x264代码剖析(十五):核心算法之宏块编码中的变换编码
Posted 成长Bar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了x264代码剖析(十五):核心算法之宏块编码中的变换编码相关的知识,希望对你有一定的参考价值。
x264代码剖析(十五):核心算法之宏块编码中的变换编码
为了进一步节省图像的传输码率,需要对图像进行压缩,通常采用变换编码及量化来消除图像中的相关性以减少图像编码的动态范围。本文主要介绍变换编码的相关内容,并给出x264中变换编码的代码分析。
1、变换编码
变换编码将图像时域信号变换成频域信号,在频域中图像信号能量大部分集中在低频区域,相对时域信号,码率有较大的下降。 H.264对图像或预测残差采用4×4整数离散余弦变换技术,避免了以往标准中使用的通用8×8离散余弦变换逆变换经常出现的失配问题。
在图像编码中,变换编码和量化从原理上讲是两个独立的过程。但在H.264中,将两个过程中的乘法合二为一,并进一步采用整数运算,减少编解码的运算量,提高图像压缩的实时性,这些措施对峰值信噪比(PSNR)的影响很小,一般低于0.02dB,可不计。H.264中整数变换及量化具体过程如下图所示,其中,如果输入块是色度块或帧内16×16预测模式的亮度块,则将宏块中各4×4块的整数余弦变换的直流分量组合起来再进行 Hadamard 变换,进一步压缩码率。
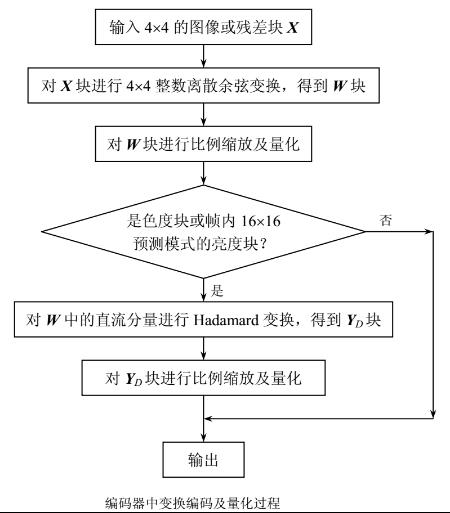
下面给出编码器中变换编码及量化过程的流程。

DCT变换的核心理念就是把图像的低频信息(对应大面积平坦区域)变换到系数矩阵的左上角,而把高频信息变换到系数矩阵的右下角,这样就可以在压缩的时候(量化)去除掉人眼不敏感的高频信息(位于矩阵右下角的系数)从而达到压缩数据的目的。早期的DCT变换都使用了8x8的矩阵(变换系数为小数),如下左图所示。在H.264标准中新提出了一种4x4的矩阵,如下右图所示。这种4x4 DCT变换的系数都是整数,一方面提高了运算的准确性,一方面也利于代码的优化。


2、DCT源码分析
DCT模块的源码主要包括以下内容(均处于common/dct.c中),本文也主要分析以下的函数:
(1)、x264_dct_init()函数:初始化DCT变换和DCT反变换相关的汇编函数;
(2)、sub4x4_dct()函数:将两块4x4的图像相减求残差后,进行DCT变换;
(3)、add4x4_idct()函数:将残差数据进行DCT反变换,并将变换后得到的残差像素数据叠加到预测数据上;
(4)、sub8x8_dct()函数:将两块8x8的图像相减求残差后,进行4x4DCT变换;
(5)、sub16x16_dct()函数:将两块16x16的图像相减求残差后,进行4x4DCT变换;
(6)、dct4x4dc()函数:将输入的4x4图像块进行Hadamard变换。
2.1、x264_dct_init()函数
初始化函数x264_dct_init()是对x264_dct_function_t结构体中的函数指针进行了赋值。X264运行的过程中只要调用x264_dct_function_t的函数指针就可以完成相应的功能,主要是用于初始化DCT变换和DCT反变换相关的汇编函数,处于common/dct.c。
对应的函数调用关系图如下:

对应的代码分析如下:
/******************************************************************/
/******************************************************************/
/*
======Analysed by RuiDong Fang
======Csdn Blog:http://blog.csdn.net/frd2009041510
======Date:2016.03.23
*/
/******************************************************************/
/******************************************************************/
/************====== DCT ======************/
/*
功能:DCT初始化,x264_dct_init()被x264_encoder_open()函数调用
*/
/****************************************************************************
* x264_dct_init:
****************************************************************************/
void x264_dct_init( int cpu, x264_dct_function_t *dctf )
{
/*===== 4x4DCT变换 =====*/
dctf->sub4x4_dct = sub4x4_dct;
dctf->add4x4_idct = add4x4_idct;
//8x8块:分解成4个4x4DCT变换,调用4次sub4x4_dct()
dctf->sub8x8_dct = sub8x8_dct;
dctf->sub8x8_dct_dc = sub8x8_dct_dc;
dctf->add8x8_idct = add8x8_idct;
dctf->add8x8_idct_dc = add8x8_idct_dc;
dctf->sub8x16_dct_dc = sub8x16_dct_dc;
/*===== 16x16DCT变换:分解成4个8x8块,调用4次sub8x8_dct(),实际上每个sub8x8_dct()又分解成4个4x4DCT变换,调用4次sub4x4_dct() =====*/
dctf->sub16x16_dct = sub16x16_dct;
dctf->add16x16_idct = add16x16_idct;
dctf->add16x16_idct_dc = add16x16_idct_dc;
/*===== 8x8DCT变换:后缀是_dct8 =====*/
dctf->sub8x8_dct8 = sub8x8_dct8;
dctf->add8x8_idct8 = add8x8_idct8;
dctf->sub16x16_dct8 = sub16x16_dct8;
dctf->add16x16_idct8 = add16x16_idct8;
/*===== Hadamard变换 =====*/
dctf->dct4x4dc = dct4x4dc;
dctf->idct4x4dc = idct4x4dc;
dctf->dct2x4dc = dct2x4dc;
#if HIGH_BIT_DEPTH
#if HAVE_MMX
if( cpu&X264_CPU_MMX )
{
dctf->sub4x4_dct = x264_sub4x4_dct_mmx;
dctf->sub8x8_dct = x264_sub8x8_dct_mmx;
dctf->sub16x16_dct = x264_sub16x16_dct_mmx;
}
if( cpu&X264_CPU_SSE2 )
{
dctf->add4x4_idct = x264_add4x4_idct_sse2;
dctf->dct4x4dc = x264_dct4x4dc_sse2;
dctf->idct4x4dc = x264_idct4x4dc_sse2;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_sse2;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_sse2;
dctf->add8x8_idct = x264_add8x8_idct_sse2;
dctf->add16x16_idct = x264_add16x16_idct_sse2;
dctf->add8x8_idct8 = x264_add8x8_idct8_sse2;
dctf->add16x16_idct8 = x264_add16x16_idct8_sse2;
dctf->sub8x8_dct_dc = x264_sub8x8_dct_dc_sse2;
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_sse2;
dctf->sub8x16_dct_dc = x264_sub8x16_dct_dc_sse2;
dctf->add16x16_idct_dc= x264_add16x16_idct_dc_sse2;
}
if( cpu&X264_CPU_SSE4 )
{
dctf->sub8x8_dct8 = x264_sub8x8_dct8_sse4;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_sse4;
}
if( cpu&X264_CPU_AVX )
{
dctf->add4x4_idct = x264_add4x4_idct_avx;
dctf->dct4x4dc = x264_dct4x4dc_avx;
dctf->idct4x4dc = x264_idct4x4dc_avx;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_avx;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_avx;
dctf->add8x8_idct = x264_add8x8_idct_avx;
dctf->add16x16_idct = x264_add16x16_idct_avx;
dctf->add8x8_idct8 = x264_add8x8_idct8_avx;
dctf->add16x16_idct8 = x264_add16x16_idct8_avx;
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_avx;
dctf->sub8x16_dct_dc = x264_sub8x16_dct_dc_avx;
dctf->add16x16_idct_dc= x264_add16x16_idct_dc_avx;
}
#endif // HAVE_MMX
#else // !HIGH_BIT_DEPTH
#if HAVE_MMX //MMX版本
if( cpu&X264_CPU_MMX )
{
dctf->sub4x4_dct = x264_sub4x4_dct_mmx;
dctf->add4x4_idct = x264_add4x4_idct_mmx;
dctf->idct4x4dc = x264_idct4x4dc_mmx;
dctf->sub8x8_dct_dc = x264_sub8x8_dct_dc_mmx2;
#if !ARCH_X86_64 //X86平台的汇编函数初始化
dctf->sub8x8_dct = x264_sub8x8_dct_mmx;
dctf->sub16x16_dct = x264_sub16x16_dct_mmx;
dctf->add8x8_idct = x264_add8x8_idct_mmx;
dctf->add16x16_idct = x264_add16x16_idct_mmx;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_mmx;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_mmx;
dctf->add8x8_idct8 = x264_add8x8_idct8_mmx;
dctf->add16x16_idct8= x264_add16x16_idct8_mmx;
#endif
}
if( cpu&X264_CPU_MMX2 )
{
dctf->dct4x4dc = x264_dct4x4dc_mmx2;
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_mmx2;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_mmx2;
}
if( cpu&X264_CPU_SSE2 )
{
dctf->sub8x8_dct8 = x264_sub8x8_dct8_sse2;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_sse2;
dctf->sub8x8_dct_dc = x264_sub8x8_dct_dc_sse2;
dctf->sub8x16_dct_dc= x264_sub8x16_dct_dc_sse2;
dctf->add8x8_idct8 = x264_add8x8_idct8_sse2;
dctf->add16x16_idct8= x264_add16x16_idct8_sse2;
if( !(cpu&X264_CPU_SSE2_IS_SLOW) )
{
dctf->sub8x8_dct = x264_sub8x8_dct_sse2;
dctf->sub16x16_dct = x264_sub16x16_dct_sse2;
dctf->add8x8_idct = x264_add8x8_idct_sse2;
dctf->add16x16_idct = x264_add16x16_idct_sse2;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_sse2;
}
}
if( (cpu&X264_CPU_SSSE3) && !(cpu&X264_CPU_SSE2_IS_SLOW) )
{
dctf->sub8x16_dct_dc = x264_sub8x16_dct_dc_ssse3;
if( !(cpu&X264_CPU_SLOW_ATOM) )
{
dctf->sub4x4_dct = x264_sub4x4_dct_ssse3;
dctf->sub8x8_dct = x264_sub8x8_dct_ssse3;
dctf->sub16x16_dct = x264_sub16x16_dct_ssse3;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_ssse3;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_ssse3;
if( !(cpu&X264_CPU_SLOW_PSHUFB) )
{
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_ssse3;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_ssse3;
}
}
}
if( cpu&X264_CPU_SSE4 )
dctf->add4x4_idct = x264_add4x4_idct_sse4;
if( cpu&X264_CPU_AVX )
{
dctf->add4x4_idct = x264_add4x4_idct_avx;
dctf->add8x8_idct = x264_add8x8_idct_avx;
dctf->add16x16_idct = x264_add16x16_idct_avx;
dctf->add8x8_idct8 = x264_add8x8_idct8_avx;
dctf->add16x16_idct8 = x264_add16x16_idct8_avx;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_avx;
dctf->sub8x8_dct = x264_sub8x8_dct_avx;
dctf->sub16x16_dct = x264_sub16x16_dct_avx;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_avx;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_avx;
}
if( cpu&X264_CPU_XOP )
{
dctf->sub8x8_dct = x264_sub8x8_dct_xop;
dctf->sub16x16_dct = x264_sub16x16_dct_xop;
}
if( cpu&X264_CPU_AVX2 )
{
dctf->add8x8_idct = x264_add8x8_idct_avx2;
dctf->add16x16_idct = x264_add16x16_idct_avx2;
dctf->sub8x8_dct = x264_sub8x8_dct_avx2;
dctf->sub16x16_dct = x264_sub16x16_dct_avx2;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_avx2;
#if ARCH_X86_64
dctf->sub16x16_dct8 = x264_sub16x16_dct8_avx2;
#endif
}
#endif //HAVE_MMX
#if HAVE_ALTIVEC
if( cpu&X264_CPU_ALTIVEC )
{
dctf->sub4x4_dct = x264_sub4x4_dct_altivec;
dctf->sub8x8_dct = x264_sub8x8_dct_altivec;
dctf->sub16x16_dct = x264_sub16x16_dct_altivec;
dctf->add4x4_idct = x264_add4x4_idct_altivec;
dctf->add8x8_idct = x264_add8x8_idct_altivec;
dctf->add16x16_idct = x264_add16x16_idct_altivec;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_altivec;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_altivec;
dctf->add8x8_idct8 = x264_add8x8_idct8_altivec;
dctf->add16x16_idct8= x264_add16x16_idct8_altivec;
}
#endif
#if HAVE_ARMV6 || ARCH_AARCH64 //ARM平台的汇编函数初始化
if( cpu&X264_CPU_NEON )
{
dctf->sub4x4_dct = x264_sub4x4_dct_neon;
dctf->sub8x8_dct = x264_sub8x8_dct_neon;
dctf->sub16x16_dct = x264_sub16x16_dct_neon;
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_neon;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_neon;
dctf->sub8x8_dct_dc = x264_sub8x8_dct_dc_neon;
dctf->dct4x4dc = x264_dct4x4dc_neon;
dctf->idct4x4dc = x264_idct4x4dc_neon;
dctf->add4x4_idct = x264_add4x4_idct_neon;
dctf->add8x8_idct = x264_add8x8_idct_neon;
dctf->add16x16_idct = x264_add16x16_idct_neon;
dctf->sub8x8_dct8 = x264_sub8x8_dct8_neon;
dctf->sub16x16_dct8 = x264_sub16x16_dct8_neon;
dctf->add8x8_idct8 = x264_add8x8_idct8_neon;
dctf->add16x16_idct8= x264_add16x16_idct8_neon;
dctf->sub8x16_dct_dc= x264_sub8x16_dct_dc_neon;
}
#endif
#if HAVE_MSA
if( cpu&X264_CPU_MSA )
{
dctf->sub4x4_dct = x264_sub4x4_dct_msa;
dctf->sub8x8_dct = x264_sub8x8_dct_msa;
dctf->sub16x16_dct = x264_sub16x16_dct_msa;
dctf->sub8x8_dct_dc = x264_sub8x8_dct_dc_msa;
dctf->sub8x16_dct_dc = x264_sub8x16_dct_dc_msa;
dctf->dct4x4dc = x264_dct4x4dc_msa;
dctf->idct4x4dc = x264_idct4x4dc_msa;
dctf->add4x4_idct = x264_add4x4_idct_msa;
dctf->add8x8_idct = x264_add8x8_idct_msa;
dctf->add8x8_idct_dc = x264_add8x8_idct_dc_msa;
dctf->add16x16_idct = x264_add16x16_idct_msa;
dctf->add16x16_idct_dc = x264_add16x16_idct_dc_msa;
dctf->add8x8_idct8 = x264_add8x8_idct8_msa;
dctf->add16x16_idct8 = x264_add16x16_idct8_msa;
}
#endif
#endif // HIGH_BIT_DEPTH
}
从源代码可以看出,x264_dct_init()初始化了一系列的DCT变换的函数,这些DCT函数名称有如下规律:
(1)、DCT函数名称前面有“sub”,代表对两块像素相减得到残差之后,再进行DCT变换。
(2)、DCT反变换函数名称前面有“add”,代表将DCT反变换之后的残差数据叠加到预测数据上。
(3)、以“dct8”为结尾的函数使用了8x8DCT,其余函数是用的都是4x4DCT。
x264_dct_init()的输入参数x264_dct_function_t是一个结构体,其中包含了各种DCT函数的接口。x264_dct_function_t的定义如下代码:
typedef struct
{
// pix1 stride = FENC_STRIDE
// pix2 stride = FDEC_STRIDE
// p_dst stride = FDEC_STRIDE
void (*sub4x4_dct) ( dctcoef dct[16], pixel *pix1, pixel *pix2 );
void (*add4x4_idct) ( pixel *p_dst, dctcoef dct[16] );
void (*sub8x8_dct) ( dctcoef dct[4][16], pixel *pix1, pixel *pix2 );
void (*sub8x8_dct_dc)( dctcoef dct[4], pixel *pix1, pixel *pix2 );
void (*add8x8_idct) ( pixel *p_dst, dctcoef dct[4][16] );
void (*add8x8_idct_dc) ( pixel *p_dst, dctcoef dct[4] );
void (*sub8x16_dct_dc)( dctcoef dct[8], pixel *pix1, pixel *pix2 );
void (*sub16x16_dct) ( dctcoef dct[16][16], pixel *pix1, pixel *pix2 );
void (*add16x16_idct)( pixel *p_dst, dctcoef dct[16][16] );
void (*add16x16_idct_dc) ( pixel *p_dst, dctcoef dct[16] );
void (*sub8x8_dct8) ( dctcoef dct[64], pixel *pix1, pixel *pix2 );
void (*add8x8_idct8) ( pixel *p_dst, dctcoef dct[64] );
void (*sub16x16_dct8) ( dctcoef dct[4][64], pixel *pix1, pixel *pix2 );
void (*add16x16_idct8)( pixel *p_dst, dctcoef dct[4][64] );
void (*dct4x4dc) ( dctcoef d[16] );
void (*idct4x4dc)( dctcoef d[16] );
void (*dct2x4dc)( dctcoef dct[8], dctcoef dct4x4[8][16] );
} x264_dct_function_t;
2.2、sub4x4_dct()函数与add4x4_idct()函数
本节分析4*4DCT变换函数sub4x4_dct()和4*4DCT反变换函数add4x4_idct(),它们均处于common/dct.c中。
4*4DCT变换函数sub4x4_dct()完成的功能是:将两块4x4的图像相减求残差后,进行DCT变换,从源代码可以看出,sub4x4_dct()首先调用pixel_sub_wxh()求出两个输入图像块的残差,然后使用蝶形快速算法计算残差图像的DCT系数。对应的代码分析如下:
/************====== 4*4DCT变换函数sub4x4_dct() ======************/
/*
功能:sub4x4_dct()首先调用pixel_sub_wxh()求出两个输入图像块的残差,然后使用蝶形快速算法计算残差图像的DCT系数,返回dct[16]
*/
static void sub4x4_dct( dctcoef dct[16], pixel *pix1, pixel *pix2 )
{
dctcoef d[16];
dctcoef tmp[16];
//获取残差数据,存入d[16],pix1一般为编码帧(enc),pix2一般为重建帧(dec)
pixel_sub_wxh( d, 4, pix1, FENC_STRIDE, pix2, FDEC_STRIDE ); //求出两个输入图像块的残差
//蝶形算法:横向4个像素
for( int i = 0; i < 4; i++ )
{
int s03 = d[i*4+0] + d[i*4+3];
int s12 = d[i*4+1] + d[i*4+2];
int d03 = d[i*4+0] - d[i*4+3];
int d12 = d[i*4+1] - d[i*4+2];
tmp[0*4+i] = s03 + s12;
tmp[1*4+i] = 2*d03 + d12;
tmp[2*4+i] = s03 - s12;
tmp[3*4+i] = d03 - 2*d12;
}
//蝶形算法:纵向
for( int i = 0; i < 4; i++ )
{
int s03 = tmp[i*4+0] + tmp[i*4+3];
int s12 = tmp[i*4+1] + tmp[i*4+2];
int d03 = tmp[i*4+0] - tmp[i*4+3];
int d12 = tmp[i*4+1] - tmp[i*4+2];
dct[i*4+0] = s03 + s12;
dct[i*4+1] = 2*d03 + d12;
dct[i*4+2] = s03 - s12;
dct[i*4+3] = d03 - 2*d12;
}
}
求残差的代码如下:
/************====== 求残差 ======************/
/*
功能:求残差(注意求的是一个“方块”形像素)
*
* 参数的含义如下:
* diff:输出的残差数据
* i_size:方块的大小
* pix1:输入数据1
* i_pix1:输入数据1一行像素大小(stride)
* pix2:输入数据2
* i_pix2:输入数据2一行像素大小(stride)
*
*/
static inline void pixel_sub_wxh( dctcoef *diff, int i_size,
pixel *pix1, int i_pix1, pixel *pix2, int i_pix2 )
{
for( int y = 0; y < i_size; y++ )
{
for( int x = 0; x < i_size; x++ )
diff[x + y*i_size] = pix1[x] - pix2[x];//求残差
pix1 += i_pix1;//前进到下一行
pix2 += i_pix2;//前进到下一行
}
}
4*4DCT反变换函数add4x4_idct()完成的功能是:首先采用快速蝶形算法对DCT系数进行DCT反变换后得到残差像素数据,然后再将残差数据叠加到p_dst指向的像素上。需要注意这里是“叠加”而不是“赋值”。对应的代码分析如下:
/************====== 4*4DCT反变换函数add4x4_idct() ======************/
/*
功能:首先采用快速蝶形算法对DCT系数进行DCT反变换后得到残差像素数据,然后再将残差数据叠加到p_dst指向的像素上。
*/
static void add4x4_idct( pixel *p_dst, dctcoef dct[16] )
{
dctcoef d[16];
dctcoef tmp[16];
//快速蝶形算法对DCT系数进行DCT反变换
for( int i = 0; i < 4; i++ )
{
int s02 = dct[0*4+i] + dct[2*4+i];
int d02 = dct[0*4+i] - dct[2*4+i];
int s13 = dct[1*4+i] + (dct[3*4+i]>>1);
int d13 = (dct[1*4+i]>>1) - dct[3*4+i];
tmp[i*4+0] = s02 + s13;
tmp[i*4+1] = d02 + d13;
tmp[i*4+2] = d02 - d13;
tmp[i*4+3] = s02 - s13;
}
for( int i = 0; i < 4; i++ )
{
int s02 = tmp[0*4+i] + tmp[2*4+i];
int d02 = tmp[0*4+i] - tmp[2*4+i];
int s13 = tmp[1*4+i] + (tmp[3*4+i]>>1);
int d13 = (tmp[1*4+i]>>1) - tmp[3*4+i];
d[0*4+i] = ( s02 + s13 + 32 ) >> 6;
d[1*4+i] = ( d02 + d13 + 32 ) >> 6;
d[2*4+i] = ( d02 - d13 + 32 ) >> 6;
d[3*4+i] = ( s02 - s13 + 32 ) >> 6;
}
//将残差数据叠加到p_dst指向的像素上
for( int y = 0; y < 4; y++ )
{
for( int x = 0; x < 4; x++ )
p_dst[x] = x264_clip_pixel( p_dst[x] + d[y*4+x] );
p_dst += FDEC_STRIDE;
}
}
2.3、sub8x8_dct()函数
sub8x8_dct()可以将两块8x8的图像相减求残差后,进行4x4DCT变换,从源代码可以看出, sub8x8_dct()将8x8的图像块分成4个4x4的图像块,分别调用了sub4x4_dct()。该函数的定义位于common\\dct.c,对应的代码分析如下:
/************====== sub8x8_dct函数 ======************/
/*
功能:8x8块:分解成4个4x4DCT变换,调用4次sub4x4_dct(),返回dct[4][16]
*/
static void sub8x8_dct( dctcoef dct[4][16], pixel *pix1, pixel *pix2 )
{
/*
* 8x8 宏块被划分为4个4x4子块
*
* +---+---+
* | 0 | 1 |
* +---+---+
* | 2 | 3 |
* +---+---+
*
*/
sub4x4_dct( dct[0], &pix1[0], &pix2[0] );
sub4x4_dct( dct[1], &pix1[4], &pix2[4] );
sub4x4_dct( dct[2], &pix1[4*FENC_STRIDE+0], &pix2[4*FDEC_STRIDE+0] );
sub4x4_dct( dct[3], &pix1[4*FENC_STRIDE+4], &pix2[4*FDEC_STRIDE+4] );
}
2.4、sub16x16_dct()函数
sub16x16_dct()可以将两块16x16的图像相减求残差后,进行4x4DCT变换。该函数的定义位于common\\dct.c,从源代码可以看出, sub8x8_dct()将16x16的图像块分成4个8x8的图像块,分别调用了sub8x8_dct()。而sub8x8_dct()实际上又调用了4次sub4x4_dct()。所以可以得知,不论sub16x16_dct(),sub8x8_dct()还是sub4x4_dct(),本质都是进行4x4DCT。对应的代码分析如下:
/************====== sub16x16_dct函数 ======************/
/*
功能:16x16块:分解成4个8x8的块做DCT变换,调用4次sub8x8_dct(),返回dct[16][16]
*/
static void sub16x16_dct( dctcoef dct[16][16], pixel *pix1, pixel *pix2 )
{
/*
* 16x16 宏块被划分为4个8x8子块
*
* +--------+--------+
* | | |
* | 0 | 1 |
* | | |
* +--------+--------+
* | | |
* | 2 | 3 |
* | | |
* +--------+--------+
*
*/
sub8x8_dct( &dct[ 0], &pix1[0], &pix2[0] );
sub8x8_dct( &dct[ 4], &pix1[8], &pix2[8] );
sub8x8_dct( &dct[ 8], &pix1[8*FENC_STRIDE+0], &pix2[8*FDEC_STRIDE+0] );
sub8x8_dct( &dct[12], &pix1[8*FENC_STRIDE+8], &pix2[8*FDEC_STRIDE+8] );
}
2.5、dct4x4dc()函数
dct4x4dc()可以将输入的4x4图像块进行Hadamard变换。该函数的定义位于common\\dct.c,从源代码可以看出,dct4x4dc()实现了Hadamard快速蝶形算法,对应的代码分析如下:
/************====== dct4x4dc()函数 ======************/
/*
功能:dct4x4dc()可以将输入的4x4图像块进行Hadamard变换
*/
static void dct4x4dc( dctcoef d[16] )
{
dctcoef tmp[16];
for( int i = 0; i < 4; i++ ) //蝶形算法:横向的4个像素
{
int s01 = d[i*4+0] + d[i*4+1];
int d01 = d[i*4+0] - d[i*4+1];
int s23 = d[i*4+2] + d[i*4+3];
int d23 = d[i*4+2] - d[i*4+3];
tmp[0*4+i] = s01 + s23;
tmp[1*4+i] = s01 - s23;
tmp[2*4+i] = d01 - d23;
tmp[3*4+i] = d01 + d23;
}
for( int i = 0; i < 4; i++ ) //蝶形算法:纵向
{
int s01 = tmp[i*4+0] + tmp[i*4+1];
int d01 = tmp[i*4+0] - tmp[i*4+1];
int s23 = tmp[i*4+2] + tmp[i*4+3];
int d23 = tmp[i*4+2] - tmp[i*4+3];
d[i*4+0] = ( s01 + s23 + 1 ) >> 1;
d[i*4+1] = ( s01 - s23 + 1 ) >> 1;
d[i*4+2] = ( d01 - d23 + 1 ) >> 1;
d[i*4+3] = ( d01 + d23 + 1 ) >> 1;
}
}
 x264的变换编码的主要函数基本都在这儿,下一篇文章将分析宏块编码函数中的量化编码。
x264的变换编码的主要函数基本都在这儿,下一篇文章将分析宏块编码函数中的量化编码。
以上是关于x264代码剖析(十五):核心算法之宏块编码中的变换编码的主要内容,如果未能解决你的问题,请参考以下文章
x264代码剖析(十七):核心算法之熵编码(Entropy Encoding)