中文词频统计
Posted 097吴嘉玲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文词频统计相关的知识,希望对你有一定的参考价值。
中文分词
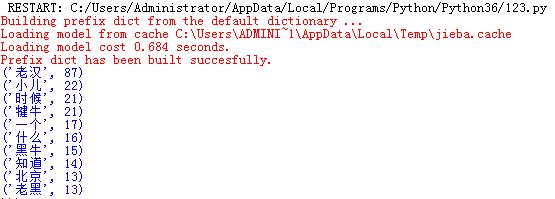
- 下载一中文长篇小说,并转换成UTF-8编码。
- 使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
- 排除一些无意义词、合并同一词。
- 对词频统计结果做简单的解读。
import jieba txt=open(\'111.txt\',\'r\',encoding=\'utf-8\').read() words=list(jieba.cut(txt)) keys=set(words) dic={} for w in keys: if len(w)>1: dic[w]=words.count(w) wc=list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) for i in range(10): print(wc[i])
以上是关于中文词频统计的主要内容,如果未能解决你的问题,请参考以下文章