paddle学习词向量
Posted 合唱团abc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paddle学习词向量相关的知识,希望对你有一定的参考价值。
http://spaces.ac.cn/archives/4122/ 关于词向量讲的很好
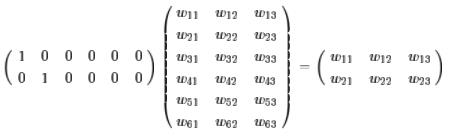
那么,字向量、词向量这些,真的没有任何创新了吗?有的,从运算上来看,基本上就是通过研究发现,one hot型的矩阵相乘,就像是相当于查表,于是它直接用查表作为操作(获取词向量),而不写成矩阵再运算,这大大降低了运算量。再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。这是运算层面的。思想层面的,就是它得到了这个全连接层的参数之后,直接用这个全连接层的参数作为特征,或者说,用这个全连接层的参数作为字、词的表示,从而得到了字、词向量,最后还发现了一些有趣的性质,比如向量的夹角余弦能够在某种程度上表示字、词的相似度。
如果把字向量当做全连接层的参数(这位读者,我得纠正,不是“当做”,它本来就是),那么这个参数你还没告诉我怎么得到呢!答案是:我也不知道怎么得来呀。神经网络的参数不是取决你的任务吗?你的任务应该问你自己呀,怎么问我来了?你说Word2Vec是无监督的?那我再来澄清一下。
这样看,问题就比较简单了,我也没必要一定要用语言模型来训练向量吧?对呀,你可以用其他任务,比如文本情感分类任务来有监督训练。因为都已经说了,就是一个全连接层而已,后面接什么,当然自己决定。当然,由于标签数据一般不会很多,因此这样容易过拟合,因此一般先用大规模语料无监督训练字、词向量,降低过拟合风险。注意,降低过拟合风险的原因是可以使用无标签语料预训练词向量出来(无标签语料可以很大,语料足够大就不会有过拟合风险),跟词向量无关,词向量就是一层待训练参数,有什么本事降低过拟合风险?
word2Vec数学原理:
给定n个权值作为n个叶子节点,构造一颗二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树
Huffman树的构造:

word2Vec用到Huffman编码,它把训练语料中的词当成叶子节点,其在语料中出现的次数当作权值,通过构造相应的Huffman树来对每一个词进行Huffman编码。在word2vec源码中将权值较大的孩子节点编码为1,较小的孩子节点编码为0
n-gram模型:

 n-gram模型认为一个词出现的概率只与它前面的n-1个词相关,在语料中统计各个词串出现的次数以及平滑处理,存储计算好的概率值,当需要计算一个句子的概率时,只需要找到相关的概率参数,连乘即可
n-gram模型认为一个词出现的概率只与它前面的n-1个词相关,在语料中统计各个词串出现的次数以及平滑处理,存储计算好的概率值,当需要计算一个句子的概率时,只需要找到相关的概率参数,连乘即可


 与n-gram相比,语言模型不需要实现计算并保存所有的概率值,而是通过直接计算来获取,且通过选取合适的模型可使得参数的个数远小于n-gram中模型参数的个数(语言模型和n-gram都是通过上下文预测当前词的概率)
与n-gram相比,语言模型不需要实现计算并保存所有的概率值,而是通过直接计算来获取,且通过选取合适的模型可使得参数的个数远小于n-gram中模型参数的个数(语言模型和n-gram都是通过上下文预测当前词的概率)
神经概率语言模型

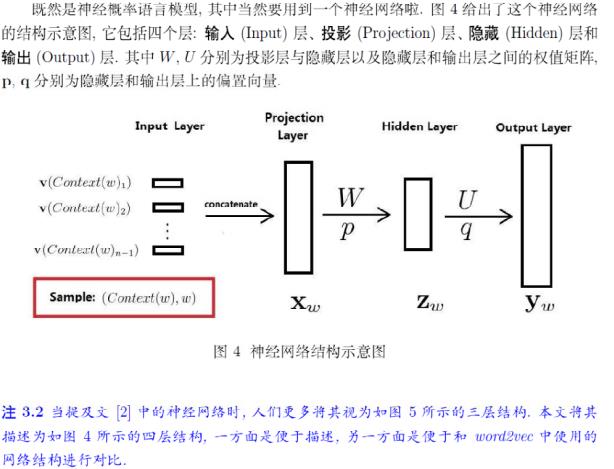


投影层向量:将输入层的n-1个词向量按顺序首尾相接地拼起来形成。隐藏层的激活函数是双曲正切函数。对隐藏层的输出做softmax归一化,即得概率。训练神经概率语言模型时,词向量只是一个副产品。投影层向量$X_w$, 作为隐层的输入,隐层的输出为$Z_w = tanh(WX_w + p)$, 在输出层得到$y_w = UZ_w + q$, 对$y_w$由softmax输出概率。神经概率语言模型的大部分计算集中在隐藏层和输出层的矩阵向量运算,以及输出层上的softmax归一化运算。优化主要是针对这一部分进行的。






CBOW模型
CBOW模型通过一个词的上下文(各N个词)预测当前词,结构:输入层,投影层,输出层。输出层对应一颗Huffman树,叶子节点为语料中出现过的词,各词在语料中出现的次数作为权值。
目标函数
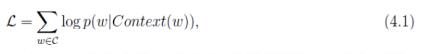
网络结构


神经概率语言模型与CBOW模型的区别:1、从输入层到投影层的操作,前者是通过拼接,后者通过累加求和; 2、前者有隐藏层,后者无隐藏层; 3、前者输出层是线性结构,后者是树形结构。

Hierarchical softmax思想
CBOW目标函数推导过程:对于词典中的任意词,Huffman树中存在一条从根节点到词对应叶节点的路径,路径上每个分支为一次二分类,每一次分类产生一个概率,这些概率连乘起来,即得到目标函数(关于投影向量$X_w$和所有sigmoid函数的未知参数的函数),$p(w|Context(w)) = \\prod_{j = 2}^{l^w}p(d_j^w|X_w, \\theta^w_{j - 1})$ .推导出来的梯度是目标函数关于投影层上向量(输入上下文中各词向量的和)的梯度,直接利用该梯度来迭代求解输入的各词向量。

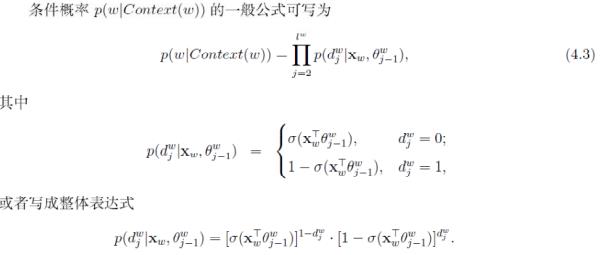



skip-gram模型
Skip-gram的方法中,用一个词预测其上下文。
目标函数
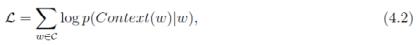
网络结构:输入层只含当前样本的中心词的词向量,所以投影是恒等投影,没有存在的必要,其余和CBOW模型相同




若干源码细节



由于某些高频词提供的有用信息很少,给定一个词频阈值,词w将以某个概率被舍弃


对于一个给定的行,设它包含T个词,则可以得到T个训练样本,因为每个词都对应一个样本,CBOW投影时,词向量直接相加求和,如果是首尾相连,则可能需要补充填充向量,因为一行中首、尾的词,可能其前后的词数不足

逻辑回归中的参数向量是零初始化,词典中每个词的词向量是随机初始化

结合Word2vec数学原理一起看 http://kexue.fm/archives/4299/
http://kexue.fm/usr/uploads/2017/04/2833204610.pdf
https://www.zhihu.com/question/44832436
基于Word2vec的语义分析:
https://zhuanlan.zhihu.com/p/21457407
如何吹比:
https://www.nowcoder.com/discuss/36851?type=0&order=0&pos=13&page=1
作者:haolexiao
链接:https://www.nowcoder.com/discuss/36851?type=0&order=0&pos=13&page=1
来源:牛客网
Hierarchical Softmax的缺点:如果我们的训练样本里的中心词w是一个很生僻的词,那么该词对应的叶子节点深度很大,模型比较复杂。
负采样:比如我们有一个训练样本,中心词是w,它周围上下文共有
2c个词,记为
context(w)。由于这个中心词
w,的确和
context(w)相关存在,因此它是一个真实的正例。通过Negative Sampling采样,我们得到neg个和
w不同的中心词
wi,i=1,2,..neg,这样
context(w)和$w_i$就组成了neg个并不真实存在的负例。利用这一个正例和neg个负例,我们进行二元逻辑回归,得到负采样对应每个词$w_i$对应的模型参数$\\theta_{i}$,和每个词的词向量。
问题:1)如何通过一个正例和neg个负例进行二元逻辑回归呢? 2)如何进行负采样呢?
在逻辑回归中,我们的正例应该期望满足:
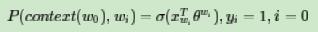 左式x的下标应该是i
左式x的下标应该是i
我们的负例期望满足:
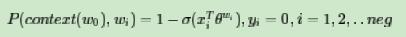
我们期望可以最大化下式:
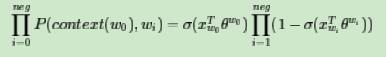
此时模型的似然函数为:
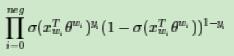 左式上标为$y_i$和$1-y_i$
左式上标为$y_i$和$1-y_i$
对应的对数似然函数为:
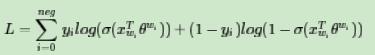
负采样方法:
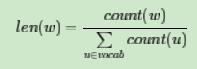
在word2vec中,分子和分母都取了3/4次幂如下:
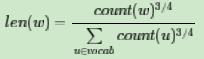
如何对sentence和phrase生成向量表示? 最直观的思路,对于phrase和sentence,我们将组成它们的所有word对应的词向量加起来,作为短语向量,句向量。在参考文献[34]中,验证了将词向量加起来的确是一个有效的方法,但事实上还有更好的做法。
Le和Mikolov在文章《Distributed Representations of Sentences and Documents》[20]里介绍了sentence vector,这里我们也做下简要分析。
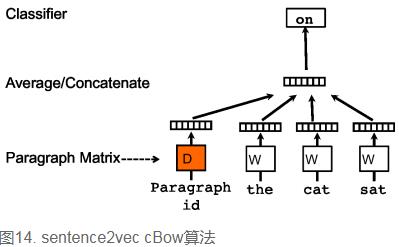
先看c-bow方法,相比于word2vec的c-bow模型,区别点有:
- 训练过程中新增了paragraph id,即训练语料中每个句子都有一个唯一的id。paragraph id和普通的word一样,也是先映射成一个向量,即paragraph vector。paragraph vector与word vector的维数虽一样,但是来自于两个不同的向量空间。在之后的计算里,paragraph vector和word vector累加或者连接起来,作为输出层softmax的输入。在一个句子或者文档的训练过程中,paragraph id保持不变,共享着同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。
- 在预测阶段,给待预测的句子新分配一个paragraph id,词向量和输出层softmax的参数保持训练阶段得到的参数不变,重新利用梯度下降训练待预测的句子。待收敛后,即得到待预测句子的paragraph vector。
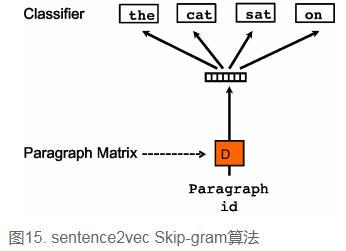
sentence2vec相比于word2vec的skip-gram模型,区别点为:在sentence2vec里,输入都是paragraph vector,输出是该paragraph中随机抽样的词。
词向量的改进
- 学习词向量的方法主要分为:Global matrix factorization和Shallow Window-Based。Global matrix factorization方法主要利用了全局词共现,例如LSA;Shallow Window-Based方法则主要基于local context window,即局部词共现,word2vec是其中的代表;Jeffrey Pennington在word2vec之后提出了GloVe,它声称结合了上述两种方法,提升了词向量的学习效果。它与word2vec的更多对比请点击GloVe vs word2vec,GloVe & word2vec评测。
- 目前通过词向量可以充分发掘出“一义多词”的情况,譬如“快递”与“速递”;但对于“一词多义”,束手无策,譬如“苹果”(既可以表示苹果手机、电脑,又可以表示水果),此时我们需要用多个词向量来表示多义词。
http://www.flickering.cn/ads/2015/02/%E8%AF%AD%E4%B9%89%E5%88%86%E6%9E%90%E7%9A%84%E4%B8%80%E4%BA%9B%E6%96%B9%E6%B3%95%E4%BA%8C/
以上是关于paddle学习词向量的主要内容,如果未能解决你的问题,请参考以下文章
NLP⚠️学不会打我! 半小时学会基本操作 4⚠️词向量模型
NLP⚠️学不会打我! 半小时学会基本操作 4⚠️词向量模型