关于一致性hash算法
Posted 张小贱1987
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于一致性hash算法相关的知识,希望对你有一定的参考价值。
在大型web应用中,缓存可算是当今的一个标准开发配置了。在大规模的缓存应用中,应运而生了分布式缓存系统。分布式缓存系统的基本原理,大家也有所耳闻。key-value如何均匀的分散到集群中?说到此,最常规的方式莫过于hash取模的方式。比如集群中可用机器适量为N,那么key值为K的的数据请求很简单的应该路由到hash(K) mod N对应的机器。的确,这种结构是简单的,也是实用的。但是在一些高速发展的web系统中,这样的解决方案仍有些缺陷。随着系统访问压力的增长,缓存系统不得不通过增加机器节点的方式提高集群的相应速度和数据承载量。增加机器意味着按照hash取模的方式,在增加机器节点的这一时刻,大量的缓存命不中,缓存数据需要重新建立,甚至是进行整体的缓存数据迁移,瞬间会给DB带来极高的系统负载,设置导致DB服务器宕机。 那么就没有办法解决hash取模的方式带来的诟病吗?看下文。
一致性哈希(Consistent Hashing):
选择具体的机器节点不在只依赖需要缓存数据的key的hash本身了,而是机器节点本身也进行了hash运算。
(1) hash机器节点
首先求出机器节点的hash值(怎么算机器节点的hash?ip可以作为hash的参数吧。。当然还有其他的方法了),然后将其分布到0~2^32的一个圆环上(顺时针分布)。如下图所示: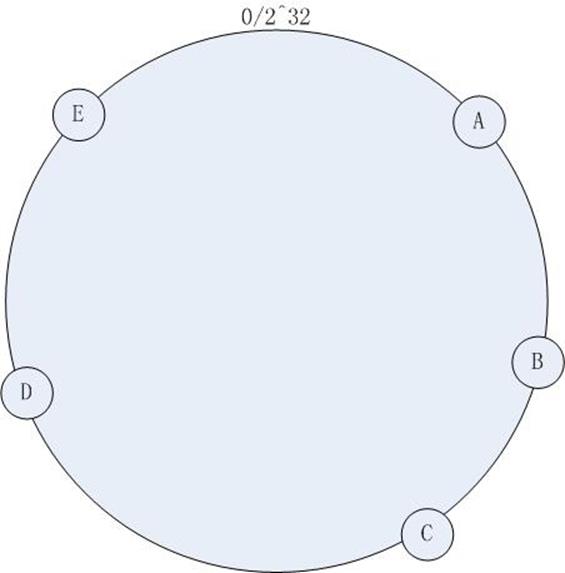
集群中有机器:A , B, C, D, E五台机器,通过一定的hash算法我们将其分布到如上图所示的环上。
(2)访问方式
如果有一个写入缓存的请求,其中Key值为K,计算器hash值Hash(K), Hash(K) 对应于图 – 1环中的某一个点,如果该点对应没有映射到具体的某一个机器节点,那么顺时针查找,直到第一次找到有映射机器的节点,该节点就是确定的目标节点,如果超过了2^32仍然找不到节点,则命中第一个机器节点。比如 Hash(K) 的值介于A~B之间,那么命中的机器节点应该是B节点(如上图 )。
(3)增加节点的处理
如上图 – 1,在原有集群的基础上欲增加一台机器F,增加过程如下:
计算机器节点的Hash值,将机器映射到环中的一个节点,如下图: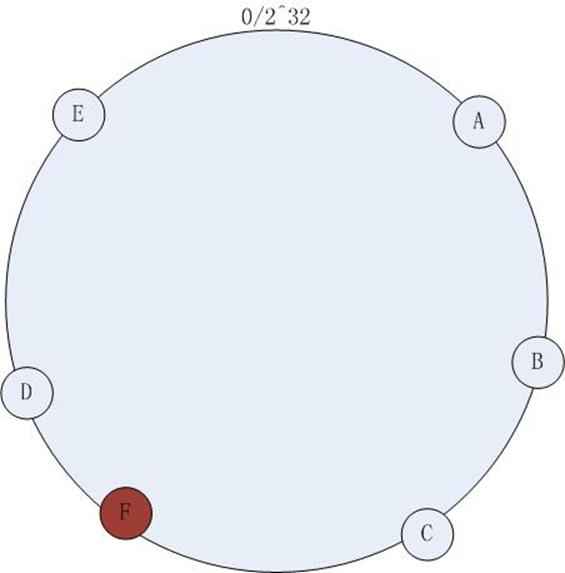
增加机器节点F之后,访问策略不改变,依然按照(2)中的方式访问,此时缓存命不中的情况依然不可避免,不能命中的数据是hash(K)在增加节点以前落在C~F之间的数据。尽管依然存在节点增加带来的命中问题,但是比较传统的 hash取模的方式,一致性hash已经将不命中的数据降到了最低。
Consistent Hashing最大限度地抑制了hash键的重新分布。另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上。因为使用一般的hash方法,服务器的映射地点的分布非常不均匀。使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
下面有一个图描述了需要为每台物理服务器增加的虚拟节点。
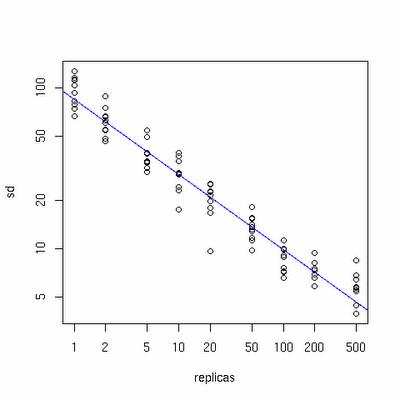
x轴表示的是需要为每台物理服务器扩展的虚拟节点倍数(scale),y轴是实际物理服务器数,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点才能达到真正的负载均衡。
以上是关于关于一致性hash算法的主要内容,如果未能解决你的问题,请参考以下文章