AI 有嘻哈 | 使用 PyTorch 搭建一个会嘻哈的深度学习模型
Posted 集智学园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI 有嘻哈 | 使用 PyTorch 搭建一个会嘻哈的深度学习模型相关的知识,希望对你有一定的参考价值。

我想在跑车里
想要一辆法拉利
想要钱 Money Money
一切的一切都得靠你自己
我外婆都告诉我
.....

最近“中国有嘻哈”特别火
我也来跟风
所以本周的 NLP 教程是
拿循环神经网络(RNN)来生成嘻哈歌词。
我觉得行!
先让我们看看一个简单的深度神经网络模型,
能生成什么样的“嘻哈歌词”。
我的世界
能够有
看透
我的兄弟在我身边
每个人
或许他们是我的眼
我的能够将别约别约我
在这种角度
我就是你你的帮派
他们的声音
原本地方叫
别约你约我
别约我
别约我
看看起来还不错哈
那么……

不用买,我们自己做一个!
原理:
简单来说,中文句子中的每个字在统计上是相关的。比如对于“多想你陪我透透气”这句话,如果我们知道第一个字“多”,那下一字有可能是“想”;如果知道前两个字“多想”,那么第三个字是“你”的可能性就大些,以此类推,如果知道“多想你陪我透透”,那么最后一个字很有可能就是“气”字。
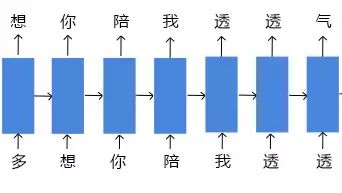
所以这次搭建的循环神经网络(RNN)模型,就是要在训练的过程中学习到“歌词之间的规律”。
我们只要给训练好的模型一个开头,比如“我们”,模型就能按照学习到的规律,继续预测生成“我们”之后的嘻哈歌词。
资源:

清理训练数据:
首先准备训练模型的数据。
我从网上爬了大约三万四千行嘻哈歌词。
lrc_lines = open('../data/rapper.txt').readlines()
print(lrc_lines[:20])
['\n', ' 作曲 : Mixtape\n', ' 作词 : 啊之\n', '\n', '录音 MISO MUSIC\n', '混缩 MAI\n', 'MIX BY MAI\n', "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", '抱歉我依旧不稳定 DAMN\n', '鱼龙混杂的街头不只靠努力 REAL 别烦恼\n', '多想你陪我透透气 发发牢骚\n', '倾诉着最近不如意 let me let me\n', '这就是生活里 的问题 不必不报忧\n', '做真实的自己 不用比 早晚都能够\n', '我始终担心你 出问题 人心难看透\n', '我怎么都可以 唯有你 所以 所以\n', '我早已日夜颠倒 烟酒成瘾 制作巧克力\n']
去除无关信息:
歌词中包含“作词”,“作曲”等信息,这对训练模型生成歌词是没有任何帮助的,先去掉他们。
# 去除文本中不是属于歌词的行
# 我的程序写的都比较水啦
# 大家可以自由发挥写出更好的程序
for i in range(len(lrc_lines)):
line = lrc_lines[i]
if "作词" in line or "作曲" in line or "编曲" in line or "录音" in line or "混缩" in line or "制作人" in line:
lrc_lines[i] = "\n"
观察下已经去除作者信息的歌词文本:
print(lrc_lines[:20])
['\n', '\n', '\n', '\n', '\n', '\n', 'MIX BY MAI\n', "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", '抱歉我依旧不稳定 DAMN\n', '鱼龙混杂的街头不只靠努力 REAL 别烦恼\n', '多想你陪我透透气 发发牢骚\n', '倾诉着最近不如意 let me let me\n', '这就是生活里 的问题 不必不报忧\n', '做真实的自己 不用比 早晚都能够\n', '我始终担心你 出问题 人心难看透\n', '我怎么都可以 唯有你 所以 所以\n', '我早已日夜颠倒 烟酒成瘾 制作巧克力\n']
可以看到现在歌词中还包括一些英文,这是嘻哈的特色。
减少语言种类:
训练数据中存在的语言种类越多,意味着深度神经网络模型学习起来的难度越大。
因为这次做的是一个简单的模型,所以我不打算让模型再去预测英文歌词,所以我要把歌词中的英文去掉。

import re
final_lrc = []
# 使用正则表达式的手段识别中文
# 中文(包括繁体)在unicode中的编码范围是u4e00~u9fa5
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
# 遍历所有歌词行
for line in lrc_lines:
# findall会返回一个列表
zh_list = zhPattern.findall(line)
# 将中文拷贝到 final_lrc 中去
for item in zh_list:
final_lrc.append(item + '\n')
# 这样就只剩中文啦!
print(final_lrc[:10])
['抱歉我依旧不稳定\n', '鱼龙混杂的街头不只靠努力\n', '别烦恼\n', '多想你陪我透透气\n', '发发牢骚\n', '倾诉着最近不如意\n', '这就是生活里\n', '的问题\n', '不必不报忧\n', '做真实的自己\n']
建立“字典”:
还是像之前一样对所有文字建立一个“文字表”,因为其中元素都是独立的汉字,所以这次我们称它为“字典”。
在字典中所有的文字都会有对应的一个索引号。
在训练神经网络模型的时候,传入神经网络的是某个字的“索引号”,而不是这个字本身。
# 字典
word_to_ix = {}
for line in final_lrc:
for word in line:
if word not in word_to_ix:
# 在单词表的末端添加这个单词
word_to_ix[word] = len(word_to_ix)
# 打印出字典中的前10个元素,注意它是无序的
for i, key in zip(range(10), word_to_ix):
print(key, ":", word_to_ix[key])
礼 : 848
嘞 : 3243
惬 : 212
歪 : 3160
以 : 73
款 : 782
遍 : 1182
伸 : 2091
體 : 2541
獠 : 3167
除了“字典”,还需要建立一个“有序列表”。
“有序列表”就是将“字典”按照索引号从小到大的顺序排序。
import operator
# 排序
sorted_char_list = sorted(word_to_ix.items(), key=operator.itemgetter(1), reverse=False)
# 有序列表
# 这里注意字典是“dict”类型
# 有序列表是“list”类型
char_list = []
for item in sorted_char_list:
char_list.append(item[0])
# 有序列表中的元素
print(char_list[:10])
# 观察有序列表中的元素即字典的有序排列
for ch in char_list[:10]:
print(ch, ":", word_to_ix[ch])
['抱', '歉', '我', '依', '旧', '不', '稳', '定', '\n', '鱼']
抱 : 0
歉 : 1
我 : 2
依 : 3
旧 : 4
不 : 5
稳 : 6
定 : 7
: 8
鱼 : 9
“字典”的长度代表训练数据中有多少不同的字,这个长度即是我们模型输入层的大小,我们建立一个变量 nn_characters 来保存它。
n_characters = len(word_to_ix)
print(n_characters)
3801
训练前的准备:
数据随机选择器:
这次搭建的神经网络模型是“字符级”的,即每次输入“一个字”。
所以先要把上面处理过后的“一条条”的数据,都保存到一个“大字符串”里,便于随机取用。
big_string = ''
for line in final_lrc:
for ch in line:
big_string += ch
print(big_string[:20])
抱歉我依旧不稳定
鱼龙混杂的街头不只靠努
然后我们再编写一个工具方法“random_chunk”,用于每次从训练数据中随机选择201个字。
import random
chunk_len = 200
# 随机选取200 + 1个字符的数据
def random_chunk():
# 起点的可选范围:0 ~ final_lrc_len-chunk_len
start_index = random.randrange(0, len(big_string) - chunk_len)
end_index = start_index + chunk_len + 1
# 将抽取的列表项转化为字符串再返回
return big_string[start_index:end_index]
result = random_chunk()
print(len(result))
201
注意这里选取的字符串长度实际为201,为什么是201,到下面建立输入和目标数据的时候你就知道。
将数据转化为张量(Tensor):
建立一个辅助方法“char_tensor”,用于将文字转化为张量(Tensor)。
张量中保存的是文字对应的索引。
import torch
import torch.nn as nn
from torch.autograd import Variable
def char_tensor(string):
# 先按指定长度创建一个longTensor,填充0
tensor = torch.zeros(len(string)).long()
# 逐字查找字典
# 取出每个字的索引号,保存到 Tensor 中
for c in range(len(string)):
tensor[c] = word_to_ix[string[c]]
return Variable(tensor)
# 来试试这个方法
index_tensor = char_tensor(random_chunk())
# 查看 Tensor 长度
print(len(index_tensor))
# 查看 Tensor 中保存的索引
print(index_tensor[:10])
201
Variable containing:
200
189
1006
1458
8
395
426
119
195
173
[torch.LongTensor of size 10]
输入和目标:
上面我们建立了“random_chunk”,用于选取201条数据。
为什么是201条?让我们回头看看文章开头的那张图:
RNN 模型在输入“多”时,需要预测出“想”;在输入“想”时,需要预测“你”。
即如果我们随机选取的总数据是“多想你陪我透透气”,那么训练输入数据是“多想你陪我”,训练目标数据是“想你陪我透透气”。
训练输入数据与训练目标数据正好错开一个字,那么当我们选取了201条数据,那输入数据和目标数据就正好是各200条。
def random_training_set():
# 先选取201字符长度的文本
chunk = random_chunk()
# 将选取的文本全部转化为 Tensor
inp = char_tensor(chunk[:-1])
target = char_tensor(chunk[1:])
return inp, target
inp, target = random_training_set()
print(len(inp))
print(len(target))
200
200
到这里我们在训练前要做的准备就全部完成了,下面要做的就是搭建模型、训练模型、评估模型了。
本期关键词:【AI有嘻哈上】
长按空白位置_选择复制
PyTorch圣殿 | 传奇NLP攻城狮成长之路
课程表
本期:AI 有嘻哈:处理数据
续期:AI有嘻哈:训练评估模型 终篇
第四期:起名大师:使用RNN生成个好名字
第五期:AI翻译官:采用注意力机制的翻译系统
第六期:探索词向量世界
第七期:词向量高级:单词语义编码器
第八期:长短记忆神经网络(LSTM)序列建模
第九期:体验PyTorch动态编程,双向LSTM+CRF
更多职位内推点击阅读原文
如果您有任何关于Pytorch方面的问题,欢迎进【集智—清华】火炬群与大家交流探讨,添加集智小助手微信swarmaAI,备注(pytorch交流群),小助手会拉你入群。

推荐阅读
获取更多更有趣的AI教程吧!
学园网站:campus.swarma.org
商务合作|zhangqian@swarma.org
投稿转载|wangjiannan@swarma.org
以上是关于AI 有嘻哈 | 使用 PyTorch 搭建一个会嘻哈的深度学习模型的主要内容,如果未能解决你的问题,请参考以下文章