关联规则
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关联规则相关的知识,希望对你有一定的参考价值。
参考技术A 关联规则(association analysis),是一种基于规则的机器学习方法,用于发现隐藏在大型数据集中的有意义的联系。可用来寻找购物篮数据之间的联系,方便进行交叉销售;可以进行文本挖掘;也可使用在其他领域比如生物信息学、医疗诊断、地球科学等,发现一些有趣的联系。•项集:包含0个或多个项的集合,包含k个项的集合称为k-项集.例如 :Milk,Bread,Diaper
•关联规则:形如X->Y的蕴含表达式,其中X和Y是不相交的项集.例如:Milk,Diaper->Beer
•支持度(Support):表示项集X,Y在总项集里出现的概率,公式为:
•置信度(Confidence):表示X发生的情况下,由关联规则”X→Y“推出Y的概率。即在含X的项集中,含有Y的可能性,公式为:
•提升度(Lift):表示含有X的条件下含有Y的概率与Y总体发生概率之比,公式为
•频繁项集:对项目集的支持度设定一个最小阈值(minsup),所有支持度大于这个阈值的项集就是频繁项集。
对于关联规则Milk,Diaper->Beer:
机器学习算法关联规则-3 关联规则的指标问题和关联规则的使用方法
目录
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
关联规则的指标问题和关联规则的使用方法
再谈评估指标
之前不论是APriori还是FPgrowth我们都是采用支持度和置信度来作为指标,
接下来我们就要探讨一下support和confident。
支持度与置信度的问题
基本上,我们采用这两个指标的原因,是因为这两个指标是属于比较客观的衡量,我们能有量化的标准筛选标准的规则。
那么如果我们去问某个人什么样的关联规则是你喜欢的,这种比较主观的规则,一般会是unexpected 是出乎意料的,是会让使用者感觉新奇和惊讶的规则。 这种就是它感兴趣的。比如说啤酒与尿布,原本想不到的。
第二种喜欢的关联规则是,客户希望是Actionable(the user can do something with it)是可以用来做活动,行动使用到的指标。
因为人是希望要主观,但是不能量化来表示,所以后来就用支持度和置信度来作为评估。
后来提出这两个指标的一年之后,有一个人就想推翻这两个指标,如果只用这两个规则来筛选关联规则会有些问题。他举了2个例子
第一个例子是:他们学校有5000个学生,然后经过调查,其中3000个打篮球,3750个是吃麦片的,有两千个既打篮球又吃麦片。
我们就会得到下面这张表。

然后现在把支持度定为百分之30,置信度定为百分之60%
现在我们就得到第一个关联规则:打篮球——》吃麦片的关联规则:(0.4,0.667)
然后我们就想到一个活动,如果我们促销篮球,那么麦片的数量会不会增加。实际实施的时候,就会发现,促销篮球,麦片的销量不仅没有增加反而减少了
这时我们就会想玩什么会出现这种现象,明明是有这种关联规则,然后他们发现了一个问题,我们看打篮球的人里面吃麦片的比例是2/3,不打篮球吃麦片的比例是7/8.不打篮球吃麦片的比例还更高,结果我们居然得到一条关联规则,打篮球的人会去吃麦片。这样的规则反而会误导我们营销的方向。
第二个例子:
我们现在有3个产品,XYZ

现在有8笔交易,第二笔交易3笔一起购买,
我们选择定了2条关联规则x—》Y,X—》Z。
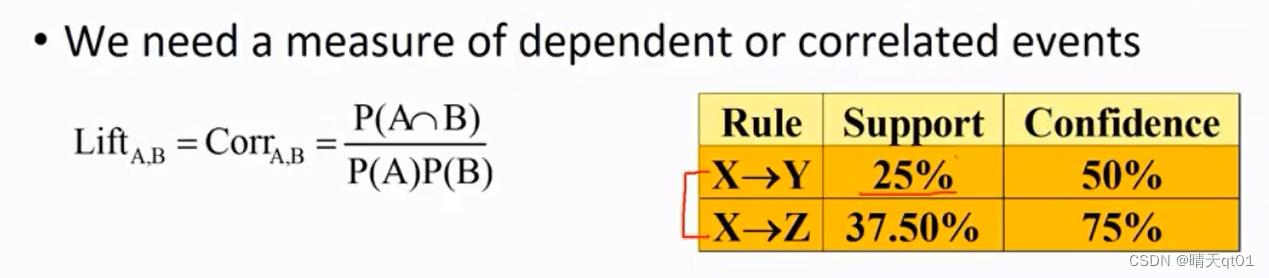
我们发现这两个关联规则xy的关联规则支持度为百分之25,也就是说8笔里有2笔同时购买,xz,的支持度是百分之37.5,也就是8笔中有3笔同时购买。卖x4次的情况下,有2次都买了y。3次买了z。
那么显著让你判断,这2条规则那个是比较想要的关联规则,是xy比较好还是xz。因为xz的支持度和置信度都比xy高,所以我们认为xz是我比较想要的关联规则。
我们回到原始数据,买x的有3个卖了z,但是4个不买x的4个都买z了,所以你认为是买了x的偏向购买z还是不买x的偏向购买z。
所以xz也是一个误导规则。。
提升度指标
所以我们定义了支持度和置信度,很容易找到误导性规则,所以我们要多看一个。叫提升度的值。这就是我们统计里面的相关系数。如果我们考虑买什么就会买什么的情况,我们还要考虑它的相关系数。相关系数就是AB一起出现的概率,除以单独A或者单独B的概率。如果这个值为1的话,那么它们就是独立事件,不会互相影响。大于1的的话就是正相关(购买A则会购买B),小于1就是负相关(购买A就不会购买B)。
所以关联规则应该要有3个指标,支持度,置信度,提升度(相关系数)只有在提升度大于1的情况下,支持度和置信度才是越高越好,不能在相关系数得出之前就认为关联规则是越高越好。我们现在来算一下第二个例子的提升度是多少。


只有在正相关的情况下,我们才需要考虑支持度和置信度,是越高越好。不然就会产生误导的关联规则。
这里XY同时出现的概率是2/8 x单独出现的概率是1/2 y单独出现的概率是2/8。提升度就是2
提升度的含义其实就是寻找二者一致的程度,x与y的数值相同的程度,其中有2个不一致,第3笔和第4笔,其他6笔数据都是一致的。所以它是正相关。
X和Z的我们计算一下结果是约等于0.9,小于1,所以是负相关,这种情况下,就不会是我们需要的关联规则。其中只有3笔数据是一致的,剩下的5笔都是不一致,是相当不一致。
Lift的值就是统计的相关系数。
关联规则的生成
关联规则的生成一般很少人提及,多数都只是讲到频繁项集。当其实关联规则的生成也是非常重要而且不简单。
举例来说。假如我们有一个频繁项集,要如何产生关联规则呢。
下面有几个方法可以参考:
Exhaustive Approach(暴力法产生所有规则,简单但是花费太多时间)
下面是我们的频繁项集。也就是支持度已经满足要求了,现在要解决的就是置信度的问题,第一种方法就是全部列举,看看它的置信度够不够,够的话就输出。
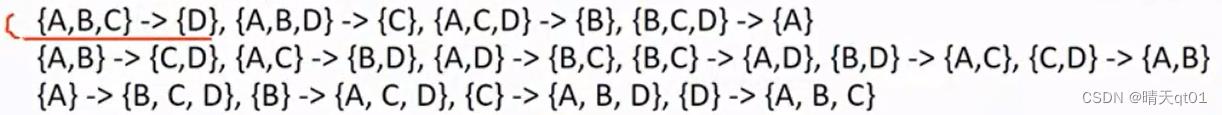
光一个ABCD需要尝试的规则就上面这么多,这种方法虽然简单,但是花费的时间非常长。
因为需要产生的规则太多,所以大多软件和套件产生的结果都是单一项的规则。

也就是只产生这4个的置信度。
所以我们会发现大多套件的右边都只会产生单一项目的关联规则。
改进策略1:
我们可以先从项多的开始产生置信度,比如ABC——》D的关联规则置信度不够,那么下面这些置信度肯定都不够,也就不需要尝试。:
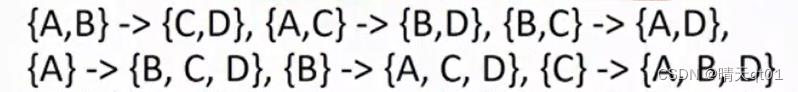
原因如下:

因为ABC——》D的置信度低于我们最小的置信度。因为这些的置信度就是ACBD的支持度除以前者的支持度。而前者的支持度一定大于或者等于ABC(比如AB和ABC,AB出现的概率肯定比ABC出现的概率高)
分母越大,置信度就越小,所以其他项目少的置信度肯定也不足。
改进策略2:
我们先产生计算项目少的置信度,如果置信度足够,那么项目多的置信度也一定足够,原理和改进策略1相同。
关联规则其实也不是很容易被产生出来。
关联规则的延伸
虚拟产品
关联规则你也可以插入一些对象,比如虚拟项目,比如我这次购买,我会添加一个在哪个位置购买的项目。比如这个商品我是在南区购买的,或者在北区购买的。那么这个店就会变成虚拟商品,进行设置关联规则。就可以得到南区的店通常会购买什么,北区的店一般会购买什么。我们就可以吧地点和商店形态一起关联起来,
还可以添加购买方式税收用信用卡,现金还是支票。一笔交易里面这些东西也可以当虚拟商品。就可以吧商品和购买方式的关联规则连接起来。
甚至你也可以吧这笔交易的星期几,上午中午下午,把这个信息和购物的关系关联到一起。
可能就会发现星期三的白天,购买什么商品就会购买什么商品的规则。
举个例子:

我们就可以发现南区的店会购买窗户清洁剂,北区的店喜欢购买果汁和苏打。
我们可以吧各自东西加入关联规则。我们就可以让关联规则出现很多变化。
负向相关规则dissociation rules
Not item-name
出现一个not的关联规则,比如买A不买B,那么就会买C,买A和D就不会买E

这种反向的信息在里面,举个例子
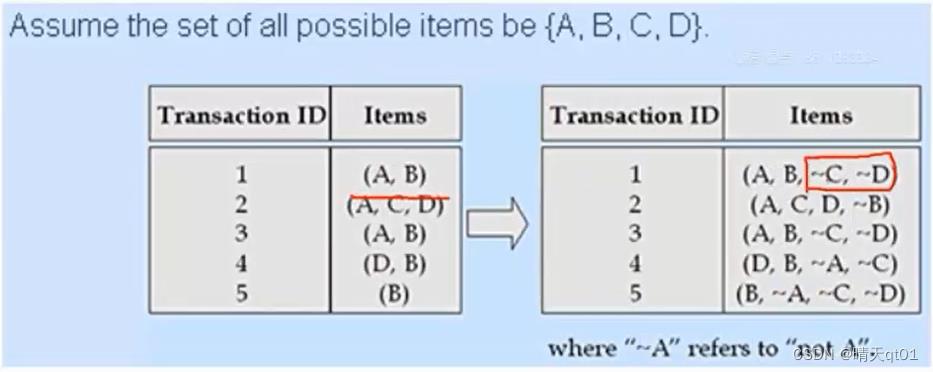
这样做的话,找到最多的规则会是,不买A不买B则不买C,因为不买的情况比较多,购买的情况比较少。如果直接这样做去找Dissociation rules结果会不理想。理想的方式就针对一些特定的商品去设定不购买的情况
加not的信息,会造成每笔交易的量变的很大。因为产品交易不是没买就买。因为没买的占多数,就是导致产生大量的not规则。
所以只有经常被购买的商品,去加入它们的not信息,这样找出的dissociation rules的比较理想。
因为当时找到啤酒与尿布
很多关联规则的有趣方向也被提出来,能不能找到空间数据的关联规则,多媒体数据的关联规则,时间序列的关联规则,加权的关联规则。
找利润比较高的关联规则,数量关系的关联规则
比如A3个就会购买B6个,把数量的关系加入。
相依性网络
下面是我们关联规则会产生的两个图,但是这两个图是比较适合机器的库,直接就可以一条一条读取,几万条的数量。

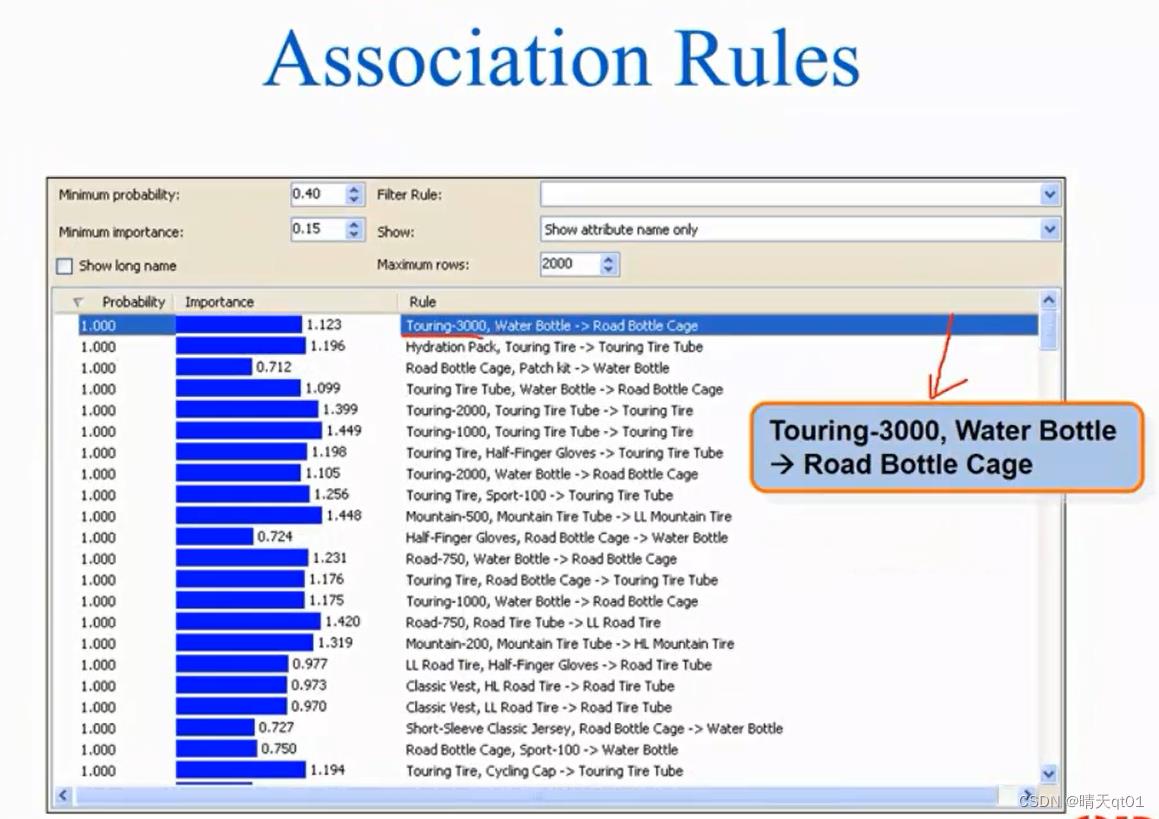
而我们人来看的神经网络,是下面这种相依性网络。
有时候我们会把长度为2的association rules画一个图
这种相依性网络可以让我们知道各产品的依赖性。假设你根据这个神经网络给人来人为做活动,我们希望有一个牺牲商品,利用这个商品的促销来促进大家购买

那么这个牺牲档商品我们就会找H商品来当牺牲档商品,由于这个商品会带动4项商品的购买,虽然我们没有在H商品上赚到钱,甚至我们把其他商品的价格提高一点。我们的结果就还是获利的。
一般商店都会推出牺牲档商品,其实他的目的不是销售这个商品,而是为了带动其他商品的销售。
所以这个网络就比较适合人来看。另外两个图片就比较适合机器来看。
总结:
我们今天讲了支持度和置信度的问题。提出的解决方法提升度指标。还说明了关联规则如何从频繁项目集产生,还有关联规则的衍生用法
以上是关于关联规则的主要内容,如果未能解决你的问题,请参考以下文章