SSE图像算法优化系列十一:使用FFT变换实现图像卷积。
Posted 只(挚)爱图像处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SSE图像算法优化系列十一:使用FFT变换实现图像卷积。相关的知识,希望对你有一定的参考价值。
本文重点主要不在于FFT的SSE优化,而在于使用FFT实现快速卷积的相关技巧和过程。
关于FFT变换,有很多参考的代码,特别是对于长度为2的整数次幂的序列,实现起来也是非常简易的,而对于非2次幂的序列,就稍微有点麻烦了,matlab中是可以实现任意长度FFT的,FFTW也是可以的,而Opencv则有选择性的实现了某些长度序列的变换,查看Opencv的代码,可以发现其只有对是4的整数次幂的数据部分采用了SSE优化,比如4、16、64、256、1024这样的序列部分,因此基4的FFT是最快的,而剩余的部分则依旧是普通的C语言实现,我这里主要是把Opencv的代码抠出来了。
Opencv关于FFT实现的代码在Opencv 3.0\\opencv\\sources\\modules\\core\\src\\dxt.cpp中,代码写的特别复杂,扣取工作也做的相当艰苦,其基4的SSE优化核心代码如下所示:
// optimized radix-4 transform template<> struct DFT_VecR4<float> { int operator()(Complex<float>* dst, int N, int n0, int& _dw0, const Complex<float>* wave) const { int n = 1, i, j, nx, dw, dw0 = _dw0; __m128 z = _mm_setzero_ps(), x02=z, x13=z, w01=z, w23=z, y01, y23, t0, t1; Cv32suf t; t.i = 0x80000000; __m128 neg0_mask = _mm_load_ss(&t.f); __m128 neg3_mask = _mm_shuffle_ps(neg0_mask, neg0_mask, _MM_SHUFFLE(0,1,2,3)); for( ; n*4 <= N; ) { nx = n; n *= 4; dw0 /= 4; for( i = 0; i < n0; i += n ) { Complexf *v0, *v1; v0 = dst + i; v1 = v0 + nx*2; x02 = _mm_loadl_pi(x02, (const __m64*)&v0[0]); x13 = _mm_loadl_pi(x13, (const __m64*)&v0[nx]); x02 = _mm_loadh_pi(x02, (const __m64*)&v1[0]); x13 = _mm_loadh_pi(x13, (const __m64*)&v1[nx]); y01 = _mm_add_ps(x02, x13); y23 = _mm_sub_ps(x02, x13); t1 = _mm_xor_ps(_mm_shuffle_ps(y01, y23, _MM_SHUFFLE(2,3,3,2)), neg3_mask); t0 = _mm_movelh_ps(y01, y23); y01 = _mm_add_ps(t0, t1); y23 = _mm_sub_ps(t0, t1); _mm_storel_pi((__m64*)&v0[0], y01); _mm_storeh_pi((__m64*)&v0[nx], y01); _mm_storel_pi((__m64*)&v1[0], y23); _mm_storeh_pi((__m64*)&v1[nx], y23); for( j = 1, dw = dw0; j < nx; j++, dw += dw0 ) { v0 = dst + i + j; v1 = v0 + nx*2; x13 = _mm_loadl_pi(x13, (const __m64*)&v0[nx]); w23 = _mm_loadl_pi(w23, (const __m64*)&wave[dw*2]); x13 = _mm_loadh_pi(x13, (const __m64*)&v1[nx]); // x1, x3 = r1 i1 r3 i3 w23 = _mm_loadh_pi(w23, (const __m64*)&wave[dw*3]); // w2, w3 = wr2 wi2 wr3 wi3 t0 = _mm_mul_ps(_mm_moveldup_ps(x13), w23); t1 = _mm_mul_ps(_mm_movehdup_ps(x13), _mm_shuffle_ps(w23, w23, _MM_SHUFFLE(2,3,0,1))); x13 = _mm_addsub_ps(t0, t1); // re(x1*w2), im(x1*w2), re(x3*w3), im(x3*w3) x02 = _mm_loadl_pi(x02, (const __m64*)&v1[0]); // x2 = r2 i2 w01 = _mm_loadl_pi(w01, (const __m64*)&wave[dw]); // w1 = wr1 wi1 x02 = _mm_shuffle_ps(x02, x02, _MM_SHUFFLE(0,0,1,1)); w01 = _mm_shuffle_ps(w01, w01, _MM_SHUFFLE(1,0,0,1)); x02 = _mm_mul_ps(x02, w01); x02 = _mm_addsub_ps(x02, _mm_movelh_ps(x02, x02)); // re(x0) im(x0) re(x2*w1), im(x2*w1) x02 = _mm_loadl_pi(x02, (const __m64*)&v0[0]); y01 = _mm_add_ps(x02, x13); y23 = _mm_sub_ps(x02, x13); t1 = _mm_xor_ps(_mm_shuffle_ps(y01, y23, _MM_SHUFFLE(2,3,3,2)), neg3_mask); t0 = _mm_movelh_ps(y01, y23); y01 = _mm_add_ps(t0, t1); y23 = _mm_sub_ps(t0, t1); _mm_storel_pi((__m64*)&v0[0], y01); _mm_storeh_pi((__m64*)&v0[nx], y01); _mm_storel_pi((__m64*)&v1[0], y23); _mm_storeh_pi((__m64*)&v1[nx], y23); } } } _dw0 = dw0; return n; } };
其实也不复杂,总觉得里面的_mm_loadh_pi用的很好,这也得益于其数据源采用了Complex格式,这样数据的实部和虚部在内存中是连续的,用SSE加载数据是也就很方便了。
上面只是部分代码,为了配合该过程,还有很多的初始化,比如数据的shuffle等。详见Opencv的文件。
对于2维的FFT变换,我没有去扣CV的代码,而是直接先每行进行一维的FFT1D,然后对结果在进行列方向的FFT1D,由于FFT1D算法需要处理的序列必须是连续的内存,因此,需要对中间的结果进行转置,处理完后在转置回来,为了节省时间,这个转置也应该用SSE优化。
当2维的宽度和高度相同时,这个转置是不需要分配另外一份额外的内存的,这个叫In-Place转置,另外一个重要优点就是FFT1D算法也支持In-Place操作。
由于是对Complex数据进行转置,我们可以换个角度考虑,因为一个Complex正好和double数据占用同样的内存,这样直接利用和double相关的SSE指令就可以方便的实现Complex相关数据的转置。比如当宽度和高度一样时,刻直接使用下述方式。
inline void Inplace_TransposeSSE2X2D(double *Src, double *Dest, int Length) { __m128d S0 = _mm_loadu_pd(Src); __m128d S1 = _mm_loadu_pd((Src + Length)); __m128d D0 = _mm_loadu_pd(Dest); __m128d D1 = _mm_loadu_pd((Dest + Length)); _mm_storeu_pd(Dest, _mm_unpacklo_pd(S0, S1)); _mm_storeu_pd(Dest + Length, _mm_unpackhi_pd(S0, S1)); _mm_storeu_pd(Src, _mm_unpacklo_pd(D0, D1)); _mm_storeu_pd(Src + Length, _mm_unpackhi_pd(D0, D1)); }
参考系统的Intrinsic的_MM_TRANSPOSE4_PS函数,可以发现double类型的转置方式不太一样,可以直接使用有关的unpack函数,而不使用shuffle,当然使用shuffle也是没有问题的。
那么最后我实现的FFT2D函数如下所示:
int FFT2D(Complex *Input, Complex *Output, int Width, int Height, bool Invert, int StartZeroLines = 0, int EndZeroLines = 0) { if ((Input == NULL) || (Output == NULL)) return IM_STATUS_NULLREFRENCE; if ((IsPowerOfTwo(Width) == false) || (IsPowerOfTwo(Height) == false)) return IM_STATUS_INVALIDPARAMETER; if (Width == Height) { void *Buffer = FFT_Init(Width); if (Buffer == NULL) return IM_STATUS_OUTOFMEMORY; for (int Y = StartZeroLines; Y < Height - EndZeroLines; Y++) FFT1D(Input + Y * Width, Output + Y * Width, Buffer, Width, Invert); // 先水平方向变换 InPlace_TransposeD((double *)Output, Width); // 再位转置 for (int Y = 0; Y < Height; Y++) FFT1D(Output + Y * Width, Output + Y * Width, Buffer, Width, Invert); // 再垂直方向变换 InPlace_TransposeD((double *)Output, Width); FFT_Free(Buffer); } else { void *Buffer = FFT_Init(Width); if (Buffer == NULL) return IM_STATUS_OUTOFMEMORY; for (int Y = StartZeroLines; Y < Height - EndZeroLines; Y++) FFT1D(Input + Y * Width, Output + Y * Width, Buffer, Width, Invert); Complex *Temp = (Complex *)malloc(Width * Height * sizeof(Complex)); if (Temp == NULL) { FFT_Free(Buffer); return IM_STATUS_OUTOFMEMORY; } TransposeD((double *)Output, (double *)Temp, Width, Height); FFT_Free(Buffer); Buffer = FFT_Init(Height); // 必须要二次初始化 if (Buffer == NULL) return IM_STATUS_OUTOFMEMORY; for (int Y = 0; Y < Width; Y++) FFT1D(Temp + Y * Height, Temp + Y * Height, Buffer, Height, Invert); TransposeD((double *)Temp, (double *)Output, Height, Width); FFT_Free(Buffer); free(Temp); } return IM_STATUS_OK; }
注意在函数的最后我增加了StartZeroLines 和EndZeroLines 两个参数,他们主要是在进行行方向的FFT1D是忽略最前面的StartZeroLines和最后面的EndZeroLines 个全0的行,因为全0的变换后面的结果还是0,没有必要进行计算,减少计算时间。在opencv中也是有个nonzero_rows的,但是他只是针对前面的行,而实际中,比如很多情况是,先要扩展数据,然后把有效数据放置在左上角,这样只有右下角有非零元素,所以opencv这样做就无法起到加速作用了。
对扣取的代码进行了实际的测试,1024*1024的数据,进行100次正反变换,耗时3000ms,使用matlab进行同样的操作,耗时约5500ms,并且观察任务管理器,在4核PC上CPU使用率100%,说明他内部使用了多线程,不过有一点就是matlab使用的是double类型的数据。听说matlab最新版使用的就是FFTW库,不过无论如何,这个速度还是可以接受和相当快的。
下面我们重点谈下基于FFT的图像卷积的实现,理论上如果图像a大小为N * M,卷积核b大小为 X * Y,则卷积实现的过程如下:
首先扩展数据,扩展后的大小为 (N + X - 1) * (M + Y - 1),将卷积核数据放置到扩展后的数据的左上角,其他元素填充0,得到bb, 对bb进行FFT2D正向变换得到B,然后也将图像数据放置到图像的左上角,其他元素填充为0,得到aa,对aa也进行FFT2D正向变换得到B,接着对A和B进行点乘得到C,最后对C进行逆向的FFT变换得到D,最后取D的中间部分有效数据就是卷积的结果。
举个例子,假设图像数据为:

卷积核为:

扩展后的图像数据为:

扩展后的卷积数据为:
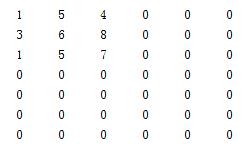
进行上述操作:D = ifft2(fft2(aa).*fft2(bb)),得到:
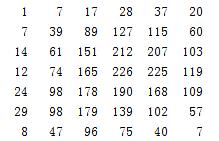
中间部分的数据就是卷积的有效数据。
仔细观察,可以发现这样的卷积在边缘处是有问题,他把超出边缘部分的数据全部用0代替了,因此这种卷积还是不完美的,一种解决办法就是首先把原图沿着边缘扩展,扩展的方式可以是重复或者镜像,扩展的大小当然就和卷积核的大小有关了,一般按卷积核中心对称分布,这时,边缘扩展后的图像大小为 (N + X - 1) * (M + Y - 1)。
也就是说合理的过程是进行两次扩展,在进行FFT变换前的最终数据维度为 (N + X - 1 + X - 1) * (M + Y - 1 + Y - 1),在进行逆变换得到的结果中从第(X - 1, Y - 1)坐标处取有效值。
我们在仔细审视下上述过程,第一、内存占用方面,需要2个 (N + X - 1 + X - 1) * (M + Y - 1 + Y - 1) * sizeof(Complex)大小的内存,这很可观的,特备是对于移动设备,第二,由于我们目前的FFT都是只能处理2的整数次幂的序列,如果以全图为对象,则有可能会增加很大的无效计算,比如N + X - 1 + X - 1 如果等于1025,则需要调整至于2048,尺寸约大,这种无效计算的可能性越大,而这于我们前面希望利用2的整数次幂的FFT最快的初衷就矛盾了。
一种解决方法就是分块计算,比如我们把图像分成很多个满足条件 (NN+ X - 1 + X - 1) = 256 和 (MM + Y - 1 + Y - 1) = 256的块,其中NN * MM就是图像分块大的大小,这样对卷积核那部分的FFT就是一次256*256的二维卷积,并且是公共的,这比原始的计算一块很大的(N + X - 1 + X - 1) * (M + Y - 1 + Y - 1)要节省很多时间,同时,只占用了很小的一块内存。当卷积核的大小不大于50时,每次有效的计算的块NN * MM相对于整体的2D FFT计算来说占比还是相当高的。这样可有效的减少1025尺寸直接变成了2048这样的FFT计算。
另外注意一点,FFT卷积是虚部和实部的作用是一样的,也就是说我们可以同时进行两个不想关元素的计算,比如对于32位图像,可以把一个块的Blue分量填充到实部,把Green分量填充到虚部,这样一次性就完成了2个分量的计算。而对于灰度图,则可以同时计算两个块,即第一个块的灰度值填充到实部,第二个块的灰度填充到虚部。这样一次性就完成了2个块的计算。
还有,在每个块的底部,有X - 1 + X -1个行是要填充为0的,因此这些的行的一维FFT变换是没有必要的,可以优化掉。
优化后的部分代码如下:
int IM_FFTConv2(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, float *Kernel, int KerWidth, int KerHeight) // 阈值 { int Channel = Stride / Width; if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((KerWidth >50) || (KerHeight > 50)) return IM_STATUS_INVALIDPARAMETER; // 卷积核越大,每次的有效计算量就越小了 if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_INVALIDPARAMETER; int Status = IM_STATUS_OK; const int TileWidth = 256, TileHeight = 256; int HalfW = KerWidth / 2, HalfH = KerHeight / 2; int ValidW = TileWidth + 1 - KerWidth - (KerWidth - 1); // 第一个加1是因为卷积扩展的矩阵大小为N+M-1,第二个-1是因为为了取得有效数据,还要对边缘进行扩展,扩展的大小为KerHeight - 1,比如KerHeight=5,则每边需要扩展2个像素,一共扩展4个像素 int ValidH = TileHeight + 1 - KerHeight - (KerHeight - 1); // 默认的卷积的效果再卷积周边是用0来填充的,如果分块处理时,这明显是不能满足要求的,会带来明显的块于块之间的分界线 int TileAmountX = (Width / ValidW) + (Width % ValidW ? 1 : 0); // 图像需要分成的块数 int TileAmountY = (Height / ValidH) + (Height % ValidH ? 1 : 0); Complex *Conv = (Complex *)malloc(TileWidth * TileHeight * sizeof(Complex)); // 需要将卷积核扩展到TileWidth和TileHeight大小 Complex *Tile = (Complex *)malloc(TileWidth * TileHeight * sizeof(Complex) * 3); // 每个小块对应的数据,当为24位模式时需要3份内存,灰度只需一份 int *RowOffset = (int *)malloc((TileAmountX * ValidW + KerWidth) * sizeof(int)); // 每个小块取样时的坐标偏移,这样在中间的块也可以取到周边合理的只,在边缘处则位镜像值 int *ColOffset = (int *)malloc((TileAmountY * ValidH + KerHeight) * sizeof(int)); if ((Conv == NULL) || (Tile == NULL) || (RowOffset == NULL) || (ColOffset == NULL)) { Status = IM_STATUS_OUTOFMEMORY; goto FreeMemory; } Status = IM_GetOffsetPos(RowOffset, Width, HalfW, TileAmountX * ValidW + (KerWidth - HalfW) - Width, IM_EDGE_MIRROR); // 左右对称 if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_GetOffsetPos(ColOffset, Height, HalfH, TileAmountY * ValidH + (KerHeight - HalfH) - Height, IM_EDGE_MIRROR); if (Status != IM_STATUS_OK) goto FreeMemory; memset(Conv, 0, TileWidth * TileHeight * sizeof(Complex)); // 卷积核的其他元素都为0,这里先整体赋值为0 for (int Y = 0; Y < KerHeight; Y++) { int Index = Y * KerWidth; for (int X = 0; X < KerWidth; X++) { Conv[Y * TileWidth + X].Real = Kernel[Index + X]; // 卷积核需要放置在左上角 } } Status = FFT2D(Conv, Conv, TileWidth, TileHeight, false, 0, TileHeight - KerHeight); // 对卷积核进行FFT变换,注意行方向上下部都为0,这样可以节省部分计算时间 if (Status != IM_STATUS_OK) goto FreeMemory; if (Channel == 1) // 单通道时可以一次性处理2个块 { } else if (Channel == 3) // 3通道时可以利用两个块的信息分别填充到BG RB GR 序列里,这样就更快了 { } else if (Channel == 4) { Complex *TileBG = Tile, *TileRA = Tile + TileWidth * TileHeight; for (int TileY = 0; TileY < TileAmountY; TileY++) { for (int TileX = 0; TileX < TileAmountX; TileX++) { IM_Rectangle SrcR, ValidR; IM_SetRect(&SrcR, TileX * ValidW, TileY * ValidH, TileX * ValidW + ValidW, TileY * ValidH + ValidH); IM_SetRect(&ValidR, 0, 0, Width, Height); IM_IntersectRect(&ValidR, ValidR, SrcR); for (int Y = ValidR.Top; Y < ValidR.Bottom + KerHeight - 1; Y++) { byte *LinePS = Src + ColOffset[Y] * Stride; int Index = (Y - ValidR.Top) * TileWidth; for (int X = ValidR.Left; X < ValidR.Right + KerWidth - 1; X++) { byte *Sample = LinePS + RowOffset[X] * 4; TileBG[Index].Real = Sample[0]; TileBG[Index].Imag = Sample[1]; TileRA[Index].Real = Sample[2]; TileRA[Index].Imag = Sample[3]; Index++; } } Status = FFT2D(TileBG, TileBG, TileWidth, TileHeight, false, 0, TileHeight - (ValidR.Bottom + KerHeight - 1 - ValidR.Top)); if (Status != IM_STATUS_OK) goto FreeMemory; Status = FFT2D(TileRA, TileRA, TileWidth, TileHeight, false, 0, TileHeight - (ValidR.Bottom + KerHeight - 1 - ValidR.Top)); if (Status != IM_STATUS_OK) goto FreeMemory; for (int Y = 0; Y < TileWidth * TileHeight; Y++) { float Temp = TileBG[Y].Real; TileBG[Y].Real = TileBG[Y].Real * Conv[Y].Real - TileBG[Y].Imag * Conv[Y].Imag; TileBG[Y].Imag = Temp * Conv[Y].Imag + TileBG[Y].Imag * Conv[Y].Real; Temp = TileRA[Y].Real; TileRA[Y].Real = TileRA[Y].Real * Conv[Y].Real - TileRA[Y].Imag * Conv[Y].Imag; TileRA[Y].Imag = Temp * Conv[Y].Imag + TileRA[Y].Imag * Conv[Y].Real; } FFT2D(TileBG, TileBG, TileWidth, TileHeight, true); if (Status != IM_STATUS_OK) goto FreeMemory; FFT2D(TileRA, TileRA, TileWidth, TileHeight, true); if (Status != IM_STATUS_OK) goto FreeMemory; for (int Y = ValidR.Top; Y < ValidR.Bottom; Y++) { byte *LinePD = Dest + Y * Stride + ValidR.Left * 4; int Index = (Y - ValidR.Top + KerHeight - 1) * TileWidth + KerWidth - 1; for (int X = ValidR.Left; X < ValidR.Right; X++) { LinePD[0] = IM_ClampToByte(TileBG[Index].Real); // 取有效的数据 LinePD[1] = IM_ClampToByte(TileBG[Index].Imag); LinePD[2] = IM_ClampToByte(TileRA[Index].Real); LinePD[3] = IM_ClampToByte(TileRA[Index].Imag); LinePD += 4; Index++; } } } } } FreeMemory: if (RowOffset != NULL) free(RowOffset); if (ColOffset != NULL) free(ColOffset); if (Conv != NULL) free(Conv); if (Tile != NULL) free(Tile); return Status; }
程序里我固定每个块的大小为256*256,这主要是考虑256是4的整数次幂,是能够完全用SSE优化掉的,同时也占用更少的内存。
如果考虑更好的处理,在最后一列以及最后一行那个块,因为有效元素的减少,可以考虑使用更小的块来计算,不过这会增加程序的复杂性。本例没有考虑了。
速度测试:
3000*3000的灰度图 卷积核5*5 328ms
卷积核15*15 348ms
卷积核25*25 400ms
卷积核49*49 600ms
以前我写过基于SSE直接卷积,同一个机器上也汇报下测试速度:
3000*3000的灰度图 卷积核5*5 264ms
卷积核15*15 550ms
卷积核25*25 1300ms
所以我以前那篇文章的有些结论是错误的。
测试工程的地址:http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar

以上是关于SSE图像算法优化系列十一:使用FFT变换实现图像卷积。的主要内容,如果未能解决你的问题,请参考以下文章
SSE图像算法优化系列十:简单的一个肤色检测算法的SSE优化。
SSE图像算法优化系列二十四: 基于形态学的图像后期抗锯齿算法--MLAA优化研究。
SSE图像算法优化系列二十四: 基于形态学的图像后期抗锯齿算法--MLAA优化研究。
SSE图像算法优化系列十八:三次卷积插值的进一步SSE优化。