洛谷P1124 文件压缩
Posted 日拱一卒 功不唐捐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了洛谷P1124 文件压缩相关的知识,希望对你有一定的参考价值。
https://www.luogu.org/problem/show?pid=1124
题目背景
提高文件的压缩率一直是人们追求的目标。近几年有人提出了这样一种算法,它虽然只是单纯地对文件进行重排,本身并不压缩文件,但是经这种算法调整后的文件在大多数情况下都能获得比原来更大的压缩率。
题目描述
该算法具体如下:对一个长度为n的字符串S,首先根据它构造n个字符串,其中第i个字符串由将S的前i-1个字符置于末尾得到。然后把这n个字符串按照首字符从小到大排序,如果两个字符串的首字符相等,则按照它们在S中的位置从小到大排序。排序后的字符串的尾字符可以组成一个新的字符串S’,它的长度也是n,并且包含了S中的每一个字符。最后输出S’以及S的首字符在S’中的位置p。举例:
S:example
1、构造n个字符串
example
xamplee
ampleex
mpleexa
pleexam
leexamp
eexampl
2、将字符串排序
ampleex
example
eexampl
leexamp
mpleexa
pleexam
xamplee
3、压缩结果
xelpame S’
7 p
由于英语单词构造的特殊性,某些字母对出现的频率很高,因此在S’中相同的字母有很大几率排在一起,从而提高S’的压缩率。虽然这种算法利用了英语单词的特性,然而在实践的过程中,人们发现它几乎适用于所有的文件压缩。
请你编一个程序,读入S’和p,输出字符串S。
输入输出格式
输入格式:
输入文件共有三行,第1行是一个整数n(1<=n<=10000),代表S’的长度,第2行是字符串S’,第3行是整数p。
输出格式:
仅包含一行S。
输入输出样例
7 xelpame 7
example
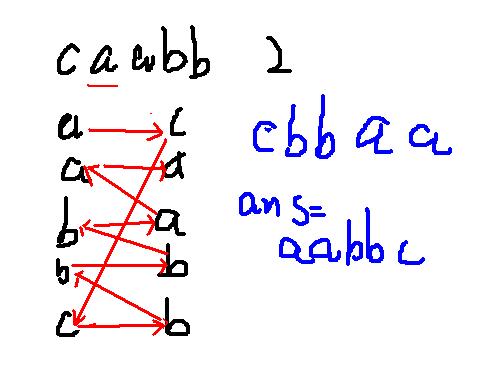
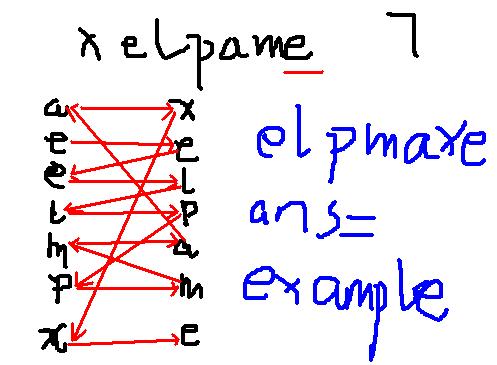
准备好一张纸,一支笔:
把输入的字母按字典序排好竖着放在左边
输入的字符串按输入顺序竖着放在右边
使其一一对应
找到第p个字符字典序排第几,相同取最靠上的 ①
作为起点
向右水平连线,记连到的字母为c1
在左边找到对应的字母,如果相同取最靠下的 ②
向右水平连线,记连到的字母为c2
……
最终答案为c(n),c(n-1),c(n-2)……c2,c1
为什么①取最靠上
因为c1为字符串的最后一个字符,它所对应的是第一个字符,在相同字典序的情况下,没有位置比它更靠前的
为什么②取最靠下
因为我们是从后往前构造字符串,在相同字典序的情况下,位置更靠后
#include<cstdio> #define N 10001 using namespace std; char s[N],ans[N]; int a[26],l[26],r[26]; int main() { int n,p; scanf("%d%s%d",&n,s+1,&p); for(int i=1;i<=n;i++) a[s[i]-\'a\']++; for(int i=0;i<26;i++) { l[i]=r[i-1]+1; r[i]=l[i]+a[i]-1; } int now=l[s[p]-\'a\']; int tot=0; while(tot<n) { ans[tot]=s[now]; now=r[s[now]-\'a\']--; tot++; } for(int i=n-1;i>=0;i--) putchar(ans[i]); }
以上是关于洛谷P1124 文件压缩的主要内容,如果未能解决你的问题,请参考以下文章