最大信息系数(MIC)——Detecting Novel Associations in Large Data Sets
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最大信息系数(MIC)——Detecting Novel Associations in Large Data Sets相关的知识,希望对你有一定的参考价值。
本文介绍了一种发现两个随机变量之间依赖关系强度的度量MIC(最大信息系数,类似于相关系数的作用)。MIC具有以下性质和优势:
MIC度量具有普适性。其不仅可以发现变量间的线性函数关系,还能发现非线性函数关系(指数的,周期的);不仅能发现函数关系,还能发现非函数关系(比如函数关系的叠加,或者有趣的图形模式)。
MIC度量具有均衡性。对于相同噪声水平的函数关系或者非函数关系,MIC度量具有近似的值。所以MIC度量不仅可以用来纵向比较同一相关关系的强度,还可以用来横向比较不同关系的强度。
MIC度量计算的方法。具有两个属性的数据点的集合分布在两维的空间中,使用m乘以n的网格划分数据空间,使落在第(x,y)格子中的数据点的频率作为P(x,y)的估计即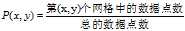 ,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,
,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,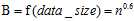 。将MIC的计算过程概括为公式为:
。将MIC的计算过程概括为公式为: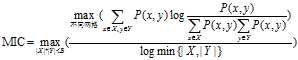
总之,MIC度量在本质上是基于互信息的。
本论文首先通过仿真实验来验证MIC的有效性。首先生成具有特定函数关系的二维数据点,然后在数据上添加不同程度的垂直的,均匀分布的随机噪声。使用这种方法生成了不同关系类型和不同噪声程度的数据集。然后在这组数据集上,综合比较了MIC和其它的一些方法,得出MIC度量更具有普适性和均衡性的结论。
作者在MIC的基础上又提出了几种度量。包括检测反单调性的MAS,检测非线性的MIC-ρ2等。
然后,作者在几组高维的公开数据集上测试了MIC度量,这些数据集已经被广泛的研究,已经被发现了很多有价值的著名的变量关系。这些数据集包括来自世界卫生组织的社会,经济,健康和政治指标数据;酵母菌基因表达数据;棒球联赛的统计数据。在来自WHO的数据中,发现了一些有趣的非线性关系(指数关系,抛物线,重叠函数关系等);在酵母菌基因表达数据中,使用MIC度量的变体:MAS度量,发现了几组有趣的周期模式;在人体肠道细菌丰度数据集中,发现了影响肠道细菌特异性的因素。
我在读完论文的正文部分之后,阅读了一部分论文的补充资料,里面有对论文更详细的解释。然后,我在网上找到了MIC度量的软件工具:R语言包minerva,并尝试了一下论文中的部分仿真实验。结果发现,随着B参数的增大,MIC度量总是趋近于1,这与补充资料中看到的资料一致。接下来我打算仔细阅读一下补充资料中关于算法实现的部分。
论文链接:http://science.sciencemag.org/content/334/6062/1518.full
软件下载:http://www.exploredata.net/Downloads/MINE-Application
以上是关于最大信息系数(MIC)——Detecting Novel Associations in Large Data Sets的主要内容,如果未能解决你的问题,请参考以下文章
机器学习案例三:数据降维与相关性分析(皮尔逊(Pearson),二维相关性分析(TDC),灰色关联分析,最大信息系数(MIC))
R语言使用pastecs包的stat.desc函数计算dataframe数据字段的描述性统计信息(样本个数NULL值个数缺失值个数最小最大值均值中位数数据范围极差加和变异系数整体性等
解决谷歌云 ssh 登录权限被拒的问题 google cloud (publickey,gssapi-keyex,gssapi-with-mic)