监控工具进行图形化展示,架构如下图:

3、我们要做:Spark streaming 交互式的360度的可视化,Spark streaming 交互式3D可视化UI;Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,将最终结果同时存储在数据库(MySQL)、内存中间件(Redis、MemSQL)中,同时将最终结果通过Ganglia监控工具进行图形化展示,架构如下图:
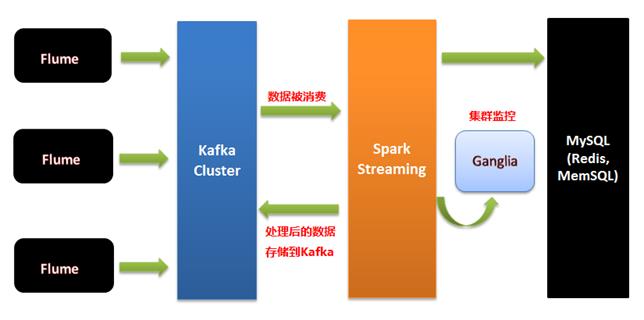
三、Kafka数据写入Spark Streaming有二种方式:
一种是Receivers,这个方法使用了Receivers来接收数据,Receivers的实现使用到Kafka高层次的消费者API,对于所有的Receivers,接收到的数据将会保存在Spark 分布式的executors中,然后由Spark Streaming启动的Job来处理这些数据;然而,在默认的配置下,这种方法在失败的情况下会丢失数据,为了保证零数据丢失,你可以在Spark Streaming中使用WAL日志功能,这使得我们可以将接收到的数据保存到WAL中(WAL日志可以存储在HDFS上),所以在失败的时候,我们可以从WAL中恢复,而不至于丢失数据。
另一种是DirectAPI,产生数据和处理数据的时候是在两台机器上?其实是在同一台数据上,由于在一台机器上有Driver和Executor,所以这台机器要足够强悍。
Flume集群将采集的数据放到Kafka集群中,Spark Streaming会实时在线的从Kafka集群中通过DirectAPI拿数据,可以通过Kafka中的topic+partition查询最新的偏移量(offset)来读取每个batch的数据,即使读取失败也可再根据偏移量来读取失败的数据,保证应用运行的稳定性和数据可靠性。
温馨提示:
1、Flume集群数据写入Kafka集群时可能会导致数据存放不均衡,即有些Kafka节点数据量很大、有些不大,后续会对分发数据进行自定义算法来解决数据存放不均衡问题。
2、个人强烈推荐在生产环境下用DirectAPI,但是我们的发行版,会对DirectAPI进行优化,降低其延迟。
总结:
实际生产环境下,搜集分布式的日志以Kafka为核心。
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
Spark Streaming on Kafka解析和安装实战
本课分2部分讲解:
第一部分,讲解Kafka的概念、架构和用例场景;
第二部分,讲解Kafka的安装和实战。
由于时间关系,今天的课程只讲到如何用官网的例子验证Kafka的安装是否成功。后续课程会接着讲解如何集成Spark Streaming和Kafka。
一、Kafka的概念、架构和用例场景
http://kafka.apache.org/documentation.html#introdution
1、Kafka的概念
Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。zookeeper和kafka和大数据是不只能用于大数据的,集群启不启动,它都可以使用,也可以用于Javaserver普通的企业级平台上。
什么是消息组件:
以帅哥和美女聊天为例,帅哥如何和美女交流呢?这中间通常想到的是微信、QQ、电话、邮件等通信媒介,这些通信媒介就是消息组件,帅哥把聊天信息发送给消息组件、消息组件将消息推送给美女,这就是常说的生产者、消费者模型,kafka不仅仅说是生产者消费者模式中广播的概念,也可以实现队列的方式,kafka的消费者中有一个group的概念,group中可以有很多实体,也可以只有一个实体,group中只有一个实体的话,就是队列的方式,所以从消息驱动的角度讲,它是广播的方式和队列的方式的完美结合体。而且在发送信息时可以将内容进行分类,即所谓的Topic主题。Kafka就是这样的通信组件,将不同对象组件粘合起来的纽带, 且是解耦合方式传递数据。
完善的流处理系统的特点:
1)能在线的以非常低的延迟,来处理数据,而且是稳定可靠的
2)能对流进来的数据进行非常复杂的分析,而不是简单的仅仅统计的分析
3)不仅能处理当前在线的数据,也能处理过去一天,一周,一个月甚至一年的数据
Apache Kafka与传统消息系统相比,有以下不同的特点:
- 分布式系统,易于向外扩展;
- 在线低延迟,同时为发布和订阅提供高吞吐量;
- 流进来的数据一般处理完后就消失了,也可以将消息存储到磁盘,因此可以处理1天甚至1周前内容,所以kafka不仅是一个消息中间件,还是一个存储系统
2、Kafka的架构

Kafka既然具备消息系统的基本功能,那么就必然会有组成消息系统的组件:
Topic,Producer和Consumer。Kafka还有其特殊的Kafka Cluster组件。
Topic主题:
代表一种数据的类别或类型,工作、娱乐、生活有不同的Topic,生产者需要说明把说明数据分别放在那些Topic中,里面就是一个个小对象,并将数据数据推到Kafka,消费者获取数据是pull的过程。一组相同类型的消息数据流。这些消息在Kafka会被分区存放,并且有多个副本,以防数据丢失。每个分区的消息是顺序写入的,并且不可改写。
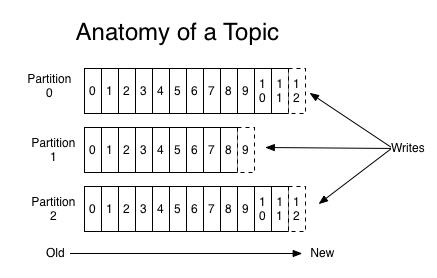
- Producer(生产者):把数据推到Kafka系统的任何对象。
- Kafka Cluster(Kafka集群):把推到Kafka系统的消息保存起来的一组服务器,也叫Broker。因为Kafka集群用到了Zookeeper作为底层支持框架,所以由一个选出的服务器作为Leader来处理所有消息的读和写的请求,其他服务器作为Follower接受Leader的广播同步备份数据,以备灾难恢复时用。
- Consumer(消费者):从Kafka系统订阅消息的任何对象。
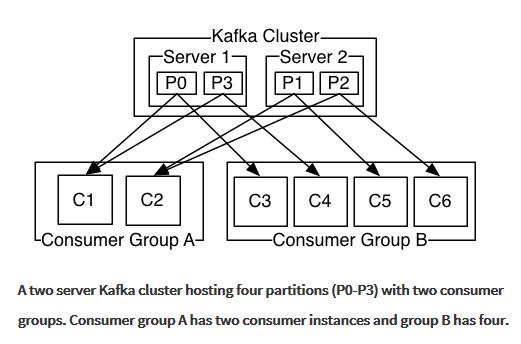
消费者可以有多个,并且某些消费者还可以组成Consumer Group。多个Consumer Group之间组成消息广播的关系,所以各个Group可以拉相同的消息数据。在Consumer Group内部,各消费者之间对Consumer Group拉出来的消息数据是队列先进先出的关系,某个消息数据只能给该Group的一个消费者使用,同一个Group中的实体是互斥的,对一个消息,这样是避免重复消费。如果有多个group,每个group中只有一个实体,这就是队列的方式了,因为它是互斥的。如果不是一个实体,则是广播模式,如下图所示,广播只能广播给一个group中的一个消费实体
kafka的数据传输是基于kernel(内核)级别的(传输速度接近0拷贝-ZeroCopy)、没有用户空间的参与。Linux本身是软件,软件启动时第一个启动进程叫init,在init进程启动后会进入用户空间;kafka是用java写的,是基于jvm虚拟机的。例如:在分布式系统中,机器A上的应用程序需要读取机器B上的Java服务数据,由于Java程序对应的JVM是用户空间级别而且数据在磁盘上,A上应用程序读取数据时会首先进入机器B上的内核空间再进入机器B的用户空间,读取用户空间的数据后,数据再经过B机器上的内核空间分发到网络中(之所以要再经过B的内核,因为要通过网络通信,不通过内核,哪里来的网络通信),机器A网卡接收到传输过来的数据后再将数据写入A机器的内核空间,从而最终将数据传输给A的用户空间进行处理。如下图:网络本身是一种硬件,磁盘只是硬件的一种。
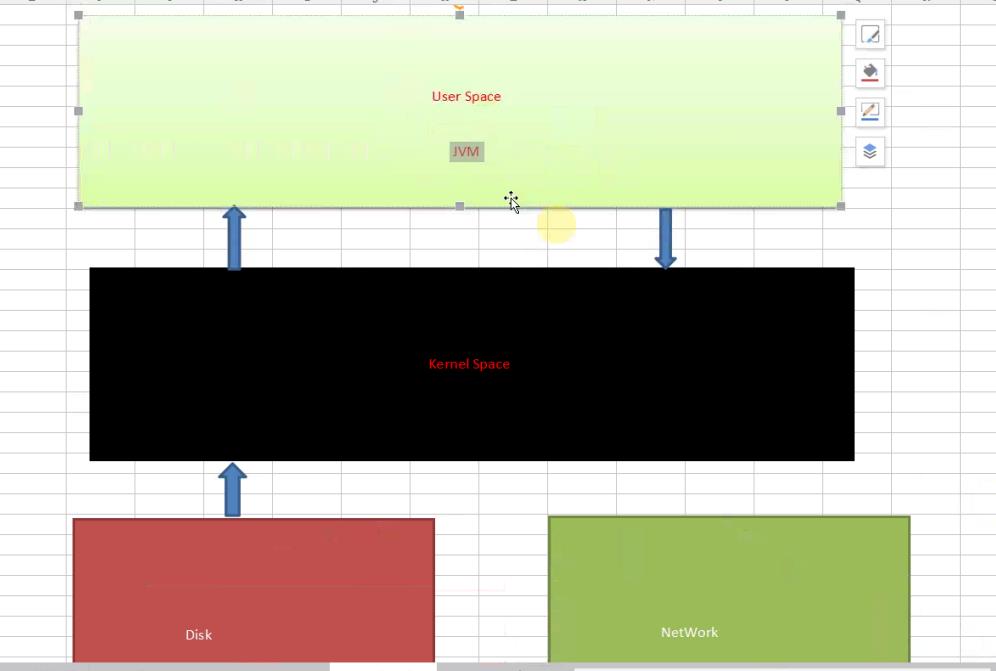
正常情况下,外部系统从Java程序中读取数据,传输给内核空间并依赖网卡将数据写入到网络中,从而把数据传输出去。其实Java本身是内核的一层外衣,Java Socket编程,操作的各种数据都是在JVM的用户空间中进行的。而Kafka操作数据是放在内核空间的,通常内核空间处理数据的速度比用户空间快上万倍,因为没用用户态和内核态的切换,所以通过kafka可以实现高速读、写数据。只要磁盘空间足够大,可以无限量的存储数据,kafka的数据就是存储在磁盘中的,不是存在内核中的。而很多消息组件是把数据存内存中的。kafka用zookeeperg管理元数据,而且按顺序写数据,比随机写要快很多。又有副本!
3、Kafka的用例场景
类似微信,手机和邮箱等等这样大家熟悉的消息组件,Kafka也可以:
- 支持文字/图片
- 可以存储内容
- 分门别类
从内容消费的角度,Kafka把邮箱中的邮件类型看成是Topic。
二、Kafka的安装和实战
http://kafka.apache.org/documentation.html#quickstart
1、安装和配置Zookeeper
Kafka集群模式需要提前安装好Zookeeper。
- 提示:Kafka单例模式不需要安装额外的Zookeeper,可以使用内置的Zookeeper。
- Kafka集群模式需要至少3台服务器。本课实战用到的服务器Hostname:master,slave1,slave2。
- 本课中用到的Zookeeper版本是Zookeeper-3.4.6。
1) 下载Zookeeper
进入http://www.apache.org/dyn/closer.cgi/zookeeper/,你可以选择其他镜像网址去下载,用官网推荐的镜像:http://mirror.bit.edu.cn/apache/zookeeper/。提示:可以直接下载群里的Zookeeper安装文件。

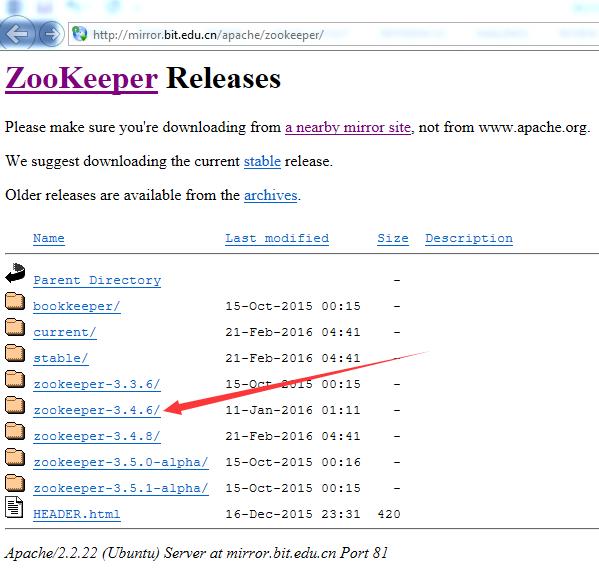
下载zookeeper-3.4.6.tar.gz

1) 安装Zookeeper
提示:下面的步骤发生在master服务器。
以ubuntu14.04举例,把下载好的文件放到/root目录,用下面的命令解压:
cd /root
tar -zxvf zookeeper-3.4.6.tar.gz
解压后在/root目录会多出一个zookeeper-3.4.6的新目录,用下面的命令把它剪切到指定目录即安装好Zookeeper了:
cd /root
mv zookeeper-3.4.6 /usr/local/spark
之后在/usr/local/spark目录会多出一个zookeeper-3.4.6的新目录。下面我们讲如何配置安装好的Zookeeper。
2) 配置Zookeeper
提示:下面的步骤发生在master服务器。
- 配置.bashrc
- 打开文件:vi /root/.bashrc
- 在PATH配置行前添加:
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6
- 最后修改PATH:
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:$PATH
- 使配置的环境变量立即生效:source /root/.bashrc
- 创建data目录
- cd $ZOOKEEPER_HOME
- mkdir data
- 创建并打开zoo.cfg文件
- cd $ZOOKEEPER_HOME/conf
- cp zoo_sample.cfg zoo.cfg
- vi zoo.cfg
- 配置zoo.cfg
# 配置Zookeeper的日志和服务器身份证号等数据存放的目录。
# 千万不要用默认的/tmp/zookeeper目录,因为/tmp目录的数据容易被意外删除。
dataDir=../data
# Zookeeper与客户端连接的端口
clientPort=2181
# 在文件最后新增3行配置每个服务器的2个重要端口:Leader端口和选举端口
# server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;
# B 是这个服务器的hostname或ip地址;
# C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
# D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,
# 选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# 如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信
# 端口号不能一样,所以要给它们分配不同的端口号。
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
改成如下方式:
dataDir=/usr/local/spark/zookeeper-3.4.6/data
dataLogDir=/usr/local/spark/zookeeper-3.4.6/logs
clientPort=2181
server.0=master1:2888:3888
server.1=work1:2888:3888
server.2=work2:2888:3888
- 创建并打开myid文件
- cd $ZOOKEEPER_HOME/data
- touch myid
- vi myid
- 配置myid
按照zoo.cfg的配置,myid的内容就是1。要写成0,和上面zoo.cfg里面的配置server.0,server.1,server.2一致,所以下面work1中myid内容为1,work2中myid内容为2
3) 同步master的安装和配置到slave1和slave2
- 在master服务器上运行下面的命令
cd /root
scp ./.bashrc root@slave1:/root
scp ./.bashrc root@slave2:/root
cd /usr/local/spark
scp -r ./zookeeper-3.4.6 root@slave1:/usr/local/spark
scp -r ./zookeeper-3.4.6 root@slave2:/usr/local/spark
- 在slave1服务器上运行下面的命令
vi $ZOOKEEPER_HOME/data/myid
按照zoo.cfg的配置,myid的内容就是1。
- 在slave2服务器上运行下面的命令
vi $ZOOKEEPER_HOME/data/myid
按照zoo.cfg的配置,myid的内容就是2。
4) 启动Zookeeper服务
- 在master服务器上运行下面的命令
zkServer.sh start
- 在slave1服务器上运行下面的命令
source /root/.bashrc
zkServer.sh start
- 在slave1服务器上运行下面的命令
source /root/.bashrc
zkServer.sh start
5) 验证Zookeeper是否安装和启动成功
- 在master服务器上运行命令:jps和zkServer.sh status
root@master:/usr/local/spark/zookeeper-3.4.6/bin# jps
3844 QuorumPeerMain
4790 Jps
zkServer.sh status
root@master:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在slave1服务器上运行命令:jps和zkServer.sh status
source /root/.bashrc
root@slave1:/usr/local/spark/zookeeper-3.4.6/bin# jps
3462 QuorumPeerMain
4313 Jps
root@slave1:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在slave2服务器上运行命令:jps和zkServer.sh status
root@slave2:/usr/local/spark/zookeeper-3.4.6/bin# jps
4073 Jps
3277 QuorumPeerMain
root@slave2:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
至此,代表Zookeeper已经安装和配置成功。
2、安装和配置Kafka
本课中用到的Kafka版本是Kafka-2.10-0.9.0.1。
1) 下载Kafka
进入http://kafka.apache.org/downloads.html,左键单击kafka_2.10-0.9.0.1.tgz。提示:可以直接下载群里的Kafka安装文件。

下载kafka_2.10-0.9.0.1.tgz

1) 安装Kafka
提示:下面的步骤发生在master服务器。
以ubuntu14.04举例,把下载好的文件放到/root目录,用下面的命令解压:
cd /root
tar -zxvf kafka_2.10-0.9.0.1.tgz
解压后在/root目录会多出一个kafka_2.10-0.9.0.1的新目录,用下面的命令把它剪切到指定目录即安装好Kafka了:
cd /root
mv kafka_2.10-0.9.0.1 /usr/local
之后在/usr/local目录会多出一个kafka_2.10-0.9.0.1的新目录。下面我们讲如何配置安装好的Kafka。
2) 配置Kafka
提示:下面的步骤发生在master服务器。
- 配置.bashrc
- 打开文件:vi /root/.bashrc
- 在PATH配置行前添加:
export KAFKA_HOME=/usr/local/kafka_2.10-0.9.0.1
- 最后修改PATH:
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP
以上是关于sparkstreaming的主要内容,如果未能解决你的问题,请参考以下文章
超详细!一文告诉你 SparkStreaming 如何整合 Kafka !附代码可实践