算法之常见的排序算法
Posted ITGungnir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法之常见的排序算法相关的知识,希望对你有一定的参考价值。
我们平时说的“排序”,指的是内部排序,即使用内存资源进行排序的。除了内部排序之外,还有外部排序。本文主要介绍内部排序。
内部排序分为插入排序、选择排序、交换排序、归并排序等。其中,插入排序又分为直接插入排序和希尔排序;选择排序分为简单选择排序和堆排序;交换排序又分为冒泡排序和快速排序。
也就是说,本文中主要介绍其中排序方法,分别是:直接插入排序、希尔排序、简单选择排序、堆排序、冒泡排序、快速排序、归并排序。
1、直接插入排序
直接插入排序(Straight Insertion Sort)的基本思想是:将一个记录插入到已排序好的有序表中,从而得到一个新的、记录数增1的有序表。即:先将序列的第1个元素看成是一个有序的子序列,然后从第2个元素开始逐个进行插入,直至整个序列有序为止。直接插入排序的核心代码如下:
#include <cstdio> // 直接插入排序的核心函数 void performSort(int array[], int n) { for (int i = 1; i < n; i++) { int tmp = array[i]; int j = i - 1; for (; j >= 0; j--) { if (array[j] > tmp) { array[j + 1] = array[j]; } else { break; } } array[j + 1] = tmp; } }
2、希尔排序
希尔排序(Shell\'s Sort)的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。举例说明:
例如,对于一个整形数组:49 38 65 97 76 13 27 71 76 34
数组长度为10,我们可以把最初的增量设置为数组总长度的一半:5
即:第一遍做直接插入排序的元素有:49和13、38和27、65和71、97和76、76和34。
这样,经过第一遍的排序,得到的数组结果为:13 27 65 76 34 49 38 71 97 76
第二遍,我们将增量减少为上一边的一半:5 / 2 = 2
同上,经过第二遍的排序,得到的数组结果为:13 27 34 49 38 71 65 76 97 76
第三遍,我们再讲增量减少为上一遍的一半:2 / 2 = 1
此时的增量是1,无法再减少增量,因此,我们只需要再进行一次直接插入排序,就可以得到最终的排序结果了
由于经过前两次的增量排序,已经把大致的结果排了出来,因此,最后一次的排序需要交换的元素就很少了
希尔排序的核心代码如下:
#include <cstdio> // 希尔排序的核心函数 void performSort(int array[], int n) { for (int gap = n / 2; gap > 0; gap /= 2) { for (int i = gap; i < n; i++) { for (int j = i - gap; j >= 0 && array[j] > array[j + gap]; j -= gap) { int temp = array[j]; array[j] = array[j + gap]; array[j + gap] = temp; } } } }
3、简单选择排序
简单选择排序(Simple Selection Sort)的基本思想是:在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止。可以发现,在简单选择排序中,一趟只能确定一个元素(即最小的元素)。我们可以对简单选择排序进行改进,使得在一趟中可以确定两个元素(即最大的元素和最小的元素),这样可以有效地减少循环所需的资源,提高效率。简单选择排序的核心代码如下:
#include <cstdio> // 简单选择排序 void performSort(int array[], int n) { int i, j, min, max, tmp; for (i = 1; i <= n / 2; i++) { min = i; max = i; for (j = i + 1; j <= n - i; j++) { if (array[j] > array[max]) { max = j; continue; } if (array[j] < array[min]) { min = j; } } tmp = array[i - 1]; array[i - 1] = array[min]; array[min] = tmp; tmp = array[n - i]; array[n - i] = array[max]; array[max] = tmp; } }
4、堆排序
在了解堆排序之前,先了解一下关于堆(二叉堆)的知识:
(1)二叉堆的特性:
父节点的值总是大于或等于(小于或等于)任何一个子节点的值(父节点大于或等于任何一个子节点的堆称为最大堆,反之是最小堆);
每个节点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
(2)二叉堆的存储结构:
二叉堆一般用数组来表示。下标为i的节点的父节点的下标是(i-1)/2;它的左子节点的下标为i*2+1;它的右子节点的下标为i*2+2。
(3)通过数组建立二叉堆:
先将数组转化为一棵完全二叉树,然后再根据最大堆或最小堆的特性,交换树中的某些元素,最终就可以形成一个二叉堆。
(4)向二叉堆中插入元素:
将新插入的元素添加到数组的末尾(即树的最后一个叶子节点),然后再根据最大堆或最小堆的特性,交换树中的某些元素,恢复二叉堆的次序。
(5)从二叉堆中删除元素:
这里的删除总是删除树根元素,此时要将堆中的最后一个元素填补树根的空缺,然后根据特性交换元素,恢复二叉堆的次序。
堆排序的基本思想是:利用了堆(二叉堆)这种数据结构的特性,将排序操作的时间复杂度从n^2降为了n*logn。开始的时候,创建一个堆,找到堆顶元素(即数组中最大的元素),与数组中的最后一个元素交换位置。以后每个找到的最大的数都放到前一次找到的数的前面,这样,就形成了一个从后往前的递减数组,从而实现了递增排序。堆排序的核心代码如下:
#include <cstdio> // 对堆进行调整 void adjustHeap(int array[], int i, int n) { int j = 2 * i + 1, temp = array[i]; while (j < n) { if (j + 1 < n && array[j + 1] > array[j]) j++; //在左右孩子中找最小的 if (array[j] <= temp) break; array[i] = array[j]; // 把较小的子结点往上移动,替换它的父结点 i = j; j = 2 * i + 1; } array[i] = temp; } // 将数组调整成堆,调整完毕后第一个元素是数组中最小的元素 void buildHeap(int array[], int n) { for (int i = n / 2 - 1; i >= 0; i--) adjustHeap(array, i, n); } // 堆排序的核心函数 void performSort(int array[], int n) { buildHeap(array, n); for (int i = n - 1; i > 0; --i) { int temp = array[i]; array[i] = array[0]; array[0] = temp; adjustHeap(array, 0, i); } }
5、冒泡排序
传统冒泡排序的基本思想是: 在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。这种方法每一趟排序操作只能找到一个最大值或最小值。我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法,一次可以得到两个最终值(最大者和最小者),从而使排序趟数几乎减少了一半。改进后的冒泡排序的核心代码如下:
#include <cstdio> // 冒泡排序的核心函数 void performSort(int array[], int n) { int low = 0; int high = n - 1; // 设置变量的初始值 int tmp, j; while (low < high) { for (j = low; j < high; ++j) // 正向冒泡,找到最大者 if (array[j] > array[j + 1]) { tmp = array[j]; array[j] = array[j + 1]; array[j + 1] = tmp; } --high; // 修改high值, 前移一位 for (j = high; j > low; --j) // 反向冒泡,找到最小者 if (array[j] < array[j - 1]) { tmp = array[j]; array[j] = array[j - 1]; array[j - 1] = tmp; } ++low; // 修改low值,后移一位 } }
6、快速排序
快速排序的基本思想如下:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素;
2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小,另一部分记录的元素值比基准值大;
3)此时基准元素在其排好序后的正确位置;
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
快速排序的核心代码如下:
#include <cstdio> void swap(int &a, int &b) { int tmp = a; a = b; b = tmp; } int partition(int array[], int low, int high) { int privotKey = array[low]; // 基准元素 while (low < high) { // 从表的两端交替地向中间扫描 while (low < high && array[high] >= privotKey) --high; // 从high 所指位置向前搜索,至多到low+1 位置。将比基准元素小的交换到低端 swap(array[low], array[high]); while (low < high && array[low] <= privotKey) ++low; swap(array[low], array[high]); } return low; } void quickSort(int array[], int low, int high) { if (low < high) { int privotLoc = partition(array, low, high); // 将表一分为二 quickSort(array, low, privotLoc - 1); // 递归对低子表递归排序 quickSort(array, privotLoc + 1, high); // 递归对高子表递归排序 } } // 快速排序的核心函数 void performSort(int array[], int n) { quickSort(array, 0, n - 1); }
7、归并排序
归并排序的基本思想是:将两个(或多个)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,对每个子序列进行排序使其有序,最后再把有序子序列合并为整体有序的序列。归并排序的核心代码如下:
#include <cstdio> // 将一个数组的两个有序数列a[first...mid]和a[mid+1...last]合并 void mergeArray(int array[], int temp[], int first, int mid, int last) { int i = first, j = mid + 1; int m = mid, n = last; int k = 0; while (i <= m && j <= n) { if (array[i] <= array[j]) temp[k++] = array[i++]; else temp[k++] = array[j++]; } while (i <= m) temp[k++] = array[i++]; while (j <= n) temp[k++] = array[j++]; for (i = 0; i < k; i++) array[first + i] = temp[i]; } void mergeSort(int array[], int temp[], int first, int last) { if (first < last) { int mid = (first + last) / 2; mergeSort(array, temp, first, mid); mergeSort(array, temp, mid + 1, last); mergeArray(array, temp, first, mid, last); } } // 归并排序的核心函数 void performSort(int array[], int n) { int temp[n]; mergeSort(array, temp, 0, n - 1); }
七大排序方法总结
1、各种排序方法的时间复杂度和稳定性:
(注:若待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的。)
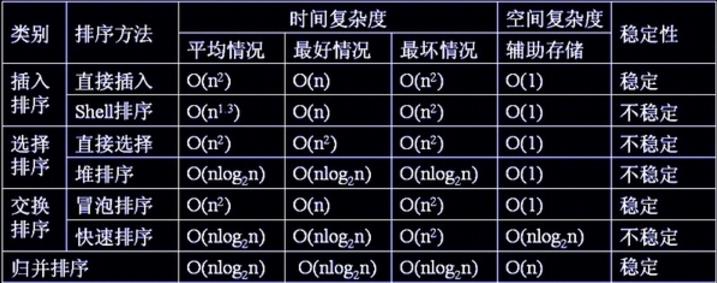
2、不同情况下各种排序算法的选择原则:
(1)当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);
(2)当数据量较大时,应采用时间复杂度为O(n*log2^n)的排序方法:快速排序、堆排序或归并排序;
(3)当数据量较小时,可采用直接插入或直接选择排序;
(4)一般不使用或不直接使用传统的冒泡排序;
(5)当数据量较大、内存空间允许、且要求稳定性时,可以选择使用归并排序。
以上是关于算法之常见的排序算法的主要内容,如果未能解决你的问题,请参考以下文章