机器学习算法之 KNN(k最近算法)
Posted 眷恋你的方圆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法之 KNN(k最近算法)相关的知识,希望对你有一定的参考价值。
KNN算法
存在一个训练样本集合,里面有n个训练数据,每个训练数据有m个特征。每个训练数据都标明了相对应的分类。比如:

其中一条数据有四个特征:体重,翼展等,也有相对应的种属。
则KNN算法就是将一条未知种属的数据的每个特征与训练样本集合中的每条数据对应的特征进行比较,然后算法提取样本集合特征最相似数据(最近邻)的分类标签。一般选择样本数据集合中前K个最相似的数据,这就是K-近邻算法中k的出处。
最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
(可以大概理解为将一条数据与样本中每条数据都比较一遍,然后计算出与每条样本数据的距离,然后选出来K个距离最近的样本,看看这k个样本都是属于哪一类的,哪一类最多,那这个未知的数据也属于这个样本)。

KNN算法实现:
创建KNN.文件
先写下训练样本(举个例子)
1 # -*- coding: utf-8 -*- 2 import numpy as np 3 import operator 4 def createDataSet(): 5 group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #训练样本数据 6 labels = [\'A\',\'A\',\'B\',\'B\'] #每条训练样本数据对用的标签 7 return group, labels
使用欧式距离公式,计算目标数据和训练数据的距离
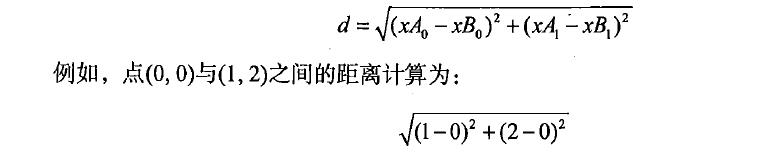
如果数据集存在四个特征值,则点(1,0,0,1)与点(7,6,9,4)间的距离为:
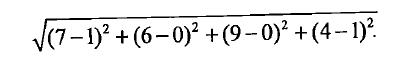
K-近邻算法实现:
1 def classify0(inX,dataSet,labels,k): 2 dataSetsize = dataSet.shape[0] #shape[0]获取矩阵的行数,shape[1]获取矩阵的列数 3 diffMat = np.tile(inX,(dataSetsize,1)) - dataSet #tile函数是将inX复制成dataSetsize行,1列,这行求的是目标数据与每条训练数据集间的差值 4 sqDiffMat = diffMat**2 #对diffMat矩阵中每个值求平方 5 sqDistances =sqDiffMat.sum(axis = 1) #axis=0表示按列相加,axis=1表示按照行的方向相加 6 distances = sqDistances**0.5 #开根号 7 sortedDistIndicies = distances.argsort()#将distances中的元素从小到大排列,提取其对应的index(索引),然后输出到y,比如y[0]存的是distances中数值最小数的索引 8 classCount = {} #定义一个字典类型数据 9 for i in range(k): 10 voteIlabel = labels[sortedDistIndicies[i]] #将前k个最小数值对应的标签提取出来 11 classCount[voteIlabel] = classCount.get(voteIlabel,0) +1 #统计k个元素中每个标签出现的次数 12 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse=True) #逆排序,按照每个标签统计的个数从大到小次序排序,要明白里面几个函数的意思 13 return sortedClassCount[0][0] #返回发生频率最高的元素标签 14
来个测试程序,创建一个test.py文件
# -*- coding: utf-8 -*- import KNN group,labels = KNN.createDataSet() print (KNN.classify0([0,0],group,labels,3))
输出结果就是:

一个简单的KNN算法实现就完成了,虽然没有太大的实际用处,但是也构造出了第一个分类器。
以上是关于机器学习算法之 KNN(k最近算法)的主要内容,如果未能解决你的问题,请参考以下文章