特征选择
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征选择相关的知识,希望对你有一定的参考价值。
参考技术A特征选择主要的两个功能:
pearson Correlation :皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间线性相关性,结果取值区间为[-1,1],-1表示完全地负相关,+1表示完全地正相关,0表示没有线性相关。
互信息和最大信息系数(Mutual information and maximal information coefficient)
想把互信息直接用于特征选择其实不太方便:
最大信息系数克服了这两个问题,它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]
ps: MIC的统计能力遭到了一些质疑,当零假设不成立时,MIC的统计就会受到影响。在有的数据集上不存在这个问题,但有的数据集上就存在这个问题。
距离相关系数法(Distance correlation)
距离相关系数是为了克服Pearson相关系数的弱点而生的,即使Pearson相关系数是0,我们也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关系数是0,那么我们就可以说这两个变量时独立的。
尽管有MIC和距离相关系数在了,但当变量之间的关系接近线性相关的时候,Pearson相关系数任然是不可替代的。第一、Pearson相关系数计算速度快,这在处理大规模数据的时候很重要;第二、Pearson相关系数的取值区间是[-1,1],而MIC和距离系数都是[0,1],这个特点使得Pearson相关系数能够表征更丰富的关系,符号表示关系的正负,绝对值能够表示强度。当然,Pearson相关性有效的前提是两个变量的变化关系的单调的。
基于学习模型的特征排序(Model based ranking)
如何用回归模型的系数来选择特征,越是重要的特征在模型中对应的系数就会越大,而跟输出变量越是无关的特征对应的系数就会越接近于0,在噪音不多的数据上,或者是数量远远大于特征数的数据上,如果特征之间相对来说是比较独立的,那么即使是运用最简单的线性回归模型也一样能取得非常好的效果。
正则化
正则化就是把额外的约束或者惩罚项加到已有模型(损失函数)上,以防止过拟合并提高泛化能力。
L1正则化和L2正则化也称为Lasso和Ridge
L1正则化(Lasso)
L1正则化将系数w的L1范数作为惩罚项加到顺势函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变为0,因为L1正则化往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化作为一种很好地特征选择方法。
L1正则化非正则化线性模型一样也是不稳定的,如果特征集合中具有相关联的特征,当数据发生细微变化时也有可能导致很大的模型差异。
L2正则化(Ridge regression)
L2正则化将系数向量的L2范数添加到了损失函数中。由于L2惩罚项中系数是二次方的,这使得L2和L1有着诸多差异,最明显的一点就是,L2正则化会让系数的取值变得平均。对于关联特征,这意味着他们能够获得更相近的对应系数。还是以Y=X1+X2为例,假设X1和X2具有很强的关联,如果用L1正则化,不论学到的模型是Y=X1+X2还是Y=2X1,惩罚都是一样的,都是2alpha。但是对于L2来说,第一个模型的惩罚项是2alpha,但第二个模型的是4*alpha。可以看出,系数之和为常数时,各系数相等时惩罚是最小的,所以才有了L2会让各个系数趋于相同的特点。
可以看出,L2正则化对于特征选择来说一种稳定的模型,不像L1正则化那样,系数会因为细微的数据变化而波动。所以L2正则化和L1正则化提供的价值是不同的,L2正则化对于特征理解来说更加有用:表示能力强的特征对应的系数是非零。
随机森林具有准确率高、鲁棒性好、易于使用等优点,这使得它成为了目前最流行的机器学习算法之一。随机森林提供了两种特征选择的方法:mean decrease impurity 和 mean decrease accuracy。
平均不纯度减少(mwan decrease impurity)
随机森林由多个决策树构成。决策树中每一个节点都是关于某一个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度,对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
这里特征得分实际上采用的是Gini Importance。使用基于不纯度的方法的时候,要记住:1.这种方法存在偏向,对具有更多类别的变量会更有利;2.对于存在关联的多个特征,其中任意一个都可以作为指示器(优秀的特征),并且一旦某个特征被选择之后,其他特征的重要程度会急剧下降,因为不纯度已经被选中的哪个特征降下来了,其他的特征就很难再降低那么多不纯度了,这样一来,只有先被选中的那个特征很重要,而其余的特征是不重要的,但实际上这些特征对响应变量的作用确定非常接近的。
平均精确率减少(Mean decrease accuracy)
特征选择方法就是直接度量每个特征对模型精确度的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
建立在基于模型的特征选择方法基础之上的,例如回归和SVM,在不同的子集上建立模型,然后汇总最终确定特征得分。
稳定性选择(Stability selection)
稳定性选择是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归,SVM或者类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果。比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想的情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非零的数,而最无用的热证得分将会接近于0.
sklearn在随机lasso和随机逻辑回归中有对稳定性选择的实现。
递归特征消除(Recursive feature elimination RFE)
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了,这个过程中特征被消除的次序就是特征的排序,因此,这是一种寻找最优特征子集的贪心算法。
RFE的稳定性很大程度上取决于在迭代的时候底层采用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的,假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
Sklearn提供了RFE包,可以用于特征消除,还提供了RFECV,可以通过交叉验证来对特征进行排序。
特征选择常用算法
下载数据分析更多资料
1 综述
(1) 什么是特征选择
特征选择 ( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ) ,或属性选择( Attribute Selection ) ,是指从全部特征中选取一个特征子集,使构造出来的模型更好。
(2) 为什么要做特征选择
在机器学习的实际应用中,特征数量往往较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
特征个数越多,分析特征、训练模型所需的时间就越长。
特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
特征选择能剔除不相关(irrelevant)或亢余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化了模型,使研究人员易于理解数据产生的过程。
2 特征选择过程
2.1 特征选择的一般过程
特征选择的一般过程可用图1表示。首先从特征全集中产生出一个特征子集,然后用评价函数对该特征子集进行评价,评价的结果与停止准则进行比较,若评价结果比停止准则好就停止,否则就继续产生下一组特征子集,继续进行特征选择。选出来的特征子集一般还要验证其有效性。
综上所述,特征选择过程一般包括产生过程,评价函数,停止准则,验证过程,这4个部分。
(1) 产生过程( Generation Procedure )
产生过程是搜索特征子集的过程,负责为评价函数提供特征子集。搜索特征子集的过程有多种,将在2.2小节展开介绍。
(2) 评价函数( Evaluation Function )
评价函数是评价一个特征子集好坏程度的一个准则。评价函数将在2.3小节展开介绍。
(3) 停止准则( Stopping Criterion )
停止准则是与评价函数相关的,一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索。
(4) 验证过程( Validation Procedure )
在验证数据集上验证选出来的特征子集的有效性。
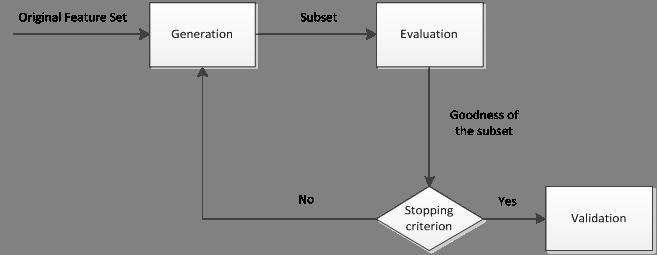
图1. 特征选择的过程 ( M. Dash and H. Liu 1997 )
2.2 产生过程
产生过程是搜索特征子空间的过程。搜索的算法分为完全搜索(Complete),启发式搜索(Heuristic),随机搜索(Random) 3大类,如图2所示。
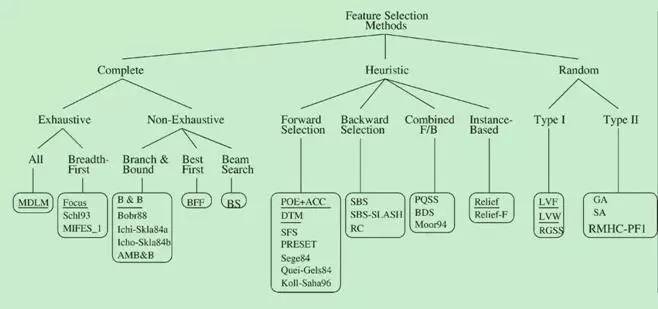
图2. 产生过程算法分类 ( M. Dash and H. Liu 1997 )
下面对常见的搜索算法进行简单介绍。
2.2.1完全搜索
完全搜索分为穷举搜索(Exhaustive)与非穷举搜索(Non-Exhaustive)两类。
(1) 广度优先搜索( Breadth First Search )
算法描述:广度优先遍历特征子空间。
算法评价:枚举了所有的特征组合,属于穷举搜索,时间复杂度是O(2n),实用性不高。
(2)分支限界搜索( Branch and Bound )
算法描述:在穷举搜索的基础上加入分支限界。例如:若断定某些分支不可能搜索出比当前找到的最优解更优的解,则可以剪掉这些分支。
(3) 定向搜索 (Beam Search )
算法描述:首先选择N个得分最高的特征作为特征子集,将其加入一个限制最大长度的优先队列,每次从队列中取出得分最高的子集,然后穷举向该子集加入1个特征后产生的所有特征集,将这些特征集加入队列。
(4) 最优优先搜索 ( Best First Search )
算法描述:与定向搜索类似,唯一的不同点是不限制优先队列的长度。
2.2.2 启发式搜索
(1)序列前向选择( SFS , Sequential Forward Selection )
算法描述:特征子集X从空集开始,每次选择一个特征x加入特征子集X,使得特征函数J( X)最优。简单说就是,每次都选择一个使得评价函数的取值达到最优的特征加入,其实就是一种简单的贪心算法。
算法评价:缺点是只能加入特征而不能去除特征。例如:特征A完全依赖于特征B与C,可以认为如果加入了特征B与C则A就是多余的。假设序列前向选择算法首先将A加入特征集,然后又将B与C加入,那么特征子集中就包含了多余的特征A。
(2)序列后向选择( SBS , Sequential Backward Selection )
算法描述:从特征全集O开始,每次从特征集O中剔除一个特征x,使得剔除特征x后评价函数值达到最优。
算法评价:序列后向选择与序列前向选择正好相反,它的缺点是特征只能去除不能加入。
另外,SFS与SBS都属于贪心算法,容易陷入局部最优值。
(3) 双向搜索( BDS , Bidirectional Search )
算法描述:使用序列前向选择(SFS)从空集开始,同时使用序列后向选择(SBS)从全集开始搜索,当两者搜索到一个相同的特征子集C时停止搜索。
双向搜索的出发点是 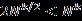 。如下图所示,O点代表搜索起点,A点代表搜索目标。灰色的圆代表单向搜索可能的搜索范围,绿色的2个圆表示某次双向搜索的搜索范围,容易证明绿色的面积必定要比灰色的要小。
。如下图所示,O点代表搜索起点,A点代表搜索目标。灰色的圆代表单向搜索可能的搜索范围,绿色的2个圆表示某次双向搜索的搜索范围,容易证明绿色的面积必定要比灰色的要小。
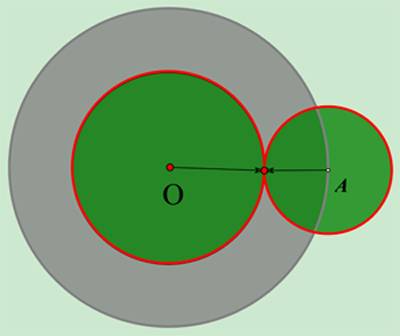
图2. 双向搜索
(4) 增L去R选择算法 ( LRS , Plus-L Minus-R Selection )
该算法有两种形式:
<1> 算法从空集开始,每轮先加入L个特征,然后从中去除R个特征,使得评价函数值最优。( L > R )
<2> 算法从全集开始,每轮先去除R个特征,然后加入L个特征,使得评价函数值最优。( L < R )
算法评价:增L去R选择算法结合了序列前向选择与序列后向选择思想, L与R的选择是算法的关键。
(5) 序列浮动选择( Sequential Floating Selection )
算法描述:序列浮动选择由增L去R选择算法发展而来,该算法与增L去R选择算法的不同之处在于:序列浮动选择的L与R不是固定的,而是“浮动”的,也就是会变化的。
序列浮动选择根据搜索方向的不同,有以下两种变种。
<1>序列浮动前向选择( SFFS , Sequential Floating Forward Selection )
算法描述:从空集开始,每轮在未选择的特征中选择一个子集x,使加入子集x后评价函数达到最优,然后在已选择的特征中选择子集z,使剔除子集z后评价函数达到最优。
<2>序列浮动后向选择( SFBS , Sequential Floating Backward Selection )
算法描述:与SFFS类似,不同之处在于SFBS是从全集开始,每轮先剔除特征,然后加入特征。
算法评价:序列浮动选择结合了序列前向选择、序列后向选择、增L去R选择的特点,并弥补了它们的缺点。
(6) 决策树( Decision Tree Method , DTM)
算法描述:在训练样本集上运行C4.5或其他决策树生成算法,待决策树充分生长后,再在树上运行剪枝算法。则最终决策树各分支处的特征就是选出来的特征子集了。决策树方法一般使用信息增益作为评价函数。
2.2.3 随机算法
(1) 随机产生序列选择算法(RGSS, Random Generation plus Sequential Selection)
算法描述:随机产生一个特征子集,然后在该子集上执行SFS与SBS算法。
算法评价:可作为SFS与SBS的补充,用于跳出局部最优值。
(2) 模拟退火算法( SA, Simulated Annealing )
模拟退火算法可参考 。
算法评价:模拟退火一定程度克服了序列搜索算法容易陷入局部最优值的缺点,但是若最优解的区域太小(如所谓的“高尔夫球洞”地形),则模拟退火难以求解。
(3) 遗传算法( GA, Genetic Algorithms )
算法描述:首先随机产生一批特征子集,并用评价函数给这些特征子集评分,然后通过交叉、突变等操作繁殖出下一代的特征子集,并且评分越高的特征子集被选中参加繁殖的概率越高。这样经过N代的繁殖和优胜劣汰后,种群中就可能产生了评价函数值最高的特征子集。
随机算法的共同缺点:依赖于随机因素,有实验结果难以重现。
2.3 评价函数
评价函数的作用是评价产生过程所提供的特征子集的好坏。
评价函数根据其工作原理,主要分为筛选器(Filter)、封装器( Wrapper )两大类。
筛选器通过分析特征子集内部的特点来衡量其好坏。筛选器一般用作预处理,与分类器的选择无关。筛选器的原理如下图3:
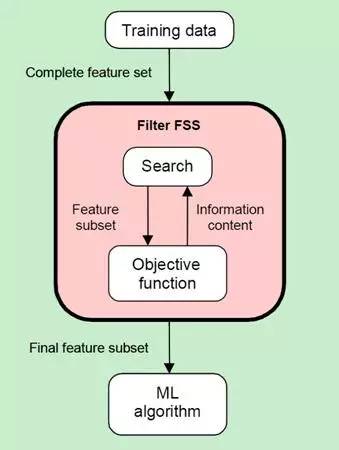
图3. Filter原理(Ricardo Gutierrez-Osuna 2008 )
封装器实质上是一个分类器,封装器用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准。封装器的原理如图4所示。
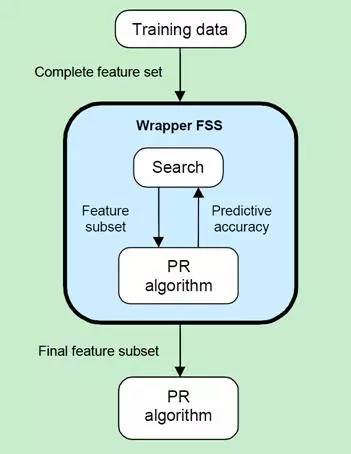
图4. Wrapper原理 (Ricardo Gutierrez-Osuna 2008 )
下面简单介绍常见的评价函数。
(1) 相关性( Correlation)
运用相关性来度量特征子集的好坏是基于这样一个假设:好的特征子集所包含的特征应该是与分类的相关度较高(相关度高),而特征之间相关度较低的(亢余度低)。
可以使用线性相关系数(correlation coefficient) 来衡量向量之间线性相关度。
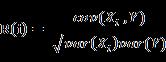
( 2) 距离 (Distance Metrics )
运用距离度量进行特征选择是基于这样的假设:好的特征子集应该使得属于同一类的样本距离尽可能小,属于不同类的样本之间的距离尽可能远。
常用的距离度量(相似性度量)包括欧氏距离、标准化欧氏距离、马氏距离等。
(3) 信息增益( Information Gain )
假设存在离散变量Y,Y中的取值包括{y1,y2,....,ym} ,yi出现的概率为Pi。则Y的信息熵定义为:

信息熵有如下特性:若集合Y的元素分布越“纯”,则其信息熵越小;若Y分布越“紊乱”,则其信息熵越大。在极端的情况下:若Y只能取一个值,即P1=1,则H(Y)取最小值0;反之若各种取值出现的概率都相等,即都是1/m,则H(Y)取最大值log2m。
在附加条件另一个变量X,而且知道X=xi后,Y的条件信息熵(Conditional Entropy)表示为:
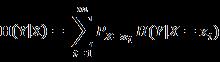
在加入条件X前后的Y的信息增益定义为
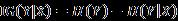
类似的,分类标记C的信息熵H( C )可表示为:

将特征Fj用于分类后的分类C的条件信息熵H( C | Fj )表示为:
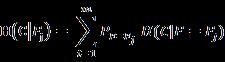
选用特征Fj前后的C的信息熵的变化成为C的信息增益(Information Gain),用表示,公式为:
假设存在特征子集A和特征子集B,分类变量为C,若IG( C|A ) > IG( C|B ) ,则认为选用特征子集A的分类结果比B好,因此倾向于选用特征子集A。
(4)一致性( Consistency )
若样本1与样本2属于不同的分类,但在特征A、 B上的取值完全一样,那么特征子集{A,B}不应该选作最终的特征集。
(5)分类器错误率 (Classifier error rate )
使用特定的分类器,用给定的特征子集对样本集进行分类,用分类的精度来衡量特征子集的好坏。
以上5种度量方法中,相关性、距离、信息增益、一致性属于筛选器,而分类器错误率属于封装器。
筛选器由于与具体的分类算法无关,因此其在不同的分类算法之间的推广能力较强,而且计算量也较小。而封装器由于在评价的过程中应用了具体的分类算法进行分类,因此其推广到其他分类算法的效果可能较差,而且计算量也较大。
以上是关于特征选择的主要内容,如果未能解决你的问题,请参考以下文章