绪论(学习笔记+公式推导)
Posted 辰chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了绪论(学习笔记+公式推导)相关的知识,希望对你有一定的参考价值。
目录
前言
本博客为博主在学习 机器学习【西瓜书 / 南瓜书】过程中的学习笔记,每一章都是对《西瓜书》、《南瓜书》内容的总结和提炼笔记,博客可以作为各位读者的辅助思考,也可以做为读者快读书籍的博文,本博客对西瓜书所涉及公式进行详细的推理以及讲解,本人认为,不推导公式所学得的知识是没有深度的,是很容易忘记的,有些公式推导起来并不复杂,只是被看似复杂的数学表达式所“吓唬”,希望大家拿上纸笔,跟着博主一起学习,一起推导。
对于哪一部分的推导不理解的,可以评论出来,博主看到之后会尽快回复!
主要符号表
下述这些符号在本书中将频繁的使用,务必牢记于心各个特殊符号所具有的的含义

🌟对上述部分定义做一下解释:
- 向量有维度,其中的元素是有序的
- 变量集是集合,集合中的元素是无序的
- 空间可以简单的理解为集合,假设空间是一个超集(全集)
- 全集的一部分被称为假设集,可以认为假设集是假设空间的一个子集
- 逗号分割:行向量
- 分号分割:列向量
- 指示函数:把逻辑空间映射成0,1进而参与运算
1.1 引言
你会判断一个西瓜是否是一颗好瓜么?
如果你不知道,那么我告诉你一个好瓜的判断条件:色泽青绿、根蒂蜷缩、敲声浊响 的瓜就是一颗好瓜,这不是我信口开河,这是我们在生活中所总结出的经验;再比如我们通过往常的学习经验可以知道:如果你刻苦学习,弄清概念,做好作业就可以取得好成绩
不难看出,我们能做出有效的判断,是因为我们积累的经验。
机器学习就是如此一门学科,它致力于通过计算的手段,利用经验来改善 系统自身的性能。
计算机有经验么?有的!对于计算机而言,经验就是 数据
根据上述两点可以知道:机器学习就是通过 数据,产生 模型(model) 的算法,所谓 模型 泛指从数据中心学得的结果;产生 模型 的算法,即 学习算法。有了 学习算法,我们只需要给它数据经验,它可以基于这些数据产生模型,在以后面对一个新的西瓜,可以判断出它是好瓜还是坏瓜。
计算机科学是研究“算法”的学问
机器学习是研究“学习算法”的学问
1.2 基本术语
💥枯燥且重要的知识来了:
我们给出几组关于西瓜的记录:
- (色泽 = 青绿;根蒂 = 蜷缩;敲声 = 浊响)
- (色泽 = 乌黑;根蒂 = 稍蜷;敲声 = 沉闷)
- (色泽 = 浅白;根蒂 = 硬挺;敲声 = 清脆)
- 数据集(data set):上述记录的集合称为数据集,数据集亦被称为一个“样本”
- 示例(instance):每条记录称为一个示例
- 属性(attribute)/ 特征(feature):如 色泽,根蒂,敲声
- 属性值(attribute value):如 青绿 蜷缩 浊响
- 属性空间(attribute space)/ 样本空间(sample space)/ 输入空间(input space):属性所张成的空间
- 特征向量(feature vector):我们把上述属性:色泽,根蒂,敲声作为坐标轴,就可以构建出一个三维空间,每个西瓜在这个空间中都可以找到自己的坐标位置,由于该空间中的每个点都对应一个坐标向量,故我们也把一个示例称为:特征向量
一般地,令 D = x1,x2,…,xm【行向量】 表示含有 m 个示例的数据集,比如上述例子中就是含有3个示例的数据集,其中每个示例都是由 d 个属性所描述,比如上述例子中每个西瓜都有3个属性:色泽,根蒂,敲声,故对于每个示例我们可以表达为:xi = xi1;xi2;…;xid【列向量】,其中 d 称为样本 xi 的 维数(dimensionality)
- 学习(learning)/ 训练(training):从数据中获得模型
- 训练数据(training data):训练过程中使用的数据
- 训练样本(training sample):每个样本都被称为训练样本
- 训练集(training set):训练样本组成的集合
- 假设(hypothesis):学得模型对应了关于数据的某种潜在规律,故亦被称为假设
- 真相 / 真实(ground-truth):指这种潜在的规律的自身
- 学习器(leaner):就是模型,可看作学习算法在给定数据和参数空间上的实例化
假设就是模型,映射就是模型
假设要逼近真相
我们使用我们的数据集去构造一个假设并且我们希望这个假设是逼近真相的
假设并不唯一,比如我从北京到上海:我可以开车,高铁,飞机,步行;我们的目的是在一系列假设之中,按照相关的要求去选择一个“好”的假设
🌟还记得我们的 “初心” 么?判断一个瓜是否为好瓜,显然我们光有示例数据是远远不够的,我们还需要训练样本的结果信息来建立关于 预测(prediction) 的模型,例如:((色泽 = 青绿;根蒂 = 蜷缩;敲声 = 浊响),好瓜),在这里关于示例结果的信息:好瓜,被称为 标记(label) 拥有了标记信息的示例,则被称为 样例(example)
示例 + 标记 = 样例
一般地,用(xi,yi)表示第 i 个样例,其中 yi ∈ 𝓨 是示例 xi 的标记,𝓨 是所有标记的集合,亦被称为 标记空间(label space)/ 输出空间(output space)
(xi, yi):(向量,标量)
- 分类(classification):预测离散值如:好瓜坏瓜的学习任务
- 回归(regression):预测连续值如:西瓜的成熟度 0.95、0.37 的学习任务
yi是离散:分类
yi是连续:回归
对于只涉及两个类别的 二分类(binary classification) 任务,称其中的一个类为 正类(positive class),另一个类为 反类(negative class),亦被称为 反类
所谓二分类:就是判断是和不是:是否为好瓜,是否为三好学生
在定义“正类”和“反类”(负类)时,我们既可以把好瓜定义为“正类”也可以把好瓜定义为“反类”(负类),这里的正反仅仅是用来起到区分的作用,并不涉及好坏之差
涉及多个类别时,被称为 多分类(multi-class classification)
预测任务是希望通过对训练集(x1,y1),(x2,y2),…,(xm,ym) 进行学习,建立一个从输入空间 𝓧 到输出空间 𝓨 的映射 f :𝓧 → 𝓨 ,对于二分类的任务,我们通常令:𝓨 = -1, +1 或 0, 1;对于多分类任务 |𝓨 | > 2;对于回归任务,𝓨 = R,R为实数集
- 测试(clustering):学得模型之后,使用其进行预测的过程
- 测试样本(testing sample):被预测的样本
例如,在学得 f 后,对测试例 x,可得到测试标记 y = f(x)
❗️ 注意:并不是所有的数据都有标签:yi 的,对于没有 yi 的数据,我们就不能对其进行探索了么?非也:我们可以对数据做“聚类”
- 聚类(clustering):将训练集中的西瓜分组
- 簇(cluster):分成的组,每组被称为一个簇
这些自动形成的簇可能对应一些潜在的概念划分,例如:“浅色瓜”,“深色瓜”;甚至“本地瓜”,“外地瓜”。这样的学习过程有助于我们了解数据的内在规律。在聚类学习中,“浅色瓜”,“深色瓜” 这样的概念是我们事先不知道的,而且在学习过程中使用的训练样本通常是不拥有标记信息的
根据训练数据 是否拥有标记信息 可分为:
- 监督学习(supervised learning)
- 无监督学习(unsupervised learning)
分类和回归是监督学习的代表
聚类是无监督学习的代表
⭐️机器学习的目标是使学得的模型能很好地适用于新样本,而不仅仅是在训练样本上工作的更好
- 泛化(generalization)能力:学得模型适用于新样本的能力
具有强泛化能力的模型能很好地适用于整个样本空间,于是,尽管训练集通常只是样本空间的一个很小的采样,我们仍希望它能够很好地反映出样本空间的特征。
通常假设样本空间中全体样本服从一个未知 分布(distribution)𝓓
我们获得的每个样本都是独立地从这个分布上采样获得的,即 独立同分布(independent and identically distributed,简称 i.i.d.)
一般来说,训练样本越多,我们得到的关于 𝓓 的信息越多,这样就越有可能通过学习获得具有 强泛化能力 的模型.
1.3 假设空间
科学推理的两大基本手段:归纳(induction),演绎(deduction)
所谓归纳,就是由特殊到一般的 泛化(generalization) 过程
所谓演绎,就是由一般到特殊的 特化(inductive learning) 过程
归纳学习:
广义:从样例中学习
狭义:从训练数据中学得 概念(concept),因此亦被称为 概念学习 或 概念形成
现实常用的技术大多是产生 黑箱 模型
概念学习中最基本的是布尔概念学习,即 是,不是 这样的可表示 0/1 布尔值的目标概念的学习
我们可以把学习过程看作是一个在所有假设组成的空间中进行搜索的过程,搜索目标则是找到与训练集 匹配(fit) 的假设;假设的表示一旦确定,假设空间及规模大小就确定了
可以有很多的策略对假设空间进行搜索,例如:自顶向下、从一般到特殊、自底向上、从特殊到一般,搜索过程中可以不断删除与正例不一致的假设、和(或)与反例一致的假设,最终将会获得与训练集一致(即堆所有训练样本能够进行正确判断)的假设。
❗️ 注意:可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为 版本空间(version space)
1.4 归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为 归纳偏好(inductive bias),或简称为:偏好
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上“等效”的假设所迷惑,而无法产生确定的学习结果
还是拿西瓜举例子,判断一个好瓜,到底是 根蒂 重视还是对 敲声 更重视,这是对属性进行选择,被称为 特征选择(feature selection),机器学习中的特征选择仍是基于对训练样本的分析进行的,这里对某种属性的信赖可视为基于某种领域知识而产生的归纳偏好
归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或价值观
💥重点来喽:
奥卡姆剃刀(Ocam’s razor) 是一种常用的、自然科学研究中 最基本 的原则,即:如有多个假设与观察一直,则选最简单的那个。
然而,奥卡姆剃刀并非唯一可行的原则,奥卡姆剃刀本身存在不同的诠释,使用奥卡姆剃刀原则并不平凡,或者你可以理解为:在如何判断 简单 这个问题上,并不简单。
归纳偏好对应了学习算法本身做出的关于“什么样的模型更好”的假设,这个假设是否成立,即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法是否能取得好的性能。
对于下图而言:
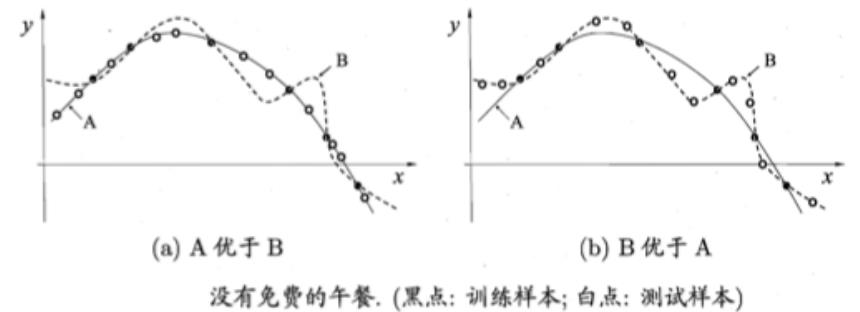
对于两股曲线,你可以想当然的认为曲线A是更平滑的,即更简单的,我们期待 𝓛a 比 𝓛b 更好,确实,图(a)显示出,与 B 相比,A 与训练集外的样本更一致;换言之,A 的泛化能力比 B 强。
But !,对于图(b)而言,我们又可以直观的感受到 𝓛b 比 𝓛a 更好
换言之,对于一个学习算法 𝓛a,若它在某些问题上比 𝓛b 好,则必然存在另一些问题,在那里 𝓛b 比 𝓛a 好,我们接下来去证明它:
我们设样本空间𝓧,假设空间𝓗都是离散的,令 P(h|X, 𝓛a) 代表算法 𝓛a 基于训练数据 X 产生假设 h 的概率,再令 f 代表我们希望学习的真实目标函数 . 𝓛a 的“训练集外误差”,即 𝓛a 在训练集之外的所有样本上的误差为:
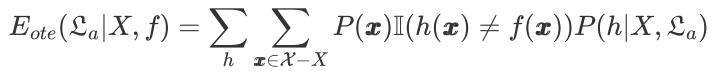
公式说明,首先两个求和符号的解释:我们最终的结果是 产生 h 的所有情况的和,并且我们的训练集外的样本空间为:𝓧 - X,要考虑所有情况故也需要求和,P(h|X, 𝓛a) 是基于训练数据产生假设 h 的概率,即对于每一个 h 都对应一个概率 P(h|X, 𝓛a) ,从训练集外所有的样本中挑选 𝔁 的概率为: P(𝔁) ,这时我们已经挑选了一个 𝔁 ,我们需要把 𝔁 分别带入到 h(𝔁) 和 f(𝔁) 中,去比较实际值和估计值是否相等,不相等运算结果为 P(𝔁) * 1 * P(h|X, 𝓛a) ,相等运算结果为 P(𝔁) * 0 * P(h|X, 𝓛a) ,最终按照前述求和即可。
接下来我们来考虑二分类问题:且真实目标函数可以是任何函数 𝓧 → 0,1,函数空间为0,1|𝓧|,对所有可能的 f 按 均匀分布 对误差求和,有:
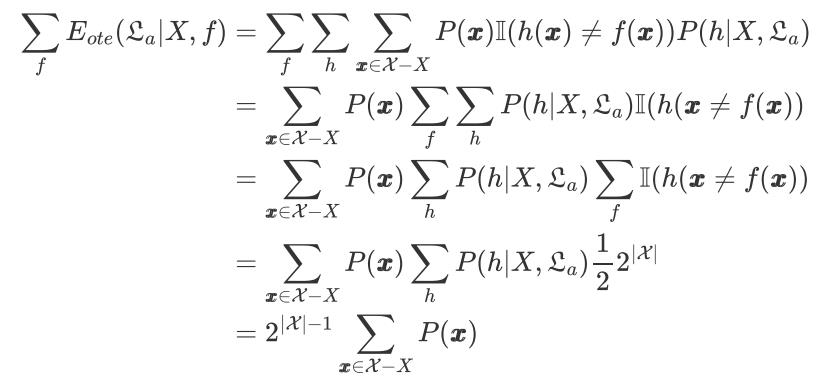
公式说明:从公式的第一行到公式的第二行,就是把第一个公式进行带入的结果,然后从第二行到第三行,则是类似量词辖域收缩扩张公式的推导,从公式第三行到第四行,我们进行举例讲解:
首先我们需要知道此时假设 f 是任何能将样本映射到 0,1的函数,存在不止一个 f 时, f 服从 均匀分布 ,即对于每个 f 出现的概率都是相等的,假设我们的样本空间只有两个样本时, 𝓧 = x1,x2,| 𝓧 | = 2,那么所有可能的真实目标函数 f 如下:
f1 : f1(x1) = 0,f1(x2) = 0;
f2 : f2(x1) = 0,f2(x2) = 1;
f3 : f3(x1) = 1,f3(x2) = 0;
f4 : f4(x1) = 1,f4(x2) = 1;
一共有 2|𝓧| = 22 = 4 个可能的真实目标函数,所以此时通过算法 𝓛a 学习出来的模型 h(x) 对于每个样本无论预测值是 0 或是 1,都必然有且只有一半的 f 与它的预测值相等, ∑ f I ( h ( x ) ≠ f ( x ) ) \\sum_fI(h(x) ≠ f(x)) ∑fI(h(x)=f(x)) = 1 2 \\frac12 21 2|𝓧|
从最终得到的式子中我们可以发现:总误差与学习算法无关,训练集外误差仅和数据集本身,数据集取得集外数据xi的概率相关,和算法La无关 → 训练集外的误差和算法所构建的模型没有关系,故我们对于任意的两个学习算法 𝓛a 和 𝓛b,我们都有:
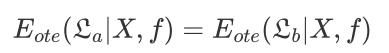
也就是说,无论学习算法 𝓛a 多么的聪明, 𝓛b 多么的笨拙,它们的期望值是始终相同的,这就是 “没有免费的午餐”定理(No Free Lunch Theorem),简称 NFL定理
❗️ NFL 定理有一个重要的前提:所有问题出现的机会相同或所有问题同等重要,即我们假设了f 服从 均匀分布 ,但是实际生活中并不是这样,很多时候,我们只关注自己正在试图解决的问题(例如某个具体应用任务),希望为它找到一个解决方案,至于这个解决方案在别的问题,甚至在相似的问题上是否为好方案,我们并不关心。就拿推导过程中的 f1 f2 f3 f4 举例,通常我们只认为能高度拟合已有样本数据的函数才是真实目标函数,例如,现在已有的样本数据为(x1,0),(x2,1),那么此时只有 f2 才是我们认为的真实目标函数,由于没有收集到或者根本不存在 (x1,0),(x2,0),(x1,1),(x2,0),(x1,1),(x2,1) 这类样本,所以 f1 f3 f4 都不算是真实的目标函数。
🌟 所以,NFL 定理最重要的寓意,是让我们认识到:脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好,要谈论算法的相对优劣,必须针对 具体 的学习问题,在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否匹配,往往会起到决定性作用。
1.5 发展历程,1.6 应用现状,是对后续内容的大概简说,这里不做总结,后续内容会有详解。
以上是关于绪论(学习笔记+公式推导)的主要内容,如果未能解决你的问题,请参考以下文章