用Word2Vec词向量化的数据训练Seq2Seq翻译模型的问题?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Word2Vec词向量化的数据训练Seq2Seq翻译模型的问题?相关的知识,希望对你有一定的参考价值。
Word2Vec用有限的空间来表示不同的词,生成的词向量的每个维度的数值都是小数。训练seq2seq翻译模型时可以正常的用模型输出与目标词向量进行匹配计算损失,训练过程也是尽可能地让输出向量的各个维度的值与实际值接近,但应该不会完全等于吧。那么问题来了,在预测时,输出的词向量的各维度值跟实际能表达文字的词向量是有误差的吧?那是怎么将输出的向量转化成文字呢?我看了一些开源的源码,他们直接用输出向量做K去词典里面找V??!我觉得除非在输出层前用softmax才能输出标签唯一,但这么处理后的词不就是用最原始的方法做one-hot、效率会很低吗?那用word2vec的意义何在呢?希望有NLP的大牛能帮忙解读一下,感谢!!!
参考技术A LED驱动要用恒流电源,不是一般的稳压电源。 参考技术B 面先用word2vec+seq2seq尝试一下,基于机器学习的对话系统。如题,整个程序主要又两部分组成,word2vec将训练语料首先做词向量化,然后,用向量输入到seq2seq中训练。实际上tensorflow本身已经有一个完整的seq2seq模型,可以直接拿来训练,且tf自带基于OneFlow实现量化感知训练

本文介绍了量化感知训练的原理,基于OneFlow实现了一个量化感知训练Demo,并介绍了在具体实现中的各种细节。
1
后量化以及量化感知训练原理
这里说的量化一般都是指的Google TFLite的量化方案,对应的是Google 的论文 Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference。虽然TfLite这套量化方案并不是很难,但在实际处理的时候细节还是比较多,一时是很难说清楚的。
所以,这里推荐一系列讲解TFLite后量化和量化感知训练原理的文章,看一下这几篇文章阅读本文就没有任何问题了。
这里简单总结一下,无论是TFLite的量化方案还是TensorRT的后量化方案,他们都会基于原始数据和量化数据的数值范围算出一个缩放系数scale和零点zero_point,这个zero_point有可能是0(对应对称量化),也有可能不是0(对应非对称量化)。然后原始数据缩放之后减掉零点就获得了量化后的数据。这里的关键就在于缩放系数scale和zero_point怎么求,Google的TFLite使用下面的公式:
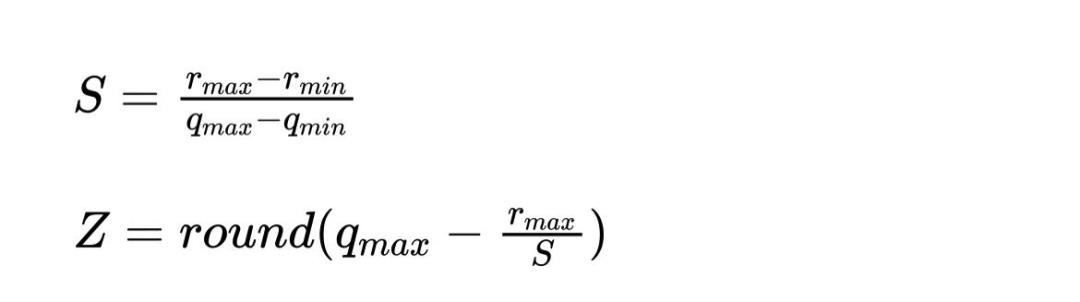
其中,
表示浮点实数,
表示量化后的定点整数,
和
分别是
的最大值和最小值,
和
表示
的最大值和最小值,如果是有符号8比特量化,那么
,
,如果是无符号那么
,
。
就代表scale,
就代表zero_point。
要求取scale和zero_point关键就是要精确地估计原始浮点实数的最大值和最小值,有了原始浮点实数的最大值和最小值就可以代入上面的公式求出scale和zero_point了。所以后训练量化以及量化感知训练的目的是要记录各个激活特征图和权重参数的scale和zero_point。
在后训练量化中,做法一般是使用一部分验证集来对网络做推理,在推理的过程中记录激活特征图以及权重参数的最大和最小值,进而计算scale和zero_point。而量化感知训练则在训练的过程中记录激活特征图和权重参数的最大和最小值来求取scale和zero_point。
量化感知训练和后训练量化的主要区别在于它会对激活以及权重做模拟量化操作,即FP32->INT8->FP32。这样做的好处是可以模拟量化的实际运行过程,将量化过程中产生的误差也作为一个特征提供给网络学习,一般来说量化感知训练会获得比后训练量化更好的精度。
2
组件
在上一节中主要提到了记录激活和权重的scale和zero_point,以及模拟量化,量化这些操作。这对应着三个量化训练中用到的三个基本组件,即MinMaxObserver,FakeQuantization,Quantization。下面我们分别看一下在OneFlow中这三个组件的实现。
组件1. MinMaxObserver

从这个文档我们可以看到MinMaxObserver操作被封装成oneflow.nn.MinMaxObserver这个Module(Module在Pytorch中对应torch.nn.Module,然后OneFlow的接口也在靠近Pytorch,也对应有oneflow.nn.Module,因此这里将其封装为oneflow.nn.Module)。这个Module的参数有:
quantization_bit表示量化Bit数quantization_scheme表示量化的方式,有对称量化symmetric和非对称量化affine两种,区别就是对称量化浮点0和量化空间中的0一致quantization_formula表示量化的方案,有Google和Cambricon两种,Cambricon是中科寒武纪的意思per_layer_quantization表示对当前的输入Tensor是PerChannel还是PerLayer量化,如果是PerLayer量化设置为True。一般激活特征图的量化都是PerLayer,而权重的量化可以选择PerLayer或者PerChannel。
下面看一下在Python层的用法:
>>> import numpy as np
>>> import oneflow as flow
>>> weight = (np.random.random((2, 3, 4, 5)) - 0.5).astype(np.float32)
>>> input_tensor = flow.Tensor(
... weight, dtype=flow.float32
... )
>>> quantization_bit = 8
>>> quantization_scheme = "symmetric"
>>> quantization_formula = "google"
>>> per_layer_quantization = True
>>> min_max_observer = flow.nn.MinMaxObserver(quantization_formula=quantization_formula, quantization_bit=quantization_bit,
... quantization_scheme=quantization_scheme, per_layer_quantization=per_layer_quantization)
>>> scale, zero_point = min_max_observer(
... input_tensor, )
在设定好相关量化配置参数后,传入给定Tensor即可统计和计算出该设置下的Tensor的scale和zero_point。
上面讲的是Python前端的接口和用法,下面看一下在OneFlow中这个Module的具体实现,我们以CPU版本为例(GPU和CPU的Kernel实现是一致的),文件在oneflow/user/kernels/min_max_observer_kernel.cpp,核心实现是如下三个函数:
// TFLite量化方案,对称量化
template<typename T>
void GenQuantScaleSymmetric(const T* in_ptr, const int32_t quantization_bit,
const int64_t num_elements, T* scale, T* zero_point) {
T in_max = *std::max_element(in_ptr, in_ptr + num_elements);
T in_min = *std::min_element(in_ptr, in_ptr + num_elements);
in_max = std::max(std::abs(in_max), std::abs(in_min));
T denominator = static_cast<T>(pow(2.0, quantization_bit - 1)) - 1;
*scale = in_max / denominator;
*zero_point = 0;
}
// TFLite量化方案,非对称量化
template<typename T>
void GenQuantScaleAffine(const T* in_ptr, const int32_t quantization_bit,
const int64_t num_elements, T* scale, T* zero_point) {
T in_max = *std::max_element(in_ptr, in_ptr + num_elements);
T in_min = *std::min_element(in_ptr, in_ptr + num_elements);
T denominator = static_cast<T>(pow(2.0, quantization_bit)) - 1;
*scale = (in_max - in_min) / denominator;
*zero_point = -std::nearbyint(in_min / (*scale));
}
//寒武纪量化方案
template<typename T>
void GenQuantScaleCambricon(const T* in_ptr, const int32_t quantization_bit,
const int64_t num_elements, T* scale, T* zero_point) {
T in_max = *std::max_element(in_ptr, in_ptr + num_elements);
T in_min = *std::min_element(in_ptr, in_ptr + num_elements);
in_max = std::max(std::abs(in_max), std::abs(in_min));
*scale = std::floor(std::log2(in_max)) - (quantization_bit - 2);
*zero_point = 0;
}
除了这三个函数之外,另外一个关键点就是对per_layer_quantization参数的处理了,逻辑如下:
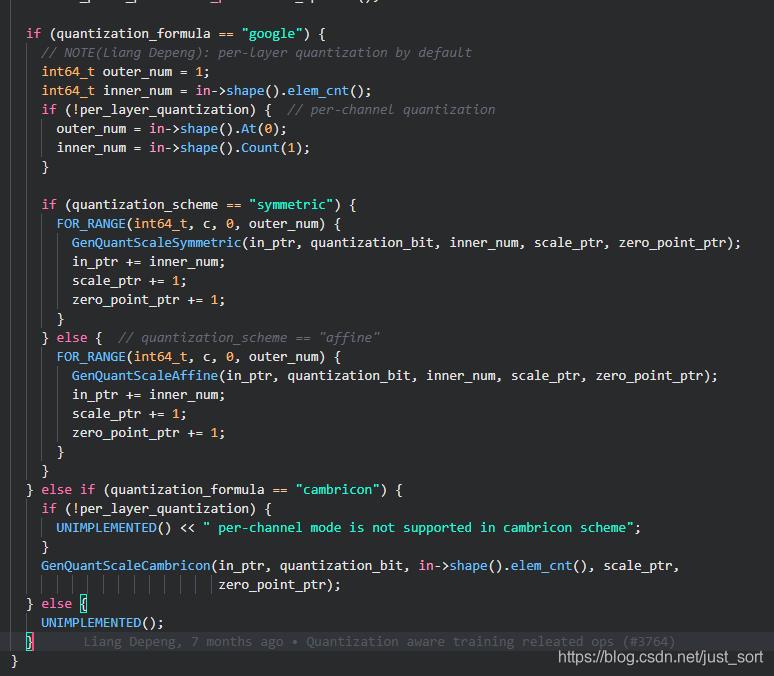
如果是PerChannel量化则对每个输出通道求一个scale和zero_point。想了解更多PerLayer量化以及PerChannel量化的知识可以看这篇文章:神经网络量化--per-channel量化 。
组件2:FakeQuantization

同样,FakeQuantization也被封装为一个oneflow.nn.Module。在上一节提到,量化感知训练和后训练量化的主要区别在于它会对激活以及权重参数做模拟量化操作,即FP32->INT8->FP32。通过这种模拟将量化过程中产生的误差也作为一个特征提供给网络学习,以期在实际量化部署时获得更好的准确率。这个接口有以下参数:
scale:由MinMaxObserver组件算出来的量化scalezero_point:由MinMaxObserver组件算出来的量化zero_pointquantization_bit:量化比特数quantization_scheme表示量化的方式,有对称量化symmetric和非对称量化affine两种,区别就是对称量化浮点0和量化空间中的0一致quantization_formula表示量化的方案,有Google和Cambricon两种,Cambricon是中科寒武纪的意思
Python层的示例用法如下:
>>> import numpy as np
>>> import oneflow as flow
>>> weight = (np.random.random((2, 3, 4, 5)) - 0.5).astype(np.float32)
>>> input_tensor = flow.Tensor(
... weight, dtype=flow.float32
... )
>>> quantization_bit = 8
>>> quantization_scheme = "symmetric"
>>> quantization_formula = "google"
>>> per_layer_quantization = True
>>> min_max_observer = flow.nn.MinMaxObserver(quantization_formula=quantization_formula, quantization_bit=quantization_bit,
... quantization_scheme=quantization_scheme, per_layer_quantization=per_layer_quantization)
>>> fake_quantization = flow.nn.FakeQuantization(quantization_formula=quantization_formula, quantization_bit=quantization_bit,
... quantization_scheme=quantization_scheme)
>>> scale, zero_point = min_max_observer(
... input_tensor,
... )
>>> output_tensor = fake_quantization(
... input_tensor,
... scale,
... zero_point,
... )
在执行FakeQuantizaton必须知道输入Tensor的scale和zero_point,这是由上面的MinMaxObserver组件获得的。
接下来看一下FakeQuantization组件C++层的实现,仍然有三个核心函数:
// TFLite量化方案,对称量化
template<typename T>
void FakeQuantizationPerLayerSymmetric(const T* in_ptr, const T scale,
const int32_t quantization_bit, const int64_t num_elements,
T* out_ptr) {
T upper_bound = static_cast<T>(pow(2.0, quantization_bit - 1)) - 1;
T lower_bound = -upper_bound - 1;
FOR_RANGE(int64_t, i, 0, num_elements) {
T out = std::nearbyint(in_ptr[i] / scale);
out = out > upper_bound ? upper_bound : out;
out = out < lower_bound ? lower_bound : out;
out_ptr[i] = out * scale;
}
}
// TFLite量化方案,非对称量化
template<typename T>
void FakeQuantizationPerLayerAffine(const T* in_ptr, const T scale, const T zero_point,
const int32_t quantization_bit, const int64_t num_elements,
T* out_ptr) {
T upper_bound = static_cast<T>(pow(2.0, quantization_bit)) - 1;
T lower_bound = 0;
uint8_t zero_point_uint8 = static_cast<uint8_t>(std::round(zero_point));
FOR_RANGE(int64_t, i, 0, num_elements) {
T out = std::nearbyint(in_ptr[i] / scale + zero_point_uint8);
out = out > upper_bound ? upper_bound : out;
out = out < lower_bound ? lower_bound : out;
out_ptr[i] = (out - zero_point_uint8) * scale;
}
}
// 寒武纪量化方案
template<typename T>
void FakeQuantizationPerLayerCambricon(const T* in_ptr, const T shift,
const int32_t quantization_bit, const int64_t num_elements,
T* out_ptr) {
T upper_bound = static_cast<T>(pow(2.0, quantization_bit - 1)) - 1;
T lower_bound = -upper_bound - 1;
T scale = static_cast<T>(pow(2.0, static_cast<int32_t>(shift)));
FOR_RANGE(int64_t, i, 0, num_elements) {
T out = std::nearbyint(in_ptr[i] / scale);
out = out > upper_bound ? upper_bound : out;
out = out < lower_bound ? lower_bound : out;
out_ptr[i] = out * scale;
}
}
需要注意的一点是由于FakeQuantization要参与训练,所以我们要考虑梯度怎么计算?从上面的三个核心函数实现中我们可以发现里面都用了std::nearbyint函数,这个函数其实就对应numpy的round操作。而我们知道round函数中几乎每一处梯度都是0,所以如果网络中存在这个函数,反向传播的梯度也会变成0。
因此为了解决这个问题,引入了Straight Through Estimator。即直接把卷积层(这里以卷积层为例子,还包含全连接层等需要量化训练的层)的梯度回传到伪量化之前的weight上。这样一来,由于卷积中用的weight是经过伪量化操作的,因此可以模拟量化误差,把这些误差的梯度回传到原来的 weight,又可以更新权重,使其适应量化产生的误差,量化训练也可以正常运行。
具体的实现就非常简单了,直接将dy赋值给dx,在OneFlow中通过identity这个Op即可:
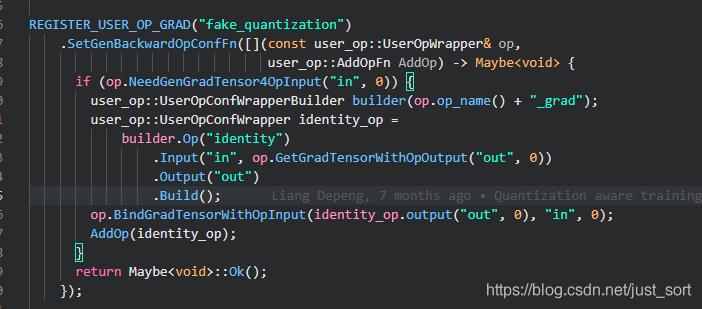
组件三:Quantization
上面的FakeQuantization实现了FP32->INT8->FP32的过程,这里还实现了一个Quantization组件备用。它和FakeQuantization的区别在于它没有INT8->FP32这个过程,直接输出定点的结果。所以这个组件的接口和C++代码实现和FakeQuantization基本完全一样(反向就不需要了),这里不再赘述。之所以要独立这个组件是为了在训练完模型之后可以将神经网络的权重直接以定点的方式存储下来。后面的Demo中将体现这一点。
3
基于OneFlow量化感知训练AlexNet
下面以AlexNet为例,基于OneFlow的三个量化组件完成一个量化感知训练Demo。这里先贴一下实验结果:
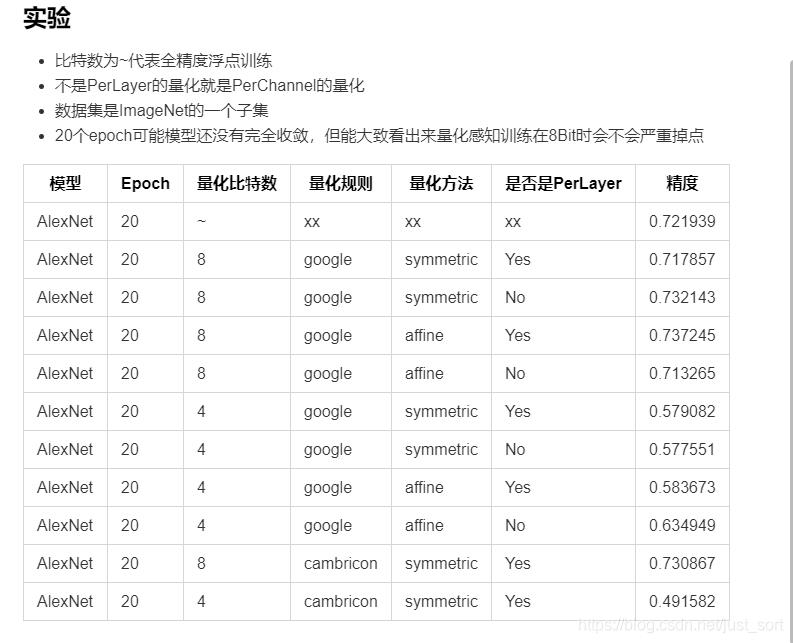
训练的数据集是ImageNet的一个子集,详细信息可以https://github.com/Oneflow-Inc/models/pull/78看到。在8Bit的时候无论是选用Google还是寒武纪,对称还是非对称,PerLayer还是PerChannel,量化感知训练后的模型精度没有明显降低。一旦将量化Bit数从8降到4,在相同的超参配置下精度有了明显下降。
下面分享一下这个基于OneFlow的量化感知训练Demo的做法:
首先代码结构如下:
- quantization
- quantization_ops 伪量化OP实现
- q_module.py 实现了Qparam类来管理伪量化参数和操作和QModule基类管理伪量化OP的实现
- conv.py 继承QModule基类,实现卷积的伪量化实现
- linear.py 继承QModule基类,实现全连接层的伪量化实现
- ...
- models 量化模型实现
- q_alexnet.py 量化版AlexNet模型
- quantization_aware_training.py 量化训练实现
- quantization_infer.py 量化预测实现
- train.sh 量化训练脚本
- infer.sh 量化预测脚本
由于量化训练时需要先统计样本以及中间层的
scale、zeropoint,同时也频繁涉及到一些量化、反量化操作,所以实现一个QParam基类封装这些功能。实现了一个量化基类
QModule,提供了三个成员函数__init__,freeze。
后量化公式,定点计算 __init__函数除了需要i指定quantization_bit,quantization_scheme,quantization_formula,per_layer_quantization参数外,还需要指定是否提供量化输入参数(qi) 及输出参数 (qo)。这是因为不是每一个网络模块都需要统计输入的scale,zero_point,大部分中间层都是用上一层的qo来作为自己的qi,另外有些中间层的激活函数也是直接用上一层的qi来作为自己的qi和qo。freeze这个函数会在统计完scale,zero_point后发挥作用,这个函数和后训练量化和模型转换有关。如下面的量化公式所示,其中很多项是可以提前计算好的,freeze就是把这些项提前固定下来,同时也将网络的权重由浮点实数转化为定点整数。
基于这个
QModule基类定义QConv2d,QReLU,QConvBN等等。
QConvBN表示Conv和BN融合后再模拟量化。原理可以看第一节的第4篇参考资料。这里以QConv2d为例看看它的实现:
import oneflow as flow
from quantization_ops.q_module import QModule, QParam
__all__ = ["QConv2d"]
class QConv2d(QModule):
def __init__(self, conv_module, qi=True, qo=True, quantization_bit=8, quantization_scheme='symmetric', quantization_formula='google', per_layer_quantization=True):
super(QConv2d, self).__init__(qi=qi, qo=qo, quantization_bit=quantization_bit, quantization_scheme=quantization_scheme,
quantization_formula=quantization_formula, per_layer_quantization=per_layer_quantization)
self.quantization_bit = quantization_bit
self.quantization_scheme = quantization_scheme
self.quantization_formula = quantization_formula
self.per_layer_quantization = per_layer_quantization
self.conv_module = conv_module
self.fake_quantization = flow.nn.FakeQuantization(
quantization_formula=quantization_formula, quantization_bit=quantization_bit, quantization_scheme=quantization_scheme)
self.qw = QParam(quantization_bit=quantization_bit, quantization_scheme=quantization_scheme,
quantization_formula=quantization_formula, per_layer_quantization=per_layer_quantization)
self.quantization = flow.nn.Quantization(
quantization_bit=32, quantization_scheme="affine", quantization_formula="google")
def forward(self, x):
if hasattr(self, 'qi'):
self.qi.update(x)
x = self.qi.fake_quantize_tensor(x)
self.qw.update(self.conv_module.weight)
x = flow.F.conv2d(x, self.qw.fake_quantize_tensor(self.conv_module.weight), self.conv_module.bias,
stride=self.conv_module.stride,
padding=self.conv_module.padding, dilation=self.conv_module.dilation,
groups=self.conv_module.groups)
if hasattr(self, 'qo'):
self.qo.update(x)
x = self.qo.fake_quantize_tensor(x)
return x
def freeze(self, qi=None, qo=None):
if hasattr(self, 'qi') and qi is not None:
raise ValueError('qi has been provided in init function.')
if not hasattr(self, 'qi') and qi is None:
raise ValueError('qi is not existed, should be provided.')
if hasattr(self, 'qo') and qo is not None:
raise ValueError('qo has been provided in init function.')
if not hasattr(self, 'qo') and qo is None:
raise ValueError('qo is not existed, should be provided.')
if qi is not None:
self.qi = qi
if qo is not None:
self.qo = qo
self.M = self.qw.scale.numpy() * self.qi.scale.numpy() / self.qo.scale.numpy()
self.conv_module.weight = flow.nn.Parameter(
self.qw.quantize_tensor(self.conv_module.weight) - self.qw.zero_point)
self.conv_module.bias = flow.nn.Parameter(self.quantization(
self.conv_module.bias, self.qi.scale * self.qw.scale, flow.Tensor([0])))
在QConv2d的__init__.py中,conv_module是原始的FP32的卷积module,其它的参数都是量化配置参数需要在定义模型的时候指定,forward函数模拟了FakeQuantization的过程,freeze函数则实现了冻结权重参数为定点的功能。其它的量化Module实现类似。
基于这些Module,我们可以定义AlexNet的量化版模型结构https://github.com/Oneflow-Inc/models/blob/add_quantization_model/quantization/models/q_alexnet.py ,完成量化感知训练以及模型参数定点固化等。
想完成完整的训练和测试可以直接访问:https://github.com/Oneflow-Inc/models 仓库。
4
注意,上面的实现只是Demo级别的
查看了上面的具体实现之后,我们会发现最拉胯的问题是在量化模型的时候需要你手动去调整模型结构。其实不仅OneFlow的这个Demo是这样,在Pytorch1.8.0推出FX的量化方案之前(这里叫第一代量化方案吧)的第一代量化方案也是这样。这里放一段调研报告。
Pytorch第一代量化叫作Eager Mode Quantization,然后从1.8开始推出FX Graph Mode Quantization。Eager Mode Quantization需要用户手动更改模型,并手动指定需要融合的Op。FX Graph Mode Quantization解放了用户,一键自动量化,无需用户修改模型和关心内部操作。这个改动具体可以体现在下面的图中。

下面以一段代码为例解释一下Pytorch这两种量化方式的区别。
Eager Mode Quantization
class Net(nn.Module):
def __init__(self, num_channels=1):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.fc = nn.Linear(5*5*40, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.reshape(-1, 5*5*40)
x = self.fc(x)
return x
Pytorch可以在Module的foward里面随意构造网络,可以调用Module,也可以调用Functional,甚至可以在里面写If这种控制逻辑。但这也带来了一个问题,就是比较难获取这个模型的图结构。因为在Eager Mode Quantization中,要量化这个网络必须做手动修改:
class NetQuant(nn.Module):
def __init__(self, num_channels=1):
super(NetQuant, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(5*5*40, 10)
self.quant = torch.quantization.QuantStub()
以上是关于用Word2Vec词向量化的数据训练Seq2Seq翻译模型的问题?的主要内容,如果未能解决你的问题,请参考以下文章