关联规则
Posted 懵懂的菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关联规则相关的知识,希望对你有一定的参考价值。
关联规则
1 关联规则
关联规则挖掘的目的是在数据项目中找出所有的并发关系,除了基本Aprioris算法,还有一些常用的改进算法,例如多最小支持度的关联规则挖掘,分类关联规则挖掘。
Aprioris算法基于演绎原理(或称为向下封闭属性)来高效地产生所有频繁项目集。算法基于逐级搜索的思想,它采用多轮搜索的方法,每一轮搜索扫描一遍整个数据集,并最终生成所有的频繁项目集合。
多最小支持度算法简称为"MS-Apriori算法",它通过对项目集合中的项目基于最小项目支持度值来进行升序排序。该算法也是基于逐级搜索的,通过多次遍历数据之后产生所有频繁项目集。
分类关联规则挖掘(Class Association Rules,CAR)和一般的关联规则有两点不同,第一点是:CAR的后件只有一个项目,第二点是:CAR的后件只能从分类标识集合中选取。项目集合中的项目都不能作为后件使用,分类标识集合中的项目也不能作为前件使用。
下面通过具体应用说明上述三种关联规则的应用与差别。
首先给出一个事物集合的例子。

给定最小支持度minsup=30%和最小置信度mincof=80%。通过三种数据挖掘方法,找寻事物集合中的关联规则。
1.1 Apriori算法

Apriori算法分两步进行,第一步生成所有频繁项目集,第二步从频繁项目集中生成所有可信关联规则。
1.1.1 生成频繁项目集过程
(1)在第一轮搜索中,算法计算出所有只包含一个项目的项集在事务中的支持度,并且写出单项目频繁项目集(即1-频繁项目集)。(算法第1-2行)
(每个频繁项目集后的数字表示这个频繁项目集的支持计数,在例子中支持度计数大于等于3即可)
- 随后每一轮搜索都分为三步进行:
- 将算法第(k-1)生成的频繁项目集集合
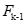 作为种子集合产生候选项集集合
作为种子集合产生候选项集集合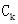 ,而
,而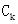 中的这些候选项目集都是可能的频繁项目集。这个过程通过candidate-gen函数完成。
中的这些候选项目集都是可能的频繁项目集。这个过程通过candidate-gen函数完成。

Candidate-gen(候选项集集合
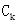 的生成)函数:该函数可以分成两步:合并和剪枝
的生成)函数:该函数可以分成两步:合并和剪枝
合并:这一步将两个(k-1)-频繁项目集合并来产生一个可能的k-候选项集c。两个频繁项目集的前k-2个项目都是相同的,只有最后一个项目是不同的。随后c被加入到候选项目集合
 中。
中。
剪枝:从合并步中得到的候选项集集合并不是最终的
 。该候选项集要满足向下封闭原理,需要判断c的所有(k-1)-子集是否都在
。该候选项集要满足向下封闭原理,需要判断c的所有(k-1)-子集是否都在 中。
中。
- 随后算法对整个事务数据库进行扫描,计算
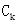 中每个候选项集c的支持度。(算法5-10行)
中每个候选项集c的支持度。(算法5-10行)
- 在本轮搜索的最后,算法计算出
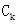 中每个候选项集的支持度,并将符合最小支持度要求的候选项集加入
中每个候选项集的支持度,并将符合最小支持度要求的候选项集加入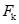 中。(算法11行)
中。(算法11行)
- 算法最终输出的是所有频繁项目集的集合F。
1.1.2 事例生成频繁项目集的过程
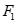 :{{牛肉}:4,{鸡肉}:5,{牛奶}:4,{奶酪}:4,{衣服}:3}
:{{牛肉}:4,{鸡肉}:5,{牛奶}:4,{奶酪}:4,{衣服}:3}
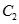 :{{牛肉,鸡肉},{牛肉,牛奶},{牛肉,奶酪},{牛肉,衣服},......}
:{{牛肉,鸡肉},{牛肉,牛奶},{牛肉,奶酪},{牛肉,衣服},......}
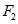 :{{牛肉,鸡肉}:3,{鸡肉,牛奶}:4,{牛肉,奶酪}:3,{鸡肉,衣服}:3,{衣服,牛奶}:3}
:{{牛肉,鸡肉}:3,{鸡肉,牛奶}:4,{牛肉,奶酪}:3,{鸡肉,衣服}:3,{衣服,牛奶}:3}
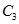 :{{鸡肉,衣服,牛奶}}
:{{鸡肉,衣服,牛奶}}
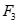 :{{鸡肉,衣服,牛奶}:3}
:{{鸡肉,衣服,牛奶}:3}
1.1.3 规则生成的过程

首先,需要明确一点,当给定一个频繁项目集f时,如果一个关联规则的后件为a,那么所有以a的任一非空子集为后件的候选规则都是关联规则。(先前条件)
算法如下:
- 从频繁项目集f中生成所有后件只有一项的关联规则。
- 然后利用所有得到的关联规则和candidate-gen()函数,调用ap-genRules函数生成所有2-后件候选关联规则,依次类推,同时要满足先前条件,即1-后件可以组合生成2-后件。
1.1.4 事例规则生成的过程
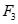 中的频繁项目集生成1-后件候选关联规则:
中的频繁项目集生成1-后件候选关联规则:
规则1:鸡肉,衣服
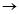 牛奶[支持度=3/7,置信度=3/3]
牛奶[支持度=3/7,置信度=3/3]
规则2:鸡肉,牛奶
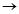 衣服[支持度=3/7,置信度=3/4](删除)
衣服[支持度=3/7,置信度=3/4](删除)
规则3:衣服,牛奶
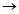 鸡肉[支持度=3/7,置信度=3/3]
鸡肉[支持度=3/7,置信度=3/3]
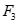 中的频繁项目集生成2-后件候选关联规则:
中的频繁项目集生成2-后件候选关联规则:
规则4:衣服
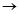 牛奶,鸡肉[支持度=3/7,置信度=3/3]
牛奶,鸡肉[支持度=3/7,置信度=3/3]
1.2 MS-Apriori算法

2.1.1 生成频繁项目集过程
MS-Apriori算法的详细流程。
算法第1行对I中的所有项目根据项目的MIS值(存储在MS中)进行排序。
算法第2行调用init-pass()函数对数据进行第一遍遍历,得到生成
 (基数为2的候选项集集合)的种子L。Init-pass函数分为两步:
(基数为2的候选项集集合)的种子L。Init-pass函数分为两步:
- 扫描一遍数据,计算每个项目的支持计数。
- 按存储顺序在M中找出第一个满足
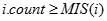 的项目i,将其加入L中。对于M中i之后的每个项目j,如果
的项目i,将其加入L中。对于M中i之后的每个项目j,如果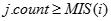 ,则将j加入L中。
,则将j加入L中。
之后对数据的每一遍遍历,算法都执行三步操作:
- MScandidate-gen函数利用在第(k-1)轮找到的频繁项目集集合
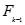 生成候选项集集合
生成候选项集集合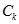 。K=2是一个特例,这是候选项集集合的函数为Level2-candidate-gen()。
。K=2是一个特例,这是候选项集集合的函数为Level2-candidate-gen()。

Level2-candidate-gen函数:函数有一个参数L,返回一个集合,是所有2-频繁项目集集合的超集。同时要满足
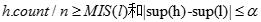 。
。

MScandidate-gen函数:函数也分为两步,合并和剪枝。合并步和candidate-gen()函数一样。剪枝步则不同。
对于c的每个(k-1)-子集s,如果s不在
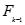 中,且s包含c[1],也即c中拥有最低MIS值的项目,则c就能从
中,且s包含c[1],也即c中拥有最低MIS值的项目,则c就能从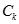 中删除。如果这个s不不包含c[1],则即使s并不在
中删除。如果这个s不不包含c[1],则即使s并不在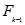 中,我们也不能把c删除,因为我们不能断定s不满足MIS(c[1])。
中,我们也不能把c删除,因为我们不能断定s不满足MIS(c[1])。
- 扫描数据,计算
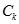 中各项集的支持计数。对每个候选项集c,算法不仅计算它的支持计数,同时也计算去掉c的第一个项目后的支持计数,也即c-{c[1]},这个数据将在关联规则的生成阶段用到。
中各项集的支持计数。对每个候选项集c,算法不仅计算它的支持计数,同时也计算去掉c的第一个项目后的支持计数,也即c-{c[1]},这个数据将在关联规则的生成阶段用到。
注意:在实际应用中,如果不想生成某些频繁项目集,只需将该频繁项目集的最小支持度设置为101%。
2.1.2 规则生成的过程
在MS-Apriori算法中,仅仅记录每个频繁项目集的支持计数是不够的。同时我们还要避免头项目问题的产生,即只有当频繁项目集中具有最小MIS值的项目处于规则的后件时才会发生头项目问题。
1.3 分类关联规则
生成分类关联规则的算法称为CAR-Apriori,是基于Apriori算法的。CAR-Apriori算法需要多次遍历数据来生成所有频繁项目规则的项。

不同于一般的关联规则挖掘CAR可以直接一步生成,关键的操作是找出所有支持度高于最小支持度阈值的规则项。一个规则项表示为:
(condset,y)
其中condset属于I是一个项目集合,成为条件集,y属于Y是一个类标。一个条件集的支持计数表示为condsupCount,是T中包含该条件集的事物的数量,称为条件集支持计数。一个规则项(condset,y)的支持计数表示为rulesupCount,是T中包含条件集countset且类标为y的事物的数量,称为规则支持计数。只要满足最小支持度的规则项都称为频繁规则项,其余的都称为非频繁规则项。
在第一遍遍历中,算法计算每个1-规则项的支持计数。所有的1-候选规则项的集合为:
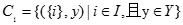
算法第2行决定
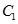 中候选1-规则项是否频繁的。从频繁1-规则项中,我们生成1-前件CAR。后续的遍历,以K-1轮生成的频繁(k-1)-规则项的集合为种子生成k-候选规则项的集合。每个候选k-规则项的真实支持计数,包括condsupCount和rulesupCount,在对事物数据集合的扫描中得到更新。在数据扫描结束后,算法决定
中候选1-规则项是否频繁的。从频繁1-规则项中,我们生成1-前件CAR。后续的遍历,以K-1轮生成的频繁(k-1)-规则项的集合为种子生成k-候选规则项的集合。每个候选k-规则项的真实支持计数,包括condsupCount和rulesupCount,在对事物数据集合的扫描中得到更新。在数据扫描结束后,算法决定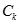 中哪些候选k-规则项是真正频繁地。与Aprioir算法中唯一的不同是,CARcandidate-gen()中,仅仅将具有相同 分类的规则项通过合并它们的条件集进行合并。
中哪些候选k-规则项是真正频繁地。与Aprioir算法中唯一的不同是,CARcandidate-gen()中,仅仅将具有相同 分类的规则项通过合并它们的条件集进行合并。 - MScandidate-gen函数利用在第(k-1)轮找到的频繁项目集集合
以上是关于关联规则的主要内容,如果未能解决你的问题,请参考以下文章