HTTP1.0和HTTP1.1的区别
Posted 傍晚的羔羊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP1.0和HTTP1.1的区别相关的知识,希望对你有一定的参考价值。
区别一、HTTP 1.0只支持短连接而HTTP 1.1支持持久连接
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
一个WEB站点每天可能要接收到上百万的用户请求,为了提高系统的效率,HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。但是,这也造成了一些性能上的缺陷,例如,一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的html内容时,发现其中的<img>图像标签后,浏览器将根据<img>标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求,如下图所示:
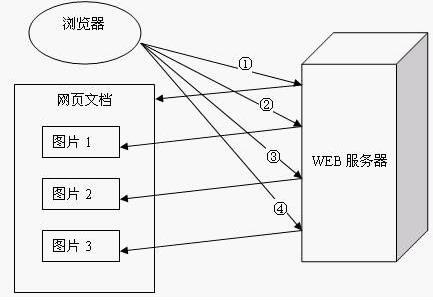
显然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档和图像,上一次和下一次请求完全分离。即使图像文件都很小,但是客户端和服务器端每次建立和关闭连接却是一个相对比较费时的过程,并且会严重影响客户机和服务器的性能。当一个网页文件中包含Applet,javascript文件,CSS文件等内容时,也会出现类似上述的情况。
为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
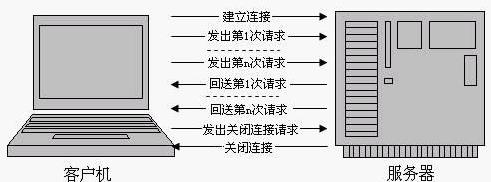
HTTP 1.1的持久连接,也需要增加新的请求头来帮助实现,例如,Connection请求头(HTTP 1.1新增的)的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。
HTTP/1.1 协议的持久连接有两种方式:
非流水线方式:客户在收到前一个响应后才能发出下一个请求;
流水线方式:客户在收到 HTTP 的响应报文之前就能接着发送新的请求报文,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容;
区别二、HTTP 1.1增加host字段
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP1.1在Request消息头里头多了一个Host域,比如:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
HTTP1.0则没有这个域。
举个例子:
我们知道一个ip地址可以对应多个域名,比如假设我有这么几个域名www.qiniu.com,www.taobao.com和www.jd.com然后根据DNS匹配找到了对应ip为111.111.111.111虚拟机服务器地址,那么我通过任何一个域名去访问最终解析到的都是ip 111.111.111.111。那么问题就来了,http请求头中的文件或页面是哪个站点的呢?
此时就要提到Host的概念,其实可以这样看,我们的那台虚拟主机ip为111.111.111.111的上面其实是可以放很很多网站的(不然如果只能放一个网站的话就太不合理了,虚拟机那么多资源都浪费了),我们可以把www.qiniu.com,www.taobao.com和www.jd.com这些网站都假设那台虚拟机上面,但是这样会有一个问题,我们每次访问这些域名其实都是解析到服务器ip为 111.111.111.111,我怎么来区分每次根据域名显示出不同的网站的内容呢,其实这就要用到请求头中Host的概念了,每个Host可以看做是我在服务器111.111.111.111上面的一个站点,每次我用那些域名访问的时候都是会解析同一个虚拟机没错,但是我通过不同的Host可以区分出我是访问这个虚拟机上的哪个站点。
HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。此外,服务器应该接受以绝对路径标记的资源请求。
区别三、100(Continue) Status(节约带宽)
存在一种浪费带宽的情况是请求消息中如果包含比较大的实体内容,但不确定服务器是否能够接收该请求(如是否有权限),此时若贸然发出带实体的请求,如果被拒绝也会浪费带宽。
HTTP/1.1加入了一个新的状态码100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码401(Unauthorized);如果服务器接收此请求就回送响应码100(Continue),客户端就可以继续发送带实体的完整请求了。注意,HTTP/1.0的客户端不支持100响应码。但可以让客户端在请求消息中加入Expect头域,并将它的值设置为100-continue。
100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
客户端在Request头部中包含
Expect: 100-continue
Server看到之后呢如果回100 (Continue) 这个状态代码,客户端就继续发requestbody。
这个是HTTP1.1才有的。
区别四、 增加Request方法
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
以上是关于HTTP1.0和HTTP1.1的区别的主要内容,如果未能解决你的问题,请参考以下文章