统计学习方法四 朴素贝叶斯分类
Posted SparkDr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统计学习方法四 朴素贝叶斯分类相关的知识,希望对你有一定的参考价值。
朴素贝叶斯分类
1,基本概念

2,算法流程
关键点:理解先验概率,条件概率,最大后验概率,下面是以极大似然估计的



3,算法改进(贝叶斯估计)
上述用极大似然估计可能会出现所要估计的概率值为0的情况,改进方法:
先验概率贝叶斯估计:K表示类别数,λ为参数:0时为极大似然估计;1时为拉普拉斯平滑

条件概率贝叶斯估计:S为某个特征的离散种类
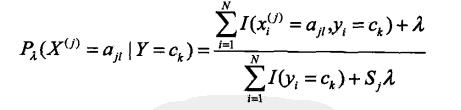

4,总结

朴素贝叶斯的主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
朴素贝叶斯适用场景:
1)不同维度之间相关性较小,离散属性的数据
以上是关于统计学习方法四 朴素贝叶斯分类的主要内容,如果未能解决你的问题,请参考以下文章