python 第二周(第十一天) 我的python成长记 一个月搞定python数据挖掘!(19) -scrapy + mongo
Posted yugengde
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 第二周(第十一天) 我的python成长记 一个月搞定python数据挖掘!(19) -scrapy + mongo相关的知识,希望对你有一定的参考价值。
mongoDB 3.2之后默认是使用wireTiger引擎
在启动时更改存储引擎:
mongod --storageEngine mmapv1 --dbpath d:\\data\\db
这样就可以解决mongvue不能查看文档的问题啦!
项目流程(步骤):
前去准备(安装scrapy pymongo mongodb )
1. 生成项目目录: scrapy startproject stack
2.itmes
from scrapy import Item,Field
class StackItem(Item):
title = Field()
url = Field()
3. 创建爬虫
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = response.xpath(\'//div[@class="summary"]/h3\')
for question in questions:
item = StackItem()
item[\'title\'] = question.xpath(
\'a[@class="question-hyperlink"]/text()\').extract()[0]
item[\'url\'] = question.xpath(
\'a[@class="question-hyperlink"]/@href\').extract()[0]
yield item
4.学会使用xpath selectors 进行数据的提取
5.存储数据到mongo中
5.1 setting.py
ITEM_PIPELINES = {
\'stack.pipelines.MongoDBPipeline\': 300,
}
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
5.2 pipelines.py
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings[\'MONGODB_SERVER\'],
settings[\'MONGODB_PORT\']
)
db = connection[settings[\'MONGODB_DB\']]
self.collection = db[settings[\'MONGODB_COLLECTION\']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
6. 启动爬虫 main.py
from scrapy import cmdline
cmdline.execute(\'scrapy crawl stack\'.split())
效果图
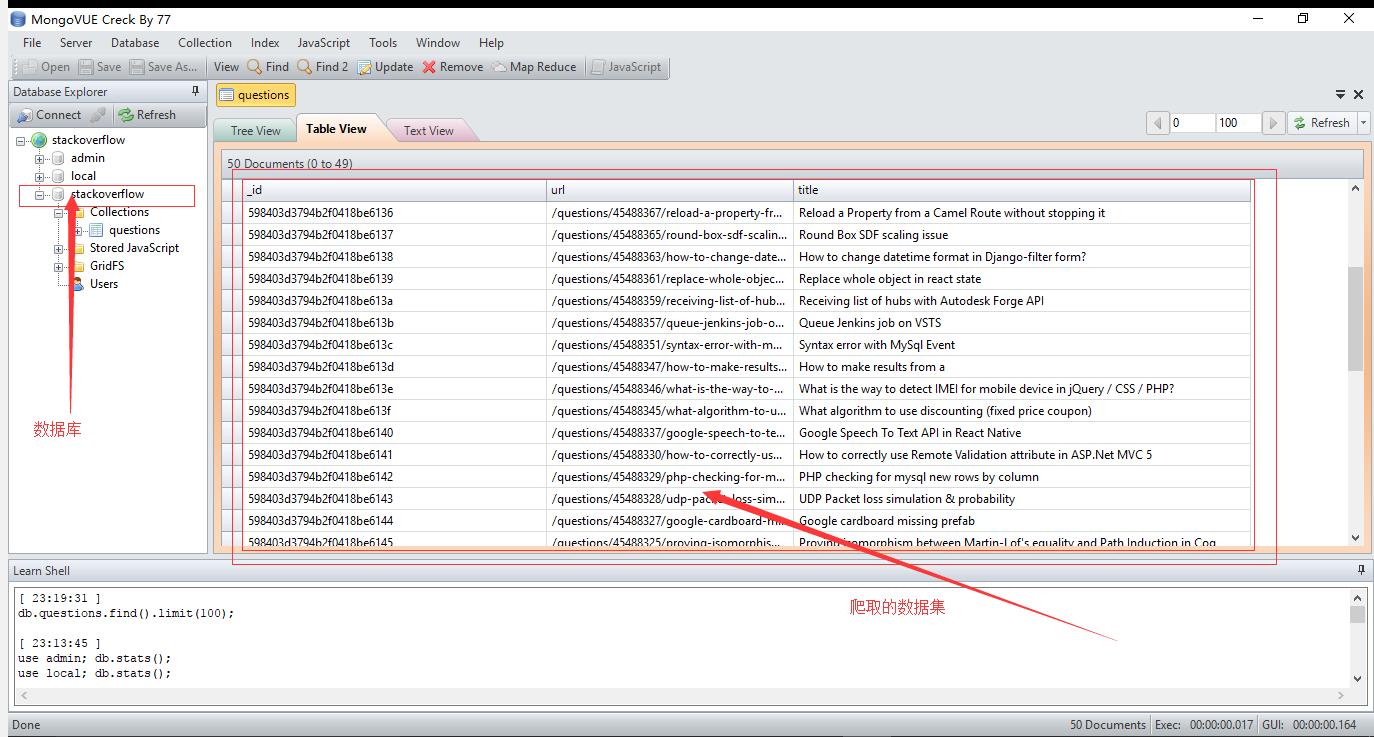
以上是关于python 第二周(第十一天) 我的python成长记 一个月搞定python数据挖掘!(19) -scrapy + mongo的主要内容,如果未能解决你的问题,请参考以下文章