决策树原理及实现
Posted debuggor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树原理及实现相关的知识,希望对你有一定的参考价值。
1、决策树原理
1.1、定义
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类。
举一个通俗的栗子,各位立志于脱单的单身男女在找对象的时候就已经完完全全使用了决策树的思想。假设一位母亲在给女儿介绍对象时,有这么一段对话:
母亲:给你介绍个对象。 女儿:年纪多大了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。
这个女生的决策过程就是典型的分类决策树。相当于对年龄、外貌、收入和是否公务员等特征将男人分为两个类别:见或者不见。假设这个女生的决策逻辑如下: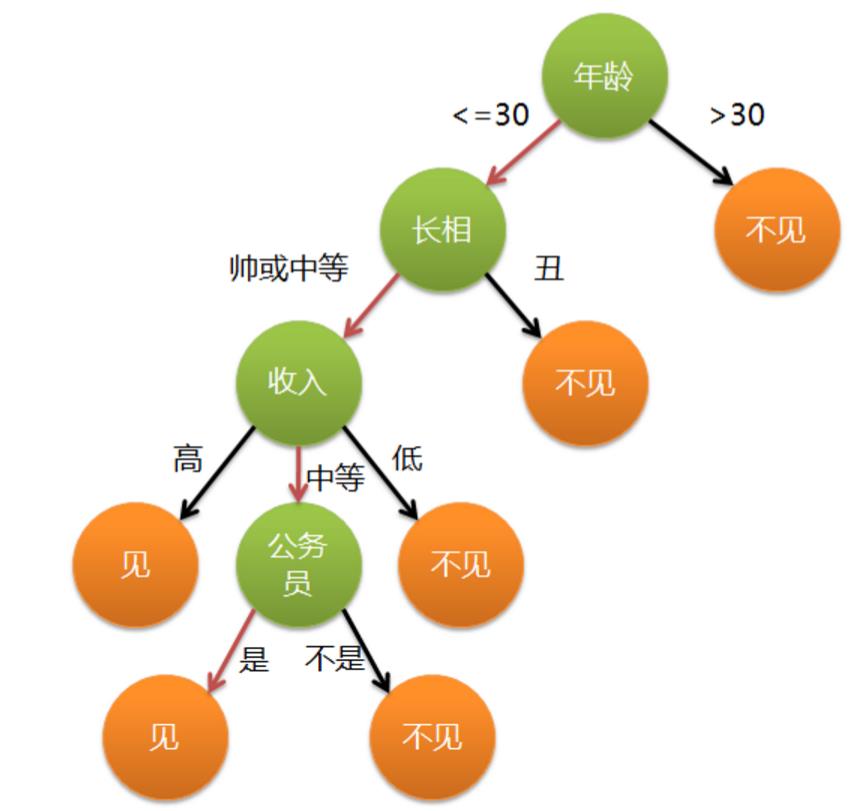
每种决策树之所以不同,一般是由于最有特征的选择上有所差异,不同决策导致不同的决策树。
基于信息论的决策树算法有ID3、CART和C4.5等算法,其中C4.5和CART两种算法从ID3算法中衍生而来。
ID3 最有特征选择标准是信息增益 ; C4.5 信息增益率 ; CART 节点方差的大小
1.2、ID3算法的数学原理
关于决策树的信息论基础可以参考“决策树1-建模过程”
(1)信息熵
信息熵:在概率论中,信息熵给了我们一种度量不确定性的方式,是用来衡量随机变量不确定性的,熵就是信息的期望值。若待分类的事物可能划分在N类中,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
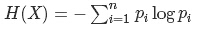 ,从定义中可知:0≤H(X)≤log(n)
,从定义中可知:0≤H(X)≤log(n)
当随机变量只取两个值时,即X的分布为 P(X=1)=p,X(X=0)=1−p,0≤p≤1则熵为:H(X)=−plog2(p)−(1−p)log2(1−p)。
熵值越高,则数据混合的种类越高,其蕴含的含义是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大。熵在信息论中是一个非常重要的概念,很多机器学习的算法都会利用到这个概念。
(2)条件熵
假设有随机变量(X,Y),其联合概率分布为:P(X=xi,Y=yi)=pij,i=1,2,⋯,n;j=1,2,⋯,m
则条件熵(H(Y∣X))表示在已知随机变量X的条件下随机变量Y的不确定性,其定义为X在给定条件下Y的条件概率分布的熵对X的数学期望:
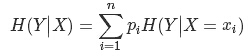
(3)信息增益
信息增益(information gain)表示得知特征X的信息后,而使得Y的不确定性减少的程度。定义为:
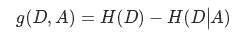
应用举例


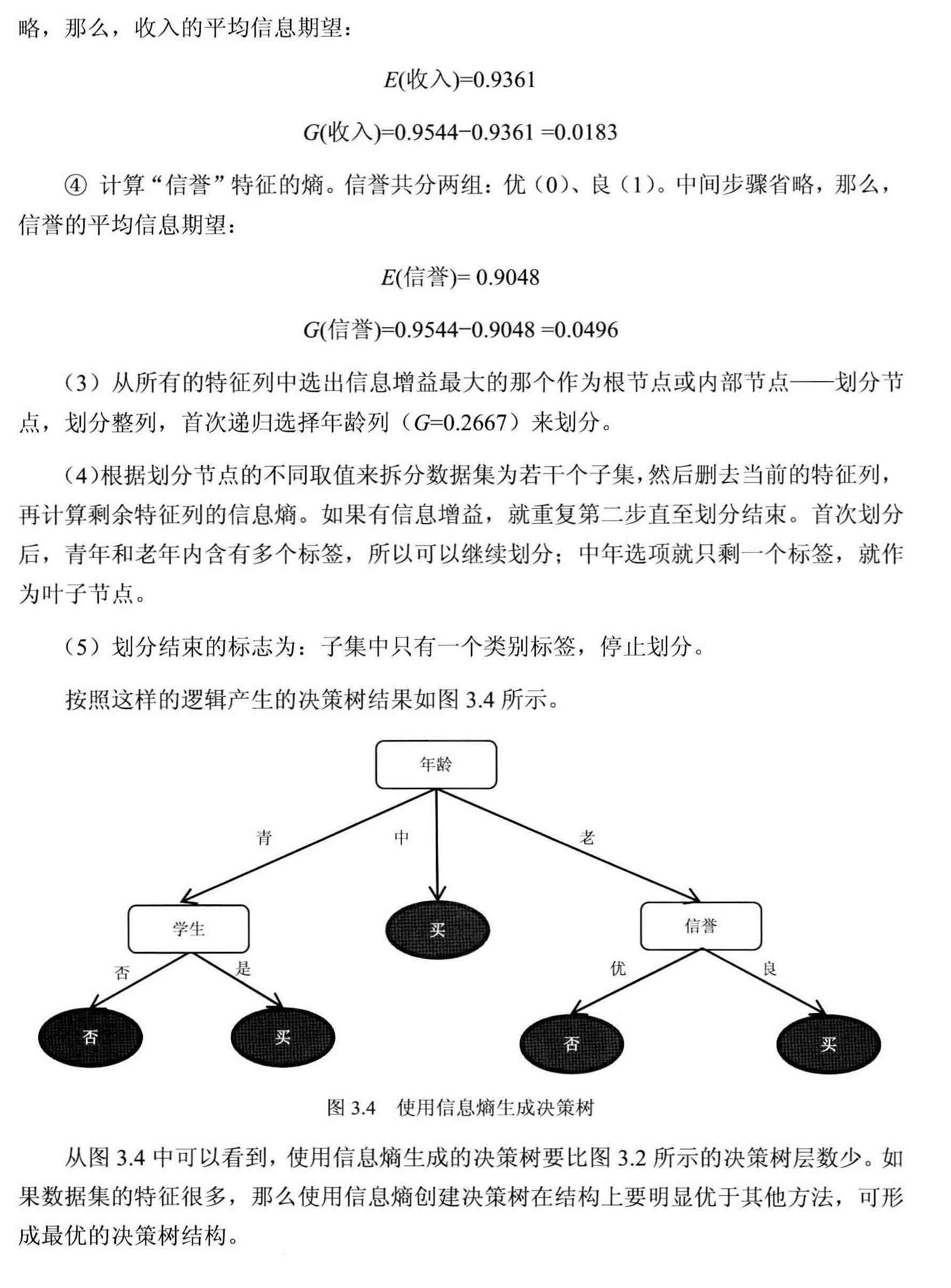
Python代码实现案例参考这篇博客:http://www.cnblogs.com/hemiy/p/6165759.html
以上是关于决策树原理及实现的主要内容,如果未能解决你的问题,请参考以下文章
Matlab基于决策树算法实现多分类预测(源码可直接替换数据)