pyton全栈开发从入门到放弃之数据类型与变量
Posted 一只丶顽皮猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pyton全栈开发从入门到放弃之数据类型与变量相关的知识,希望对你有一定的参考价值。
一.变量
1 什么是变量之声明变量
#变量名=变量值 age=18 gender1=\'male\' gender2=\'female\'
2 为什么要有变量
变量作用:“变”=>变化,“量”=>计量/保存状态
程序的运行本质是一系列状态的变化,变量的目的就是用来保存状态,变量值的变化就构成了程序运行的不同结果。
例如:CS枪战,一个人的生命可以表示为life=active表示存活,当满足某种条件后修改变量life=inactive表示死亡。
3 变量值之类型与对象
程序中需要处理的状态很多,于是有了不同类型的变量值,x=\'egon\',变量值\'egon\'存放与内存中,绑定一个名字x,变量值即我们要存储的数据。
在python中所有数据都是围绕对象这个概念来构建的,对象包含一些基本的数据类型:数字,字符串,列表,元组,字典等
程序中存储的所有数据都是对象,
一个对象(如a=1)有:
一个身份(id)
一个类型(type)
一个值(通过变量名a来查看)
1 对象的类型也称为对象的类别,python为每个类型都定制了属于该类型特有的方法,极大地方便了开发者对数据的处理
2 创建某个特定类型的对象也称为创建了该类型的一个实例,工厂函数的概念来源于此
4 可变对象与不可变对象
实例被创建后,身份和类型是不可变的,
如果值是不可以被修改的,则是不可变对象
如果值是可以被修改的,则是可变对象
5 容器对象
某个对象包含对其他对象的引用,则称为容器或集合
6 对象的属性和方法
属性就是对象的值,方法就是调用时将在对象本身上执行某些操作的函数,使用.运算符可以访问对象的属性和方法,如
a=3+4j
a.real
b=[1,2,3]
b.append(4)
7 身份比较,类型比较,值比较
x=1
y=1
x is y #x与y是同一个对象,is比较的是id,即身份
type(x) is type(y) #对象的类型本身也是一个对象,所以可以用is比较两个对象的类型的身份
x == y #==比较的是两个对象的值是否相等
7 变量的命名规范
- 变量命名规则遵循标识符命名规则,详见第二篇
8 变量的赋值操作
- 与c语言的区别在于变量赋值操作无返回值
- 链式赋值:y=x=a=1
- 多元赋值:x,y=1,2 x,y=y,x
- 增量赋值:x+=1
二.数据类型
2.1 什么是数据类型及数据类型分类
程序的本质就是驱使计算机去处理各种状态的变化,这些状态分为很多种
例如英雄联盟游戏,一个人物角色有名字,钱,等级,装备等特性,大家第一时间会想到这么表示
名字:德玛西亚------------>字符串
钱:10000 ------------>数字
等级:15 ------------>数字
装备:鞋子,日炎斗篷,兰顿之兆---->列表
(记录这些人物特性的是变量,这些特性的真实存在则是变量的值,存不同的特性需要用不同类型的值)
python中的数据类型
python使用对象模型来存储数据,每一个数据类型都有一个内置的类,每新建一个数据,实际就是在初始化生成一个对象,即所有数据都是对象
对象三个特性
- 身份:内存地址,可以用id()获取
- 类型:决定了该对象可以保存什么类型值,可执行何种操作,需遵循什么规则,可用type()获取
- 值:对象保存的真实数据
注:我们在定义数据类型,只需这样:x=1,内部生成1这一内存对象会自动触发,我们无需关心
这里的字符串、数字、列表等都是数据类型(用来描述某种状态或者特性)除此之外还有很多其他数据,处理不同的数据就需要定义不同的数据类型
| 标准类型 | 其他类型 |
| 数字 | 类型type |
| 字符串 | Null |
| 列表 | 文件 |
| 元组 | 集合 |
| 字典 | 函数/方法 |
| 类 | |
| 模块 |
2.2 标准数据类型:
2.2.1 数字
定义:a=1 特性: 1.只能存放一个值 2.一经定义,不可更改 3.直接访问 分类:整型,长整型,布尔,浮点,复数
2.2.1.1 整型:
Python的整型相当于C中的long型,Python中的整数可以用十进制,八进制,十六进制表示。
>>> 10 10 --------->默认十进制 >>> oct(10) \'012\' --------->八进制表示整数时,数值前面要加上一个前缀“0” >>> hex(10) \'0xa\' --------->十六进制表示整数时,数字前面要加上前缀0X或0x
python2.*与python3.*关于整型的区别
python2.*
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
python3.*整形长度无限制
整型工厂函数int()
 python2.7 python3.5
python2.7 python3.52.2.1.2 长整型long:
python2.*:
跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,
但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?
通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的,例如:
a = 9223372036854775808L
注意,自从Python2起,如果发生溢出,Python会自动将整型数据转换为长整型,
所以如今在长整型数据后面不加字母L也不会导致严重后果了。
python3.*
长整型,整型统一归为整型
查看2.2.1.3 布尔bool:
True 和False
1和0
2.2.1.4 浮点数float:
Python的浮点数就是数学中的小数,类似C语言中的double。
在运算中,整数与浮点数运算的结果是浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,
一个浮点数的小数点位置是可变的,比如,1.23*109和12.3*108是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,
就必须用科学计数法表示,把10用e替代,1.23*109就是1.23e9,或者12.3e8,0.000012
可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有
四舍五入的误差。
2.2.1.5 复数complex:
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注意,虚数部分的字母j大小写都可以,
>>> 1.3 + 2.5j == 1.3 + 2.5J True
2.2.1.6 数字相关内建函数
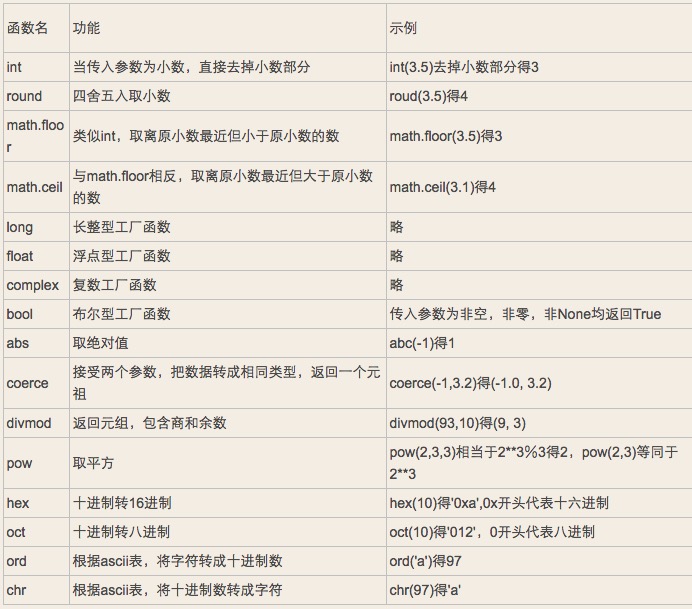
2.2.2 字符串
定义:它是一个有序的字符的集合,用于存储和表示基本的文本信息,‘’或“”或‘’‘ ’‘’中间包含的内容称之为字符串
特性:
1.只能存放一个值
2.不可变
3.按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r\'l\\thf\'
2.unicode字符串与r连用必需在r前面,如name=ur\'l\\thf\'
2.2.2.1 字符串创建
‘hello world’
2.2.2.2 字符串常用操作
移除空白
分割
长度
索引
切片
2.2.2.3 字符工厂函数str()
字符串工厂函数 python中str函数isdigit、isdecimal、isnumeric的区别2.2.3 列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
特性:
1.可存放多个值
2.可修改指定索引位置对应的值,可变
3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
2.2.3.1 列表创建
list_test=[’lhf‘,12,\'ok\']
或
list_test=list(\'abc\')
或
list_test=list([’lhf‘,12,\'ok\'])
2.2.3.2 列表常用操作
索引
切片
追加
删除
长度
切片
循环
包含
2.2.3.3 列表工厂函数list()
查看
2.2.4 元组
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值
2.不可变
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
2.2.4.1 元组创建
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
2.2.4.2 元组常用操作
索引
切片
循环
长度
包含
2.2.4.3 元组工厂函数tuple()
2.2.5 字典
定义:{key1:value1,key2:value2},key-value结构,key必须可hash
特性:
1.可存放多个值
2.可修改指定key对应的值,可变
3.无序
2.2.5.1 字典创建
person = {"name": "sb", \'age\': 18}
或
person = dict(name=\'sb\', age=18)
person = dict({"name": "sb", \'age\': 18})
person = dict(([\'name\',\'sb\'],[\'age\',18]))
{}.fromkeys(seq,100) #不指定100默认为None
注意:
>>> dic={}.fromkeys([\'k1\',\'k2\'],[])
>>> dic
{\'k1\': [], \'k2\': []}
>>> dic[\'k1\'].append(1)
>>> dic
{\'k1\': [1], \'k2\': [1]}
2.2.5.2 字典常用操作
索引
新增
删除
键、值、键值对
循环
长度
2.2.5.3 字典工厂函数dict()
2.2.6 集合
定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:
1.集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
2.2.6.1 集合创建
{1,2,3,1}
或
定义可变集合set
>>> set_test=set(\'hello\')
>>> set_test
{\'l\', \'o\', \'e\', \'h\'}
改为不可变集合frozenset
>>> f_set_test=frozenset(set_test)
>>> f_set_test
frozenset({\'l\', \'e\', \'h\', \'o\'})
2.2.6.2 集合常用操作:关系运算
in
not in
==
!=
<,<=
>,>=
|,|=:合集
&.&=:交集
-,-=:差集
^,^=:对称差分
2.2.6.3 集合工厂函数set()
查看
2.2.7 bytes类型
定义:存8bit整数,数据基于网络传输或内存变量存储到硬盘时需要转成bytes类型,字符串前置b代表为bytes类型
>>> x \'hello sb\' >>> x.encode(\'gb2312\') b\'hello sb\'
2.2.8 数据类型转换内置函数汇总
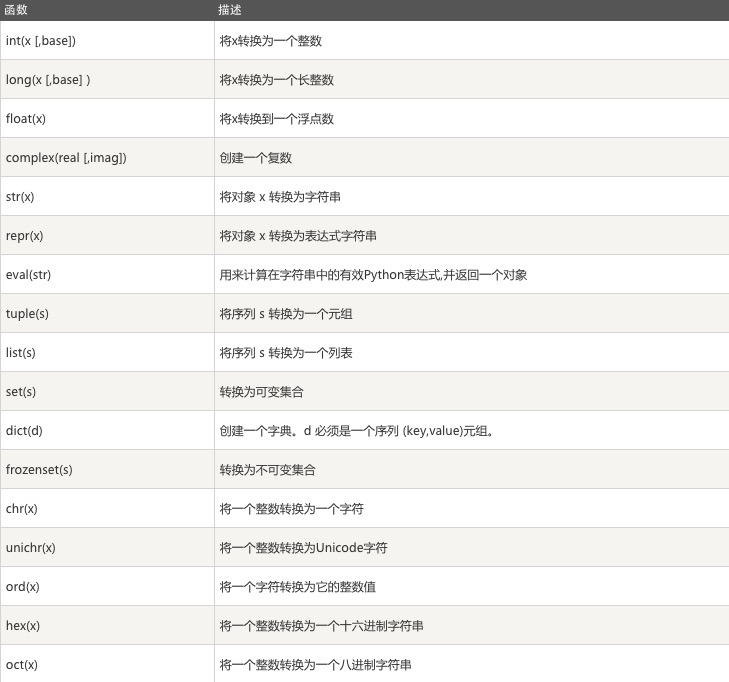
注:真对acsii表unichr在python2.7中比chr的范围更大,python3.*中chr内置了unichar
三.运算符
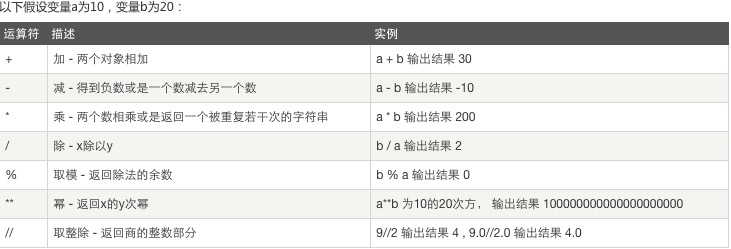
2、比较运算:

3、赋值运算:
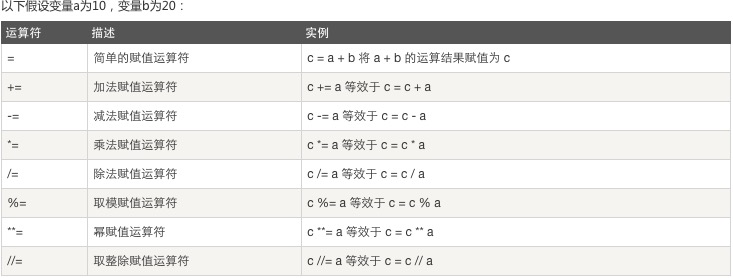
4、位运算:
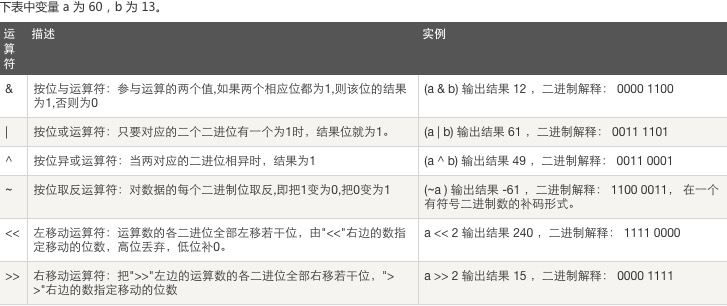
注: ~ 举例: ~5 = -6 解释: 将二进制数+1之后乘以-1,即~x = -(x+1),-(101 + 1) = -110
按位反转仅能用在数字前面。所以写成 3+~5 可以得到结果-3,写成3~5就出错了
5、逻辑运算:

and注解:
- 在Python 中,and 和 or 执行布尔逻辑演算,如你所期待的一样,但是它们并不返回布尔值;而是,返回它们实际进行比较的值之一。
- 在布尔上下文中从左到右演算表达式的值,如果布尔上下文中的所有值都为真,那么 and 返回最后一个值。
- 如果布尔上下文中的某个值为假,则 and 返回第一个假值
or注解:
- 使用 or 时,在布尔上下文中从左到右演算值,就像 and 一样。如果有一个值为真,or 立刻返回该值
- 如果所有的值都为假,or 返回最后一个假值
- 注意 or 在布尔上下文中会一直进行表达式演算直到找到第一个真值,然后就会忽略剩余的比较值
and-or结合使用:
- 结合了前面的两种语法,推理即可。
- 为加强程序可读性,最好与括号连用,例如:
(1 and \'x\') or \'y\'
6、成员运算:

7.身份运算

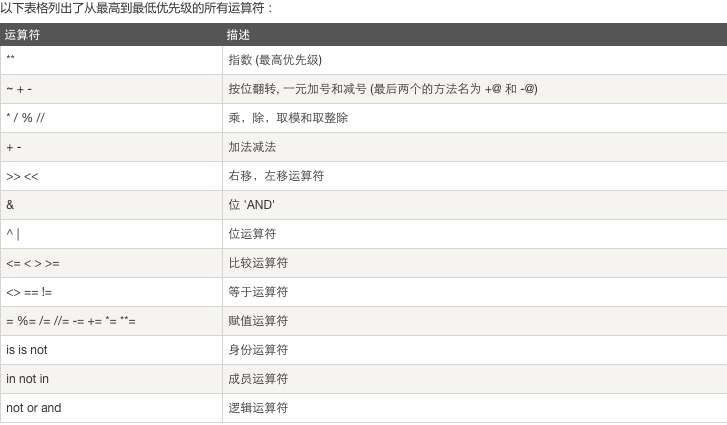
8.运算符优先级:自上而下,优先级从高到低
四.标准数据类型特性总结
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
示例:
# 可变数据类型 [] {} # 不可变数据类型 数字 字符串 元组 s="hello".upper() print(s) l=[1,2,3] c=[4,5] l.append(c) c.append(7) print(c) # print(l) 输出结果: l=[1,2,3,[4,5,7]] c=[4,5,7] #可变数据类型是id不变,就是说明值存在一个内存空间,当把这个值添加到一个列表或者字典中,值就是指向这个id的内存空间,这样就是相当于后面这个值变了,前面添加这个id的值也跟着变,因为赋上的内存空间。 d1={"name":"yuan"} d2={"age":12} d1["xxx"]=d2 d2["height"]="180cm" print(d1) # {"name":"yuan","xxx":{"age":12,"height":"180cm"}} d1={1:{"xxx":[12,34]},2:{"xxx":[34,56]}} d2={"xxx":[777,888,999]} d3={"xxx":[11,8238,99]} d1[2]["xxx"].append(d2["xxx"]) d2["xxx"].append(d3["xxx"]) print(d1) # {1:{"xxx":[12,34]},2:{"xxx":[34,56,[777,888,999,[11,8238,99]]]}} print(d2) # {"xxx":[777,888,999,[11,8238,99]]} print(d3) # d3={"xxx":[11,8238,99]} \'\'\' 总结: 可变数据类型在插入数据是存在一个内存空间中的 \'\'\'
可变数据类型:在Id不变的情况下,value可以改变
num=10 列表
id 字典
type
value
不可变数据类型:value改变,id也跟着改变
数字
字符串
布尔
示例:
补充:
True===>1
false==>0
以上是关于pyton全栈开发从入门到放弃之数据类型与变量的主要内容,如果未能解决你的问题,请参考以下文章