概要
把常用的机器学习算法:\\(k\\)-近邻算法、朴素贝叶斯、逻辑回归、\\(K\\)-均值聚类其思想有及 python 代码实现总结一下。做到既要知其然又要知其所以然。参考《机器学习实战》。
\\(k\\)-近邻算法
基本原理
\\(k\\)-近邻算法是分类数据最简单有效的方法。简单地来说,它采用测量不同特征值之间的距离方法进行分类。提取样本集中特征最相邻数据的分类标签,一般来说,我们只选择样本数据集中前 \\(k\\) 个最相似的数据。
代码实现
代码的关键是计算数据集中每个点与点之间的距离并按递增排序。牢记 distances.argsort() 返回的是数组 distances 中数值从小到大排序之后的索引位置,不得不说, python 的封装功能很强大。
def classify0(inX, dataSet, labels, k):
\'\'\'
inX: 用于分类的输入向量
dataSet: 输入的训练样本集
labels: 标签向量,数目与 dataSet 行数相同
k: 用于选择最近邻居的数目
\'\'\'
dataSetSize = dataSet.shape[0] # 样本数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #np.tile把数据inX扩展成第二个参数形状
sqDiffMat = diffMat**2 #平方求欧氏距离
sqDistances = sqDiffMat.sum(axis=1) # 列求和,返回数组
distances = sqDistances**0.5 # 得到欧式距离
sortedDistIndicies = distances.argsort() # 数值从小到大 的索引位置
classCount = {} # 创建空字典,字典是无顺序的
\'\'\'
得到字典的 key 值可以用 get() 方法,如果 key 不存在,可以返回 None,或者自己指定
的 value, 比如下边的如果 key 不存在就给 0 值
\'\'\'
for i in range(k): # 选择距离最小的 k 个点
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
\'\'\'
python字典的items方法作用:是可以将字典中的所有项,以列表方式返回,每项是元组。
因为字典是无序的,所以用items方法返回字典的所有项,也是没有顺序的。
eg:A = {\'a\':1, \'b\':2, \'c\':3} A.items() 输出为:
[(\'a\', 1), (\'c\', 3), (\'b\', 2)]
python字典的iteritems方法作用:与items方法相比作用大致相同,
只是它的返回值不是列表,而是一个迭代器。
\'\'\'
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,
# 参数为一些序号(即需要获取的数据在对象中的序号),
#itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值
sortedClassCount = sorted(classCount.iteritems(), #将字典变成迭代器(列表形式)
key=operator.itemgetter(1), reverse=True) # 排序为逆序,即从大到小
return sortedClassCount[0][0]
优缺点
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高,无法给出任何数据的基础结构信息
朴素贝叶斯
基本原理
贝叶斯决策理论的核心思想:选择具有最高概率的决策。
核心是贝叶斯准则,它告诉我们如何交换条件概率中的条件与结果,即如果已知 \\(P(x|c)\\),要求 \\(P(c|x)\\),那么可以使用下面的计算方法:
\\begin{align}
p(c|x) = \\frac{p(x|c)p(c)}{p(x)} \\notag
\\end{align}
朴素贝叶斯假设特征之间相互独立,这个假设正是朴素贝叶斯中“朴素”一词的含义。朴素贝叶斯分类器中的另一个假设是每个特征同等重要。这两个假设虽然存在一些小瑕疵,但朴素贝叶斯的实际效果却很好。
使用条件概率来分类
贝叶斯决策理论要求计算两个概率 \\(p(c_1|x)\\) 与 \\(p(c_2|x)\\)(对于二分类)。具体意义是:给定某个由 \\(x\\) 表示的数据点,那么该数据点来自类别 \\(c_1\\) 的概率是多少?来自 \\(c_2\\) 的概率又是多少?注意这些概率和 \\(p(x|c_1)\\) 并不一样,可以使用贝叶斯准则交换概率中条件与结果。使用这些定义,可以定义贝叶斯分类准则:
- 如果 \\(p(c_1|x) > p(c_2|x)\\),那么属于类别 \\(c_1\\).
- 如果 \\(p(c_1|x) < p(c_2|x)\\),那么属于类别 \\(c_2\\).
对于一个实际的问题,我们需要做以下步骤:
- 统计计算 \\(p(c_i),\\quad i=1,2\\).
- 接下来计算 \\(p(x| c_i)\\),这里要用到朴素贝叶斯假设,如果将 \\(x\\) 展开一个个独立特征,则 \\(p(x|c_i)=p(x_0,x_1,\\cdots,x_n | c_i)= p(x_0|c_i)p(x_1|c_i)\\cdots p(x_n|c_i)\\).(如果每个数字过小,可以用到取对数的技巧)
- 假如要分类的向量是 \\(w\\), 计算 \\(p(w|c_i)p(c_i),\\quad i=1,2\\),哪个值大归于哪个类。
优缺点
优点:在数据较少的情况下仍然有效,可以处理多类别问题
缺点:对于输入数据的准备方式较为敏感
逻辑回归
基本原理
逻辑回归的目标是寻找一个非线性函数 Sigmoid 的最佳拟合参数,求解过程由最优化算法来完成。最常用的就是梯度上升算法。逻辑回归其实包含非常多的内容,面试中经常会被问到的问题,请点击.
Sigmoid 函数具体的计算公式如下:
\\begin{align}
\\sigma(z) = \\frac{1}{1+\\mathrm{e}^{-z}} \\notag
\\end{align}
显然 \\(\\sigma(0) = 0.5\\). 为了实现 Logsitic 回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入 Sigmoid 函数中,进而得到一个范围在 \\(0 \\sim 1\\) 之间的数值。任何大于 \\(0.5\\) 的数据被分入 \\(1\\) 类,小于 \\(0.5\\) 即被归入 \\(0\\) 类。所以 Logistic 回归也可以被看成是一种概率估计。现在主要的问题是 :如何确定最佳回归系数?我们定义好代价函数之后,用梯度上升算法即可求解。
代码实现
该算法的主要部分就是梯度上升算法的编写,下面给出:
def gradAscent(dataMatIn, classLabels): # 梯度上升算法
m, n = np.shape(dataMatIn)
alpha = 0.001
maxCycles = 500
weights = np.ones(n) # 1*n 的数组
for k in range(maxCycles):
h = sigmoid(np.dot(dataMatIn, weights)) # 1*m 的数组,sigmoid 是 Sigmoid 函数,自己编写
error = classLabels - h
weights = weights+alpha*np.dot(error, dataMatIn) // 在这里是按差值方向调整,也可以求解出梯度
return weights
def stocGradAscent0(dataMatIn, classLabels, numIter=40): # 随机梯度上升算法
m, n = np.shape(dataMatIn)
#maxCycles = 500
weights = np.ones(n) # 初始化权重,1*n 的数组
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4 / (1.+j+i)+0.01 # 迭代步长设定
randIndex = int(np.random.uniform(0, len(dataIndex))) # 与梯度上升唯一的区别:随机选取更新
h = sigmoid(np.sum(dataMatIn[randIndex]*weights)) # 一个数
error = classLabels[randIndex] - h # 一个向量
weights = weights+alpha*error*dataMatIn[randIndex]
del(dataIndex[randIndex])
return weights
优缺点
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度可能不高
\\(K\\) 均值聚类
基本原理
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。\\(K\\) 均值聚类之所以称之为 \\(K\\) 均值是因为它可以发现 \\(k\\) 个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
\\(K\\) 均值聚是发现给定数据集中 \\(k\\) 个簇的算法。簇个数 \\(k\\) 是用户给定的,每一个簇通过其质心,即簇中所有点的中心来描述。其算法流程:
创建 k 个点作为起始质心(经常随机选择)
当任意一个点的簇分配结果发生改变时(说明还没收敛)
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
代码实现
假设我们对一堆数据点进行聚类操作,数据点来自机器学习实战。代码如下:
# coding:utf-8
import numpy as np
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split(\'\\t\')
fltLine = list(map(float,curLine)) #map all elements to float()
dataMat.append(fltLine) #一个列表包含很多列表
return np.array(dataMat)
def distEclud(vecA, vecB):
return np.sqrt(sum(np.power(vecA - vecB, 2))) #la.norm(vecA-vecB)
def randCent(dataSet, k): # 构建簇质心,矩阵dataSet 每行表示一个样本
n = np.shape(dataSet)[1]
centroids = np.zeros((k,n)) #create centroid mat
for j in range(n):
minJ = min(dataSet[:,j]) # 随机质心必须要在整个数据集的边界之内
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = (minJ + rangeJ * np.random.rand(k,1)).flatten() #随机
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = np.shape(dataSet)[0] # m 个样本
clusterAssment = np.zeros((m,2))#创建一个矩阵来存储每个点的分配结果
#两列:一列记录索引值,第二列存储误差
centroids = createCent(dataSet, k) # 创建 k 个质心
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m): #将每个点分配到最近的质心
minDist = np.inf; minIndex = -1
for j in range(k): # 寻找最近的质心
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: # 直到数据点的簇分配结果不再改变
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
#print (centroids)
for cent in range(k): #重新计算质心,更新质心的位置
ptsInClust = dataSet[np.nonzero(clusterAssment[:,0] == cent)] # 通过数组过滤来获得给定簇的所有点
centroids[cent,:] = np.mean(ptsInClust, axis=0) #计算所有点的均值
return centroids, clusterAssment # 返回所有的类质心与点分配结果
import matplotlib.pyplot as plt
if __name__ == \'__main__\':
datMat = loadDataSet(\'testSet.txt\')
k = 4
centroids = randCent(datMat, k)
#print(centroids)
myCentroids, clustAssing = kMeans(datMat, 4)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
#ax.scatter(datMat[:,0], datMat[:,1]) # 必须是 array 类型
scatterMarkers = [\'s\', \'o\', \'^\', \'8\', \'p\', \'d\', \'v\', \'h\', \'>\', \'<\']
for i in range(k):
ptsIncurrCluster = datMat[np.nonzero(clustAssing[:,0] == i)]
ax.scatter(ptsIncurrCluster[:,0], ptsIncurrCluster[:,1], marker=scatterMarkers[i], s=90)
ax.scatter(myCentroids[:,0], myCentroids[:,1], marker=\'+\', s=300)
plt.show()
可视化如下图:
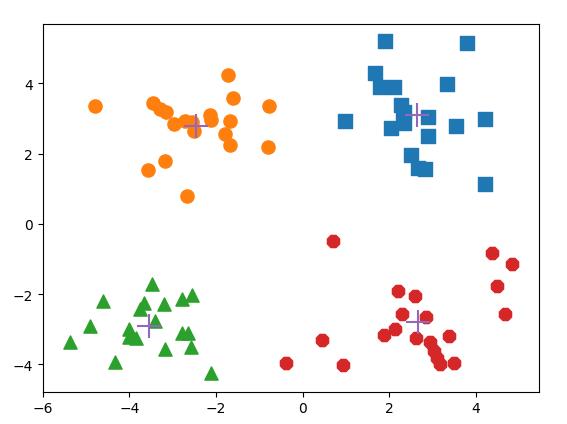
由于初始质心的随机选择,每次运行结果会稍微有所不同。
优缺点
- 优点:容易实现
- 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
如何确定超参 \\(k\\)?
如果 \\(k\\) 选择的过于小,该算法收敛到了局部最小值,而非全局最小值。一种用于度量聚类效果的指标是 SSE(Sum of Squared Error,误差平方和),对应程度中 clusterAssment 矩阵的第一列之和。SSE 值越小表示数据点越接近于它们的质心,聚类效果也越好。一种肯定可以降低 SSE 值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
那么如何提高呢?一种方法是将具有最大 SSE 值的簇划分成两个簇。具体实现时可以将最大簇包含的点过滤出来并在这些点上运行 \\(K\\) 均值算法,为了保持簇总数不变,可以将某两个簇进行合并,这两个簇的选择一般有两种可以量化的方法:合并最近的质心,或者合并两个使得 SSE 增幅最小的质心。
二分 \\(K\\) 均值算法
为克服 \\(K\\) 均值算法收敛于局部最小值的问题,有人提出了另一个称为二分 \\(K\\) 均值的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低 SSE 的值。上述基于 SSE 的划分过程为断重复,直到得到用户指定的簇数为止。另一种做法是选择 SSE 最大的簇进行划分,直到簇数目达到用户指定的数目为止。