03-表操作1
Posted 最快的方法就是最慢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了03-表操作1相关的知识,希望对你有一定的参考价值。
写在前面的话:
该系列博文是我学习《 Hive源码解析与开发实战》视频课程的一个笔记,或者说总结,暂时没有对视频中的操作去做验证,只是纯粹的学习记录。
有兴趣看该视频的博友可以留言,我会共享出来,相互交流学习 ^.^。
*********************************************************************************************************
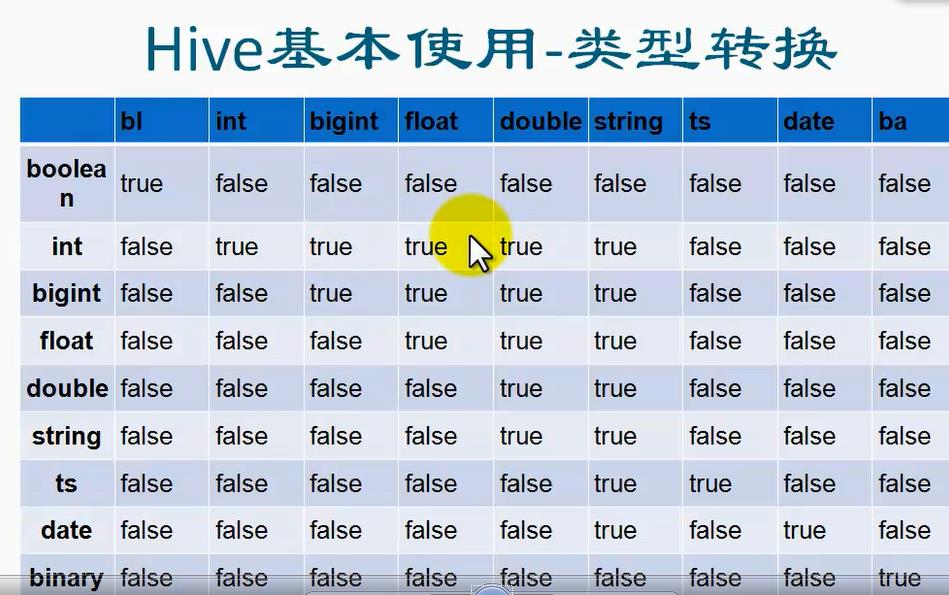
1、Hive数据类型:

2、Hive文件格式:
文件类型主要包括:文本文件格式、序列化文件格式、列式文件格式。

对于列文件格式,它是针对hdfs中的一个block块的:
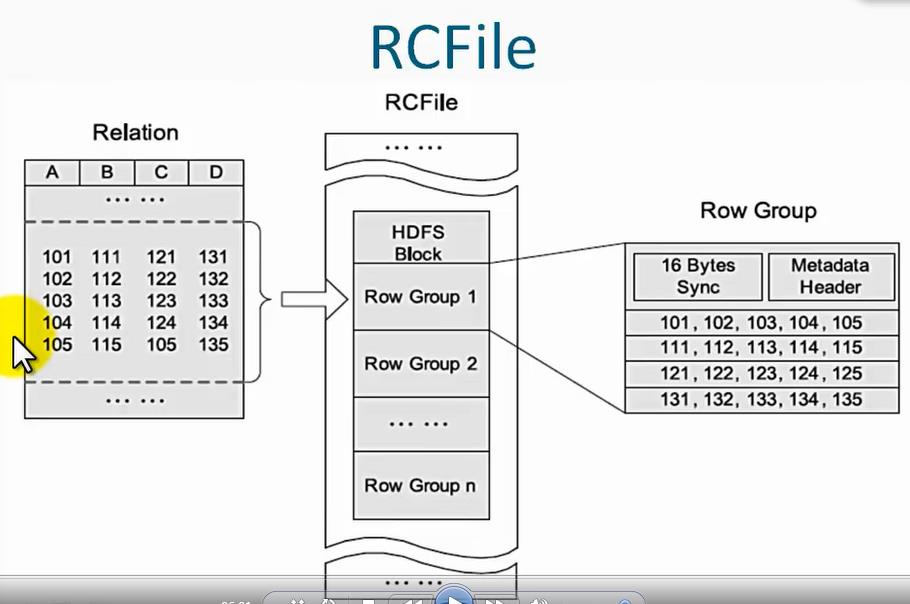
它首先把hdfs上的一个块划分成了一个个行组,每一个行组是按照多少行来进行分组的,比如说把100行分为一个行组(row group),然后再对这一个Row Group进行压缩,压缩过程如下:
首先把每一列的数据转化为行的数据,也就是所有的列都变成行,这样做是为了方便有时候我们需要某一列的数据,但为了高效,我们不需要把其他列的数据也查询出来;
然后把转化后的行中重复的数据去掉,也就是“压缩”的由来,这样可以节省hdfs的存储空间;
3、Hive表的创建:
hive里面所有的数据都是以表的形式来管理的,所以表是hive的一个基础,关于表的创建语法如下:

解释:
CREATE :创建表的关键字;
EXTERNAL:是可选的,主要用来区分是内部表还是外部表,内部表和外部表主要是hive表的两大类;
TABLE: 关键字;
IF NOT EXISTS:这个是可选的,表示当我创建一个表的时候,如果不存在才创建,已经存在该表了就不创建。主要是为了防止在没有该语句的时候,创建一个已有的表时错;
db_name. : 表示数据库的名字,后面跟一个点,用来接对应表的名字;
table_name: 表的名字;
col_name date_type : 分别为字段名字和类型;
COMMENT col_comment: 字段的描述信息,COMMENT后面接字段描述信息 col_comment;
分区设置:
PARTITIONED BY: 通过哪些字段进行分区,后面接小括号,然后里面写相应的字段名和字段类型,如果有描述信息的还可以添加相应字段的描述信息;Hive的分区是为了查询效率,比如说按照时间字段来进行分区,每一天的数据一个区,那么会在该表目录下创建相应的子目录,每个子目录对应一天的数据,注意Hive的分区和mapreduce说的分区是两事。
分桶设置:
CLUSTERED BY:这个是为了在分桶的时候指定按照那个字段来进行分桶,然后会根据该字段的值求hash值,模除以桶的个数,就可以决定把该条记录放到哪个桶里。
SORTED BY:这个是用来指定在该桶里按照那个字段进行排序。
INTO num_buckets BUCKETS: 表示划分为多少个桶。
ROW FORMAT:设置行的格式,后面接row_format格式,row_format表示某种格式,表示行里面的字段是以什么进行分割的,如空格或逗号或者可以在后面设置为序列化和反序列化的方式。
STORED AS :后面接文件格式,表示以什么格式进行存储,这里的文件格式就是前面讲的文本格式、序列化文件格式、列式格式;
STORED BY:指定使用自定义的inputformat和outputformat所定义的文件格式。
LOCATION hdfs_path:表示把创建的这个表数据存储在hdfs上的位置;
TABLEPROPERTIES: 后面接小括号,里面设置属性名=属性值;这里用来设置表的属性;
AS select_statement:通过select查询出一些其他表的结果,然后直接把得到的这些数据放入到创建的这张表里面去;
以上就是hive创建表的基本语法解释。
下面列举一个hive创建表的列子:

后面row format后的句子意思是各个字段是以‘\\t’来进行分割的,每一行是以\'\\n\'来进行换行分割的,最后stored as textfile表示以文本的形式进行存储。
实际演示下内部表:
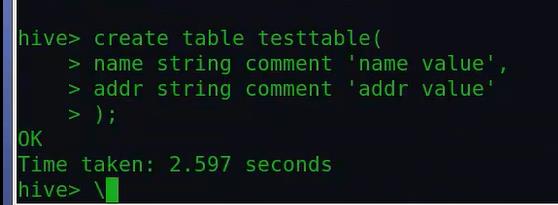
①创建一个基本的表:
②查看该表是否存在:show tables;
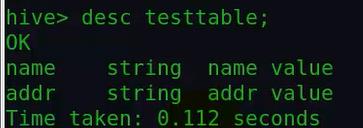
③查看该表的详细信息: desc 表名:
如果要看更详细的信息:

或者

④从本地加载相应文件到hive表中:

这里local的意思是让其从本地区找后面给的路径;overwrite是表示如果之前表存在,并且对应在hdfs上有值的话,那么会进行覆盖hdfs上的值,
并且相应的信息都会更新。如果不使用overwrite的话,那么会将该数据追加到该表中,对应hdfs所存储数据,会发现已经有该文件了,
所以会创建一个副本文件,将该内容放到该副本中,但是hive查询该表内容的时候,却是显示两部分的内容,新增加的内容会追加到表的后面显示。
最后删除该表:
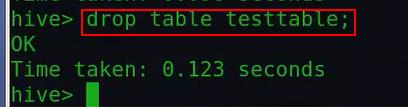
那么相应hdfs上该表的目录也就删掉了,也就是说该表目录下所对应的所有文件也都删掉了:
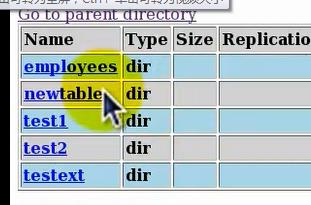
由上可以看出,内部表的性质:
①内部表管理了内部表中的数据,也就是说所有加载到该内部表中的数据归内部表所有,当把这个表删除后,对应hdfs上的该表目录也会被删掉,
也就是表对应到hdfs上的数据也会被删掉,也就是说内部表类型的表和数据是绑定在一起的;
②当我创建表的时候,通过LOCATION把一个hdfs上的位置指定给一个内部表的时候,当我把表删除,那么整个位置里面的所有数据都会被删除掉,
包括这个位置在表创建之前的内容,这样的就很不安全对于这个位置之前存放的数据,所有引入了外部表;
然后演示下外部表的操作:
①如果创建外部表,并通过location指定位置的时候,在用完该数据后,进行删除该表时,不会把这个位置删掉,它只会删除该表所对应的元数据信息;
②首先创建一个外部表,也就是加一个extenal,并指定一个locaiton:
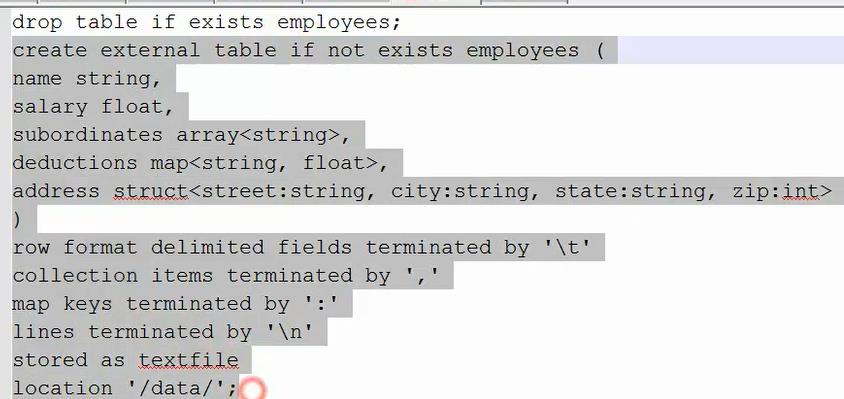
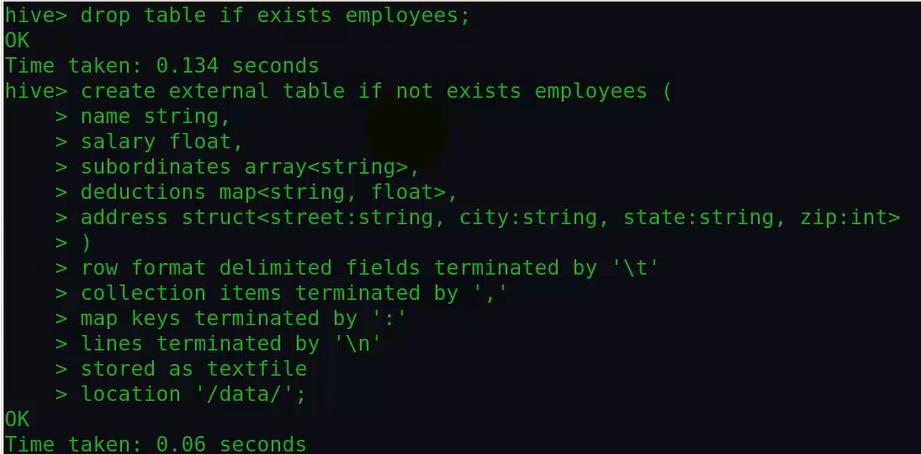

由上面的实验看出,hive里面唯一不走mapreduce的查询操作就是select * from 某个表 或者再加个limit;但是查询其它的都是要走mapreduce的,比如
上面查询某个字段值,这会形成一个job然后提交执行。
查询map:
查询结构体:

注意到这两个查询都会通过mapreduce;
最后删除掉这个外部表看看相对于内部表会有什么不同?最后实验发现,删除后,该表hdfs数据还是存在,
由此得出结论:
1、对于外部表,除了删除表只删除元数据而保留表数据目录外,数据加载行为与内部表相同。
2、大约有三种情况不走mapreduce:①select * from 某个表;②select * from 某个表 Limit 行数;
③指定slect * 查询某个分区;
4、Hive操作表:

desc 后的extended和formatted是可选的,用来查看一个表更详细的信息,其中加format的话,显示更的信息更规范点,容易读;extended显示的详细信息不容易读。
总结记忆:
1、Hive主要有三种文件格式:
1> textfile 文本文件格式;
2> Sequencefile 序列化文件格式;
3> Rcfile 列式文件格式;
其实还可以自定义文件格式,方法是继承相应的inputformat类和outputformat类,然后达成jar包,放到相应目录下进行加载,然后创建使用该自定义格式的表,
就可以使用该自定义格式了。
其中Rcfile文件格式是针对hdfs的block块的。它首先把hdfs上的一个block按照若干行划分为一个行组(Row Group),然后再对Row Group进行压缩,压缩过程如下:
①首先把列转化为行,这样做方便了高效我们需要查询列数据,而不用把其他不需要的列也查出来;
②然后把转化后的行中重复的数据去掉,从而"压缩"了数据,节省了hdfs的存储空间;
2、Hive创建表的语法解释(主要参考上面博文该部分的讲解)
3、Hive表的操作:
desc [extended或者formatted] tablename;
用来显示一个表的信息,如果加上extended可以显示更加详细的信息,但显示得很乱,不好看;所以我们可以用formatted来替换extended,
这样显示的详细信息就可以很容易看了。
4、查询Hive表的数组字段、Map字段以及struct字段的方式:
见上面博文讲解的创建hive表小结末端的内容。
以上是关于03-表操作1的主要内容,如果未能解决你的问题,请参考以下文章