大型网站架构系列:缓存在分布式系统中的应用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型网站架构系列:缓存在分布式系统中的应用相关的知识,希望对你有一定的参考价值。
本文是《缓存在分布式系统中的应用》第三篇文章。
上次主要给大家分享了,缓存在分布式系统中的应用,主要从不同的场景,介绍了CDN,反向代理,分布式缓存,本地缓存的常规架构和基本原理。
因为时间关于,原计划分享《缓存常见问题》的内容,没有讲。本次主要针对缓存的常见个问题,做一个介绍。主要有以下议题:
一、分享大纲
- 分享大纲
- 数据一致性
- 缓存高可用
- 缓存雪崩
- 缓存穿透
- 参考资料
- 分享总结
二、数据一致性
缓存是在数据持久化之前的一个节点,主要是将热点数据放到离用户最近或访问速度更快的介质中,加快数据的访问,减小响应时间。
因为缓存属于持久化数据的一个副本,因此不可避免的会出现数据不一致问题。导致脏读或读不到数据的情况。数据不一致,一般是因为网络不稳定或节点故障导致。根据数据的操作顺序,主要有以下几种情况。
2.1场景介绍
(1)先写缓存,再写数据库
如下图:
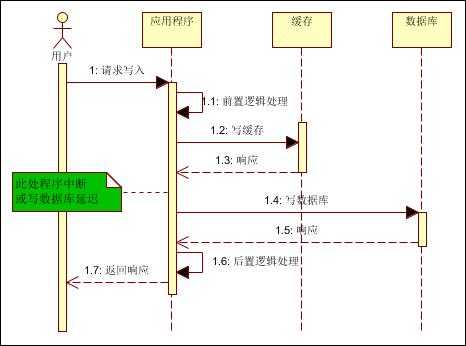
假如缓存写成功,但写数据库失败或响应延迟,则下次读取(并发读)缓存时,就出现脏读;
(2)先写数据库,再写缓存
如下图:
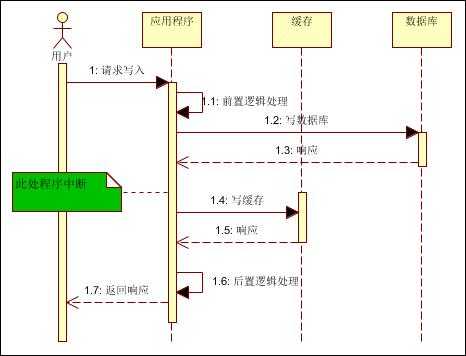
假如写数据库成功,但写缓存失败,则下次读取(并发读)缓存时,则读不到数据;
(3)缓存异步刷新
指数据库操作和写缓存不在一个操作步骤中,比如在分布式场景下,无法做到同时写缓存或需要异步刷新(补救措施)时候。
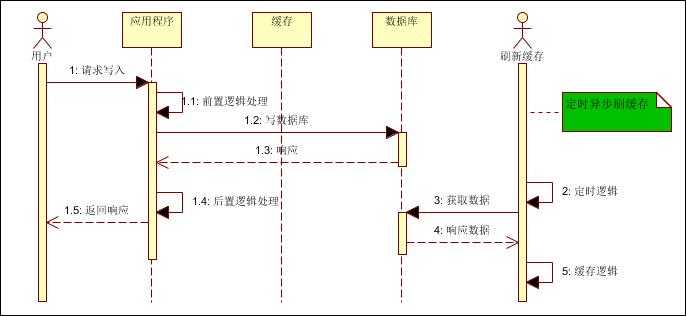
此种情况,主要考虑数据写入和缓存刷新的时效性。比如多久内刷新缓存,不影响用户对数据的访问。
2.2解决方法
第一个场景:
这个写缓存的方式,本身就是错误的,需要改为先写持久化介质,再写缓存的方式。
第二个场景:
(1)根据写入缓存的响应来进行判断,如果缓存写入失败,则回滚数据库操作;此种方法增加了程序的复杂度,不建议采用;
(2)缓存使用时,假如读缓存失败,先读数据库,再回写缓存的方式实现。
第三个场景:
(1)首先确定,哪些数据适合此类场景;
(2)根据经验值确定合理的数据不一致时间,用户数据刷新的时间间隔;
2.3 其他方法
(1)超时:设置合理的超时时间;
(2)刷新:定时刷新一定范围内(根据时间,版本号)的数据;
以上是简化数据读写场景,实际中会分为:
(1)缓存与数据库之间的一致性;
(2)多级缓存之前的一致性;
(3)缓存副本之前的一致性。
三、缓存高可用
业界有两种理论,第一套缓存就是缓存,临时存储数据的,不需要高可用。第二种缓存逐步演化为重要的存储介质,需要做高可用。
本人的看法是,缓存是否高可用,需要根据实际的场景而定。临界点是是否对后端的数据库造成影响。
具体的决策依据需要根据,集群的规模(数据,缓存),成本(服务器,运维),系统性能(并发量,吞吐量,响应时间)等方面综合评价。
3.1解决方法
缓存的高可用,一般通过分布式和复制实现。分布式实现数据的海量缓存,复制实现缓存数据节点的高可用。架构图如下:
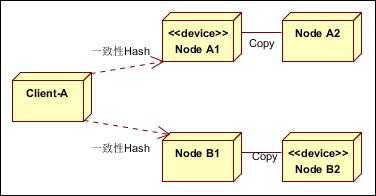
其中,分布式采用一致性Hash算法,复制采用异步复制。
3.2其他方法
(1)复制双写:缓存节点的复制,由异步改为双写,只有两份都写成功,才算成功。
(2)虚拟层:一致性Hash存在,假如其中一个HASH环不可用,数据会写入临近的环,当HASH可用时,数据又写入正常的HASH环,会导致数据偏移问题。这种情况,可以考虑在HASH环前面加一个虚拟层实现。
(3)多级缓存:比如一级使用本地缓存,二级采用分布式Cahce,三级采用分布式Cache+本地持久化;
方式很多,需要根据业务场景灵活选择。
四、缓存雪崩
雪崩是指当大量缓存失效时,导致大量的请求访问数据库,导致数据库服务器,无法抗住请求或挂掉的情况。
解决方法:
(1)合理规划缓存的失效时间;
(2)合理评估数据库的负载压力;
(3)对数据库进行过载保护或应用层限流;
(4)多级缓存设计,缓存高可用;
五、缓存穿透
缓存一般是Key,value方式存在,当某一个Key不存在时会查询数据库,假如这个Key,一直不存在,则会频繁的请求数据库,对数据库造成访问压力。
解决方法:
(1)对结果为空的数据也进行缓存,当此key有数据后,清理缓存;
(2)一定不存在的key,采用布隆过滤器,建立一个大的Bitmap中,查询时通过该bitmap过滤;
六、参考资料
以下是本次分享参考的资料和推荐大家参考的资料。
MemCache超详细解读:http://www.mamicode.com/info-detail-1120932.html
缓存与数据库一致性保证:http://www.36dsj.com/archives/43950
HASH环和虚拟节点:http://www.111cn.net/sys/linux/58748.htm
让memcached分布式:http://blog.csdn.net/cutesource/article/details/5848253
七、分享总结
以上是本周的分享,主要讲解了缓存常见的问题,包括数据一致性,缓存高可用,缓存雪崩,缓存穿透等知识。
我们的分享只是介绍一下知识结构,希望可以起到一个抛砖引玉的作用。因为,每个知识点都有一些细化的地方,需要学习的知识点很多,需要大家不断深入学习。也欢迎大家把好的内容,即时的分享到群内(知识链接或参加周知识分享,参加周知识分享的同学可以直接联系我哈~~)
参考:
http://www.cnblogs.com/itfly8/p/5597639.html
以上是关于大型网站架构系列:缓存在分布式系统中的应用的主要内容,如果未能解决你的问题,请参考以下文章