编程思想与算法
Posted Leo_wlCnBlogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编程思想与算法相关的知识,希望对你有一定的参考价值。
本文是在阅读Aditya Bhargava先生算法图解一书所做的总结,文中部分代码引用了原文的代码,在此感谢Aditya Bhargava先生所作出的这么简单的事例,对基础算法感兴趣的朋友可以阅读原文。由于本人也是编程初学者,所以本书比较浅显易懂,所介绍的算法配上插图也十分易懂,这里只是介绍几种最基础的算法由浅入深以帮助理顺一些简单的思维逻辑。
算法简介
算法是一组完成任务的指令。任何代码片段都可视为算法,我们这里讨论的算法要么速度快,要么能解决有趣的问题,要么兼而有之。
二分查找
二分查找是一种算法,其输入是一个有序的元素列表,如果要 查找的元素包含在列表中,二分查找返回其位置;否则返回Null。
二分法很好理解,如果让你猜出100以内指定的某个值的话,怎样可以做到用最少的次数寻找到。可能有人觉得可能一次就可以找到,但是最糟可能要猜100次哦。
这种问题使用二分法就很简便了,每次取中间值以缩小查找范围,这样7步以内必定可以找到答案。
如果这个问题扩大到4亿的话,无疑二分法可要优秀的多。一般而言,对于包含n个元素的列表,用二分查找最多需要log2n步,而简单查找最多需要n步。
二分法的有点事查找速度快,但是仅当列表是有序的时候,二分查找才管用。
对于这个猜数字的游戏使用二分法思想完成的代码如下:

#二分法
def two(lists,item):
low=0
high=len(lists)-1
while low<= high:
mid=(low+high)//2
guess=lists[mid]
if guess==item:
return "guess is %s"%guess
elif guess > item:
high=mid-1
else:
low=mid+1
return None
lists=[1,2,4,6,8]
print(two(lists,8))
print(two(lists,3))
运行结果:
guess is 8
None
大O表示法
大O表示法是一种特殊的表示法,指出了算法的速度有多快。由于不同算法运行时间的增速不同,所以使用大O表示法来看时间增速更为科学直观。
例如假设列表包含n个元素。简单查找需要检查每个元素,因此需要执行n次操作。使用大O表示法,这个运行时间为O(n)。之所以称为大O表示法,是因为操作数前有个大O。。。这是真的。
简单查找的运行时间总是为O(n)。在电话簿查找Adit时,一次就找到了,这是最佳的情形,即O(1),但大O表示法说的是最糟的情形。因此,你可以说,在最糟情况下,必须查看电话簿中的每个条目,对应的运行时间为O(n)。
一些常见的大O运行时间
O(log n),也叫对数时间,这样的算法包括二分查找。
O(n),也叫线性时间,这样的算法包括简单查找。
O(n * log n),这样的算法包括快速排序。
O(n2 ),这样的算法包括选择排序。
O(n!),这样的算法包括接下来将介绍的旅行商问题的解决方案。
使用这几种算法绘制一个16格的网格需要的时间如下:

速度由快到慢,当然只是针对这个问题而言。
算法的速度指的并非时间,而是操作数的增速。
谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
算法的运行时间用大O表示法表示。
O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
旅行商问题
这着实困扰着很多人,一位旅行商要去往5个城市,如何确保旅程最短,5个城市有120种不同的排列方式。涉及n个城市时,需要执行n!(n的阶乘)次操作才能计算出结果。因此运行时间为O(n!),即阶乘时间。
选择排序
很多算法仅在数据经过排序后才管用。当然很多语言都内置了排序算法,因此你基本 上不用从头开始编写自己的版本。
数组与链表
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
数组中的内存必须是相连的,这意味着增加元素的时候如果紧跟着的那个内存被占用了,那就只能重新寻找可容纳的连续地址,如果没有这么长的连续地址结果还存不了,所以计算机在存数组时还预留了空间,你只要三个内存,但是我给你十个。即使如此额外请求的位置可能根本用不上,这将浪费内存,你没有使用,别人也用不了。而且待办事项超过10个后,你还得转移。
链表中的元素可存储在内存的任何地方。链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。在链表中添加元素很容易:只需将其放入内存,并将其地址存储到前一个元素中,删除也是如此。但是链表在读取上要明显弱于数组,要读取最后一个内存的内容必须要按顺序依次读到最后一个位置为止,数组可以随意读取中间任意位置的内容(因为知道第一块内存地址可以推出第几块地址的位置,他们是连续的)。
数组与链表的操作运行时间
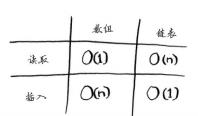
数组和链表哪个用得更多呢?显然要看情况。但数组用得很多,因为它支持随机访问,很多情况都要求能够随机访问,而不是顺序访问。
选择排序
比如网易云音乐要根据你听歌的次数排序你喜欢的音乐,可以每次都循环列表,每次取出最高次数的音乐放入新列表,直到原列表为空时结束。则总时间为1/2O(n**2),大O法省略常数,所以也就是时间为O(n**2)。
选择排序的代码:
#O(n**2)
def low(arr):
lowest=0
arrlow=arr[0]
for i1 in range(1,len(arr)):
if arr[i1] < arrlow:
arrlow=arr[i1]
lowest=i1
return lowest
def sor(arr):
new_arr=[]
for i in range(len(arr)):
smaller=low(arr)
new_arr.append(arr.pop(smaller))
return new_arr
print(sor([3,2,9,6,4]))
运行结果:
[2, 3, 4, 6, 9]
注:同一数组的元素类型都必须相同。
递归
递归指的是调用自己的函数,递归只是让解决方案更清晰,并 没有性能上的优势。实际上,在有些情况下,使用循环的性能更好。Leigh Caldwell在Stack Overflow上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能 更容易理解。如何选择要看什么对你来说更重要。”
基线条件和递归条件
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线 条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己的条件,从而避免形成无限循环。
#递归求阶乘
def fac(num):
if num==1:
return 1
else:
return num*fac(num-1)
print(fac(5))
运行结果:
120
#递归叠加
def ad(lis):
if lis==[]:
return 0
else:
return lis.pop(0)+ad(lis)
print(ad([1,2,3]))
运行结果:
6
#递归计数
def num(lis):
n=0
if lis ==[]:
return n
else:
lis.pop()
n+=1
n+=num(lis)
return n
print(num([1,2,3,4,5]))
运行结果:
5
#递归求最大值
def ma(lis):
m=lis[0]
if len(lis) ==1:
return m
else:
tmp=ma(lis[1:])
if tmp > m:
m=tmp
return m
print(ma([7,3,10,4,6]))
运行结果:
10
堆与栈
这个概念大家一定都比较清楚,这是经常使用的两种编程概念,堆也叫队列,指的是先进先出,栈则相反指的是后进先出,可以想一想python中的嵌套函数的调用,里层的函数是后定义的但是却先执行完,执行完有返回外层函数,这个调用函数就是调用栈的概念。规范的说他们只有压入和弹出两种状态。
使用栈也存在一些缺点,存储详尽的信息可能占用大量的内存。每个函数调 用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。那么你只能使用循环完成或者尾递归(这个高级方法我还不会)。
快速排序
分而治之
假设要将一块土地均匀分成方块,并且确保方块最大。可以使用D&C策略。D&C算法是递归的。
使用D&C解决问题的过程包括两个步骤:
(1) 找出基线条件,这种条件必须尽可能简单。
(2) 不断将问题分解(或者说缩小规模),直到符合基线条件。
根据D&C的定义,每次递归调用都必须 缩小问题的规模。这个问题的基线条件就是一条边的长度是另一条边的整数倍。以短边为基准,在长边取短边*n的最大取值,剩下的部分依次按上述操作,直到最后长边为短边的整数倍位置短边**2就是最大方形了。
D&C的工作原理:
(1) 找出简单的基线条件;
(2) 确定如何缩小问题的规模,使其符合基线条件。
D&C并非可用于解决问题的算法,而是一种解决问题的思路。
快速排序
快速排序使用了D&C。对排序算法来说,基线条件为数组为空或只包含一个元素。
首先,从数组中选择一个元素,这个元素被称为基准值;
接下来,找出比基准值小的元素以及比基准值大的元素。
再对这两个子数组进行快速排序,直到满足基线条件。
注:归纳证明是一种证明算法行之有效的方式,它分两步:基线 条件和归纳条件。
#快速排序
def quicksrt(arr):
if len(arr)<2:
return arr
else:
pio=arr[0]
less=[i for i in arr[1:] if i<pio]
than=[i for i in arr[1:] if i>=pio]
return quicksrt(less)+[pio]+quicksrt(than)
print(quicksrt([4,5,7,2,3,9,4,0]))
运行结果:
[0, 2, 3, 4, 4, 5, 7, 9]
快速排序的最糟情况运行时间为O(n**2),与选择排序一样慢,但是他的平均排序时间为O(n*log n)。而合并排序总是O(n*log n)。但是这不是绝对的,合并排序的常量总是大于快速排序,所以一般情况下认为快速排序更快。
平均情况与最糟情况
假设要为从小到大的多个数排序,最糟情况就是每次都选第一个值作为基准值,这样每次操作时间都是O(n),共操作O(n)次,该算法的运行时间为O(n) * O(n) = O(n**2 )。而最佳情况每次都能选择最中间的数来排,就好像二分法一样层数为O(log n)(用技术术语说,调用栈的高度为O(log n)),而每层需要的时间为O(n)。因此整个算法需要的时间为O(n) * O(log n) = O(n log n)。
散列表
散列函数
散列函数“将输入映射到数字”。这个用python字典比较好理解,每次给定key都得到的是同一个数字,每个key都对应一个value。
散列函数总是将同样的输入映射到相同的索引。
散列函数将不同的输入映射到不同的索引。
散列函数知道数组有多大,只返回有效的索引。
说到字典你可能根本不需要自己去实现散列表,任一优秀的语言都提供了散列表实现。Python提供的散列表实现就是字典,你可使用函数dict来创建散列表。
这样散列表的概念就非常好理解了,散列表通常用于查找,在网站投票中还可以过滤掉已经投过票的人,也就是去重,还有就是对于一些经常访问的网站进行缓存也使用了散列表。缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中。
冲突
间接描述了散列表的性能,冲突就是:给两 个键分配的位置相同。处理冲突的方式 很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。如果一个散列表所有的值都放在第一个内存中呢,那和一个链表又有什么区别呢?最理想的情况是, 散列函数将键均匀地映射到散列表的不同位置。如果散列表存储的链表很长,散列表的速度将急剧下降。
性能
在平均情况下,散列表执行各种操作的时间都为O(1)。我们来将 散列表同数组和链表比较一下。
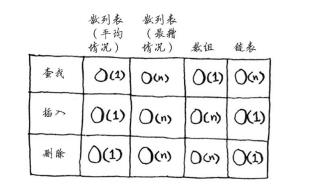
填装因子
用来描述性能的参数,值为散列表的元素数/位置总数。填装因子大于1时意味元素数大于位置数,这个时候可能就是要考虑调整散列表长度了。调整散列表长度的工作需要很长时间!你说得没错,调整长度的开销很大,因 此你不会希望频繁地这样做。但平均而言,即便考虑到调整长度所需的时间,散列表操作所需的时间也为O(1)。
广度优先搜索
如果你要从A点去往B点,这种问题被称为最短路径问题需要两个步骤。
(1) 使用图来建立问题模型。
(2) 使用广度优先搜索解决问题。
图是由节点和边组成的,图用于模拟不同的东西是如何相连的。
广度优先搜索是一种用于图的查找算法,可帮助回答两类问题。
第一类问题:从节点A出发,有前往节点B的路径吗?
第二类问题:从节点A出发,前往节点B的哪条路径最短?
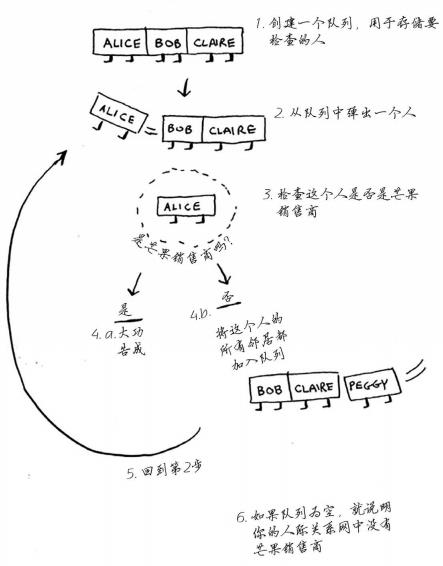
广度优先的工作原理图
要看你的认识的人中有没有芒果销售员,从你的朋友开始查每查一个朋友就把他的朋友加入你的查找列表队列的末尾,直到查完为止或者找到的第一个芒果销售员。在此过程中对于已经查过的人单独拿出来,因为重复查无意义甚至导致无限循环。
注: 有向图中的边为箭头,箭头的方向指定了关系的方向,例如,rama→adit表示rama欠adit钱。 无向图中的边不带箭头,其中的关系是双向的,例如,ross - rachel表示“ross与rachel约 会,而rachel也与ross约会”。
狄克斯特拉算法
还是解决最短路径的算法,不过他解决的是加权图的最短路径。也就是说在狄克斯特拉算法中,你给每段都分配了一个数字或权重,因此狄克斯特拉算法找出 的是总权重最小的路径。
狄克斯特拉算法包含4个步骤。
(1) 找出“最便宜”的节点,即可在最短时间内到达的节点。
(2) 更新该节点的邻居的开销。
(3) 重复这个过程,直到对图中的每个节点都这样做了。
(4) 计算最终路径。
要计算非加权图中的最短路径,可使用广度优先搜索。要计算加权图中的最短路径,可使用狄克斯特拉算法。
要注意的是狄克斯特拉算法只适用于无环图,并且狄克斯特拉算法无法计算负权的边。带负权的边要使用贝尔曼福德算法计算(这个我也不会)。
下面代码就实现了狄克斯特拉算法计算出最短路径的代码。
# 迪克斯塔拉算法求最短路径
graph = {}#先描述距离
graph["start"] = {}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {}
graph["a"]["fin"] = 1
graph["b"] = {}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5
graph["fin"] = {}
# 权重表
infinity = float("inf")
costs = {}
costs["a"] = 6
costs["b"] = 2
costs["fin"] = infinity
# the parents table
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
processed = []#已经算过的列表
def find_lowest_cost_node(costs):
lowest_cost = float("inf")#终点无限大
lowest_cost_node = None
# 遍历每一个节点
for node in costs:
cost = costs[node]
# 判断大小并且之前未计算过
if cost < lowest_cost and node not in processed:
lowest_cost = cost#如果有更小距离则更新
lowest_cost_node = node
return lowest_cost_node
# 未处理的成本最低的节点.
node = find_lowest_cost_node(costs)
# 处理完所有节点时循环结束
while node is not None:
cost = costs[node]
# 通过节点的所有邻居
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]#从此节点计算到下一节点的开销
# 如果是去这个邻居通过这个节点更便宜
if costs[n] > new_cost:
# 更新此节点最小值
costs[n] = new_cost
# 节点成为邻居最近的下一节点
parents[n] = node
#节点标记为已处理
processed.append(node)
#发现下一个节点与环
node = find_lowest_cost_node(costs)
print("Cost from the start to each node:")
print(costs)
运行结果:
Cost from the start to each node:
{\'a\': 5, \'fin\': 6, \'b\': 2}
贪婪算法
贪婪算法很简单:每步都采取最优的做法,最终得到的就是全局最优解。贪婪算法并非在任何情况下都行之有效,但它易于实现。
用一个简单的例子来解释一下。比如有下面一张课程表,你学要尽可能多的在一间教室里上最多的课。
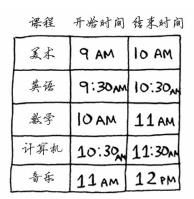
(1) 选出结束最早的课,它就是要在这间教室上的第一堂课。
(2) 接下来,必须选择第一堂课结束后才开始的课。同样,你选择结束最早的课,这将是要在这间教室上的第二堂课。
(3)重复第二步。
这就是贪婪算法。虽然贪婪算法是万能的但是他往往不是最优的,但是对于一些没有更好的解决方法,贪婪算法往往是最有效的。
集合覆盖问题
假设你办了一个电视节目你想在全国上映,但是每个电视台覆盖的范围都不一样,还可能有重复覆盖的区域。
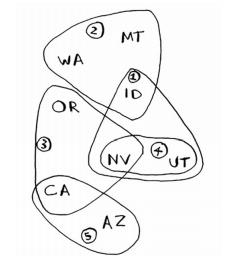
(1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有2n个。
(2) 在这些集合中,选出覆盖全美50个州的最小集合。问题是计算每个可能的广播台子集需要很长时间。由于可能的集合有2**n个,因此运行时间为 O(2**n )。

贪婪算法可化解危机!使用下面的贪婪算法可得到非常接近的解。
(1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖的州,也没有关系。
(2) 重复第一步,直到覆盖了所有的州。
这是一种近似算法(approximation algorithm)。在获得精确解需要的时间太长时,可使用近似算法。
判断近似算法优劣的标准如下:
速度有多快;
得到的近似解与最优解的接近程度。
这个问题的算法代码:
states_needed = set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
stations = {}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
final_stations = set()
while states_needed:
best_station = None
states_covered = set()
for station, states in stations.items():
covered = states_needed & states
if len(covered) > len(states_covered):
best_station = station
states_covered = covered
states_needed -= states_covered
final_stations.add(best_station)
print(final_stations)
运行结果;
{\'kone\', \'ktwo\', \'kthree\', \'kfive\'}
贪婪算法还可以求出旅行商问题的简单答案。
NP完全问题的简单定义是,以难解著称的问题,如旅行商问题和集合覆盖问题。NP算法本身不难,但是界定哪些问题应该使用NP算法求解更优却是个难点。要判断问题是不是NP完全问题很难,易于解决的问题和NP完全问题的差别通常很小。
如何判断问题是不是NP完全问题:
元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。
涉及“所有组合”的问题通常是NP完全问题。
不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。
如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。
如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。
如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。
动态规划
背包问题
一个小偷,背包容纳量为4,商店有三件商品可以偷,音响3000块重量4,电脑2000块重量3,吉他1500块重量1。
尝试一次次的试,时间为O(2**n),这种方法肯定可以使用NP算法啦,但是不是最优解。
动态规划先解决子问题,再逐步解决大问题。
每个动态规划算法都从一个网格开始,背包问题的网格如下。
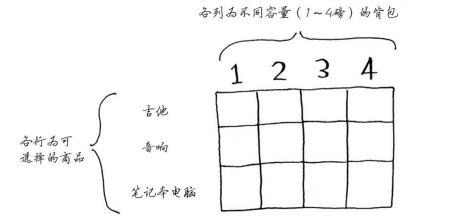
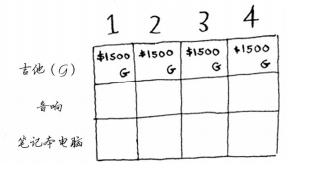
第一行是吉他行,你只能选择拿不拿吉他,只能拿其他肯定会拿偷啊,这样利益最大化。
第二行是音箱行,你可以选择吉他或音箱。
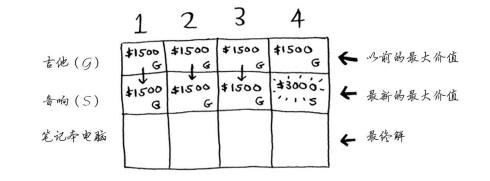
第三行电脑行,三种都可以选择。
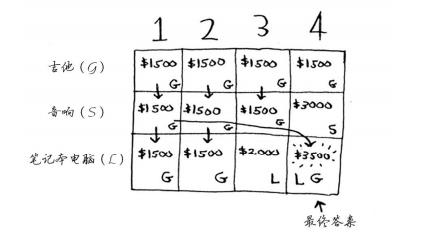
这里行排列的顺序变化了对结果没什么影响。并且最优解可能背包还没装满。
但仅当 每个子问题都是离散的,即不依赖于其他子问题时,动态规划才管用。
K最近邻算法
抽取事物特征并在坐标轴上给出横纵坐标打分,这等于抽象出空间中的点,然后使用毕达哥拉斯公式计算与其他点的距离来判断与哪些点更为相似。

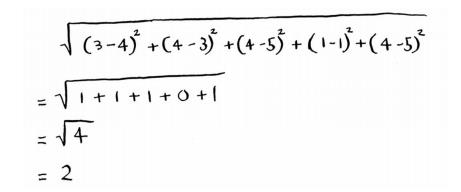
Priyanka和Morpheus的距离为24,所以可得出Priyanka的喜好更接近于Justin而不是Morpheus的结论。这样就可以依据Justin的喜好给Priyanka推荐电影啦。
回归
假设你不仅要向Priyanka推荐电影,还要预测她将给这部电影打多少分。为此,先找出与她最近的多个人,你求这些人打的分的平均值,结果为4.2。这就是回归(regression)。
你将使用KNN来做两项 基本工作——分类和回归:
分类就是编组;
回归就是预测结果(如一个数字)。
比起距离计算,我们平时工作中使用余弦相似度来打分更为准确常用。
KNN算法广泛应用于机器学习领域。OCR指的是光学字符识别(optical character recognition),这意味着你可拍摄印刷页面的照片,计算机将自动识别出其中的文字。
使用KNN。
(1) 浏览大量的数字图像,将这些数字的特征提取出来。
(2) 遇到新图像时,你提取该图像的特征,再找出它最近的邻居都是谁!
OCR算法提取线段、点和曲线等特征。遇到新字符时,可从中提取同样的特征。
这仅仅是编程算法的一小部分,在后面还有很多高级的算法等着我们,对于本文的一些代码,如果不太懂他的运行过程可以使用debug一步一步推导出来,算法是编程中极为核心的部分,你的代码的优秀程度与你的思维有很大的关系,希望初学python编程也能很有好的思维方式来解决遇到的问题,因为读这本书比较浅显,阅读也很快,所以可能存在着一些问题,希望各路大神批评指正