中国有嘻哈——押韵机器人
Posted 目前在腾讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中国有嘻哈——押韵机器人相关的知识,希望对你有一定的参考价值。
[本文出自天外归云的博客园]
押韵机器人简介
近来群里看到有人谈起押韵机器,突然想起好多年前的回忆。
心血来潮写了一个押韵机器人。可以识别韵脚、比较韵脚、词汇列表按韵脚分类。
经测试,目前对多音字支持不好:比如唠嗑,唠叨。这种就识别会出错。欢迎大家继续测试,有问题反馈给我。
拼音识别基于pypinyin库实现,具体用法详见其github。
押韵机器人代码
押韵机器人代码文件命名叫“punchliner.py”,代码如下:
from pypinyin import pinyin, lazy_pinyin, Style words = ["今天","太躁","艾福杰尼","着迷","太绕","心间","限","盛宴","榴莲","亏欠","二百五","腐乳","火锅底料","MC大笑","别跟我唠","我感冒","好不好","太早","住口","兄弟","胸臆","太辣","太大","太炸","我手抖"] def is_alphabet(uchar): rule1 = (uchar >= u\'\\u0041\' and uchar<=u\'\\u005a\') rule2 = (uchar >= u\'\\u0061\' and uchar<=u\'\\u007a\') if rule1 or rule2: return True else: return False def get_punchline(word): last_character = word[len(word)-1] last_character_pinyin = pinyin(last_character)[0][0] punchline = [] for the_char in last_character_pinyin: if not is_alphabet(the_char): punchline.append(last_character_pinyin.split(the_char)[0]) punchline.append(the_char) punchline.append(last_character_pinyin.split(the_char)[1]) return punchline def compare_punchline(word1,word2): punchline1 = get_punchline(word1) punchline2 = get_punchline(word2) prefix1 = punchline1[0] prefix2 = punchline2[0] #前缀尾字母设定不为空 prefix1_last_char = \'x\' prefix2_last_char = \'x\' if prefix1 != \'\': prefix1_last_char = prefix1[len(prefix1)-1] if prefix2 != \'\': prefix2_last_char = prefix2[len(prefix2)-1] #前缀先决条件,都是i或都不是i才算押韵 pre_rule1 = (prefix1_last_char == \'i\') pre_rule2 = (prefix2_last_char == \'i\') all_i = (pre_rule1 and pre_rule2) all_not_i = \'i\' not in [prefix1_last_char,prefix2_last_char] if all_i or all_not_i: rule1 = punchline1[1] == punchline2[1] rule2 = punchline1[2] == punchline2[2] if rule1 and rule2: return True else: return False else: return False def classify_punchline(words_list): target = words_list[0] yayun_words = filter(lambda word:compare_punchline(target,word)==True,words) yayun_words_list = list(set(yayun_words)) left_words_list = list(set(words_list)-set(yayun_words_list)) print(yayun_words_list) rule1 = left_words_list != words_list rule2 = len(left_words_list) > 0 if rule1 and rule2: classify_punchline(left_words_list) if __name__ == \'__main__\': #print(get_punchline("变")) #print(get_punchline("案")) #print(get_punchline("绕")) #print(compare_punchline("安","翻")) #print(compare_punchline("变","案")) #print(compare_punchline("房","狼")) #print(get_punchline("唠")) classify_punchline(words)
其中:
1. 函数fuck_yayun可以对词藻列表中的词汇进行判断,把押韵的词汇进行自动归类;
2. 函数get_punchline可以获取词汇韵脚;
3. 函数compare_punchline可以比较韵脚。
希望有朝一日可以像发明AlphaGo一样发明AlphaRapper,让他去参加中国有嘻哈。
运行结果:
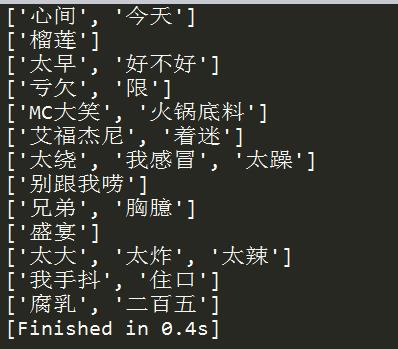
以上是关于中国有嘻哈——押韵机器人的主要内容,如果未能解决你的问题,请参考以下文章
GO巡演《中国有嘻哈》四强,中国第一女rapper向你宣告:
2017.9.01-02RAP OFF CHINA中国有嘻哈驻马店站,中国知名RAP冠军Atom,V12CLUB电子音乐,开炸!