“跟着西瓜去学习”之--绪论
Posted Zutterhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“跟着西瓜去学习”之--绪论相关的知识,希望对你有一定的参考价值。
写在前面的话:人工智能界有一种说法,认为机器学习是人工智能领域中最能够体现智能的一个分支,从历史来看,机器学习似乎也是人工智能中发展最为迅速的分支之一。Andrew Ng曾说机器学习将是未来人工智能的“电力”,可见机器学习的基础性和重要性。笔者本科在南京大学读的EE,出于对CS和人工智能的兴趣,上个学期有幸选到南京大学计算机与科学系机器学习与数据挖掘研究所(LAMDA) 的周志华老师的《机器学习》课程,但是由于时间关系,断断续续的上完了该课程,感觉好多老师讲的精髓没有好好领悟,所以这个学期旁听了周志华老师给研究生上的《高级机器学习课程》。根据周老师给大家提的机器学习方面的学习路径首先就是把他的这本西瓜书好好的看一遍,是入门比较好的方法。在重读这本书的同时,想写点读书笔记作为自己的积累和反馈,并取名叫“跟着西瓜去学习”系列,也是比较符合这本书吧~。其中相关的算法实现代码和课后习题作业我会上传至我的GitHub上,和大家一起学习交流。
基本术语
数据集(data set):数据集就是数据的集合,这里的数据是我们用来让机器学习的时间或者对象。比如我们让机器学习如何判断一个西瓜是好是坏,那么我们就需要给机器一些样本实例,告诉他们哪个是好瓜,哪个是坏瓜,这些“示例”或者“样本”组成的集合就是数据集。数据集又分为训练集和测试集。训练集是让机器用来训练的示例集合,测试集是拿来测试训练的效果好不好的示例集合。
属性(attribute)和特征(feature):反应事件或者对象在某方面的表现或者性质的事项。比如判断西瓜的好坏可以通过西瓜的“色泽”,“根蒂”,“敲声”等几个方面来判断,这些就是西瓜这个样本所具有的属性或者特征。再比如人的高矮胖瘦等也是人的属性和特征。属性张成的空间叫做“属性空间”,“样本空间”,或者“输入空间”。每一个属性都可以作为一个维度。如果一个食物拥有n个属性,那么用来描述它的便是n维空间,每一个样本都可以在这个n维空间中找到自己的坐标位置(向量),所以也把一个具体的示例叫做一个特征向量。
D = {x1,x2,....xm}表示一个包含m个示例的数据集。(注意:虽然这里的m可以用别的任何符号来代替,但是机器学习界不成文的规定默认m就是数据集里示例的个数)
xi = {xi1;xi2;.....xid}表示每个示例是d维样本空间的一个向量,其中d为样本xi的维数。
样例(example):拥有标记信息的示例称为“样例”,一般用(xi,yi)表示第i个样例,其中yi是示例xi的标记,yi组成的集合叫做标记空间或者输出空间。比如“好瓜”,“坏瓜”就是一组标记。
分类(classification):预测的是离散值,比如要预测西瓜是好瓜,坏瓜,某个人是哪个国家的人等预测结果是有限的离散值那么就是分类问题。而分类是分类问题的特例:二分类中只有正例和反例。
回归(regression):预测的是连续值,比如西瓜的成熟度0.95,0.37,预测明天的温度是27.4,30.1等连续的值叫做回归问题。
监督学习(supervised learning):训练数据有标记信息,常见的分类和回归是属于监督学习。
无监督学习(unsupervised learning):训练数据没有标记信息,聚类是属于无监督学习。
泛化(generalization):学得的模型适用于新样本的能力称作泛化能力。泛化能力是评价一个模型学习的好不好的一个标准,因为我们学习的模型的目的是为了用来判断我们未知的事物。
假设空间
归纳(induction)与演绎(deduction)是科学推理的两大基本手段。归纳是从特殊到一般的“泛化”过程,即从具体的事实归结出一般性规律。演绎是从一般到特殊的特化过程,即从基础原理推演出具体情况。从样例中学习是属于归纳的过程,也称做“归纳学习”。
我们把学习过程看成是一个在所有假设组成的空间里进行搜索的过程,搜索目标是找到与训练集匹配的假设。假设的表示一旦确定,假设空间的规模也就确定了。但是由于我们的训练集有限,所以可能有多个假设与训练集一致,即存在一个“假设集合”,称之为“版本空间”。
版本空间的示例:
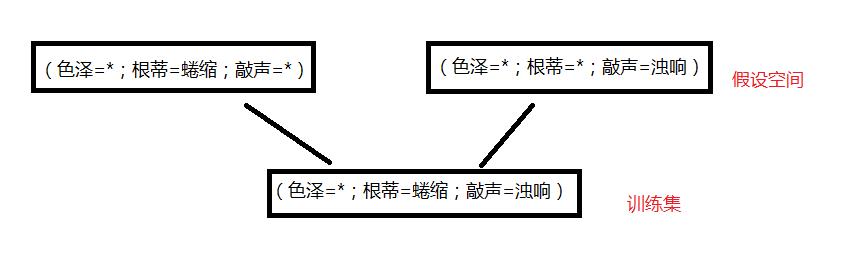
即一个训练集对应于多个假设空间。
归纳偏好
由上可以知道,如果一个训练集对应于多个假设空间,而这多个假设空间又对应于不一样的标记的话,那么这个训练集就具有奇异性,那么模型也就无法训练。就好像判断一个人是好人和坏人一样,如果让机器来判断的话,那么最终这个人一定是要么是好人要么是坏人的,不能因为从一个方面看他是好的(比如说样貌好),同时从另一个方面看他又是坏的(比如说品德坏)。所以我们要告诉机器一个偏好的归纳标准。比如说你告诉机器,一个人的人品比样貌更加重要,那么机器就会把这个样貌好品德坏的人判断为坏人。这种对某种类型假设的偏好,称作“归纳偏好”。对于不同的算法我们设置的偏好是不一样的,这个根据具体的要求具体确定。比如上面的示例,如果我们跟相信根蒂的话,那么训练集将对应于(色泽=*;根蒂=蜷缩;敲声=*)。任何一个学习算法必有其归纳偏好。
比如下面的示例图:
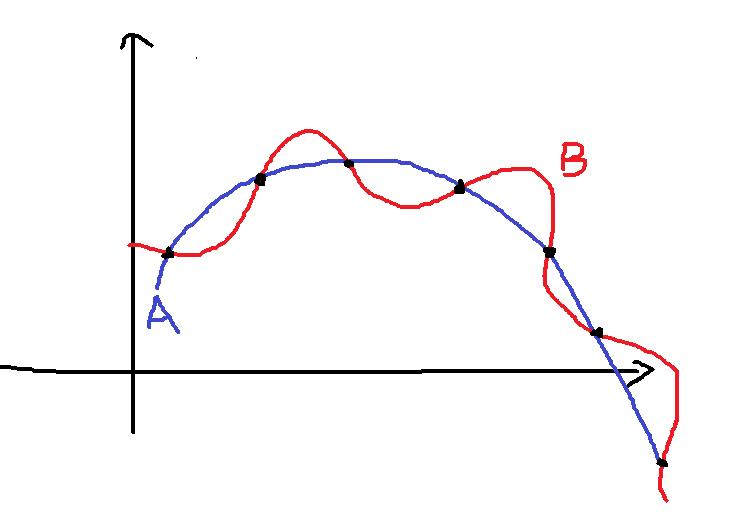
对于给定的数据集(黑色点),可以有很多的曲线满足这个样本,如A和B。如果我们认为相似的样本要有相似的输出,则模型可能更加偏好于平滑的曲线而不是曲折的曲线。这种归纳偏好可以看作是对假设空间启发式的选择。
奥卡姆剃刀(Occam\'s razor):"若有多个假设与观察一致,则选择最简单的那个。"如同上面的A和B两个曲线,根据奥卡姆剃刀原则,A比B更加平滑,对应的函数更加简单,所以选择A而不是选择B。当然,这里并不是讲奥卡姆剃刀是唯一可行的原则,只是这是科学研究中常用的、基本的原则。就好比上图中的A和B,我们根据奥卡姆剃刀原则选择了A,但是真实情况并不是一定是A,也有可能这个模型的真实的函数正好是B。所以这里又引出了一个著名的定理叫做“没有免费的午餐”定理(No Free Lunch Theorem,NFL)。
“没有免费的午餐”定理(No Free Lunch Theorem,NFL):对于一个学习算法A,若他在某些问题上比学习算法B好,那么必然存在另一些问题上,算法B要比算法A好。这个算法的具体证明在周老师的书上有详细的证明。这里找了一个证明截图:

但是不要以为所有的机器学习算法都跟胡乱瞎猜的算法一样(真是这样你也不会在这看我写博客了),NFL有一个重要的前提!这个前提是“所有的问题出现的机会相同,或者说所有的问题同等重要”。但是在我们实际解决问题中并不是这样的,在实际中我们解决的都是具体的问题,我们只关注我们自己试图解决的问题(如某个具体应用的任务),希望为他找到一个解决方案,至于这个方案在解决别的问题上好不好我们并不是很关注。打个比方,我们要乘坐交通工具,如果是从南京到北京,坐飞机是一个比较不错的选择,非常节省时间。所以方案“坐飞机”是对于问题“南京到北京”一个不错的解决方案。但是对于宿舍到校门口这个问题呢,显然坐飞机这个方案就不行了,但是对于我们想从南京去北京并不关心这个可行性。
NFL告诉我们的道理是让我们清楚的认识到,脱离实际问题,空谈“什么学习算法好是毫无意义的”,机器学习如此,人生也如此。
这是系列文章的第一篇,主要讲了一些基本的概念,如果觉得不错,请点个赞并关注后续的内容。
以上是关于“跟着西瓜去学习”之--绪论的主要内容,如果未能解决你的问题,请参考以下文章