02. 基本分类:基于决策树的分类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02. 基本分类:基于决策树的分类相关的知识,希望对你有一定的参考价值。
分类技术
主要的分类技术
? 基于决策树的方法
? 基于规则的方法
? 基于实例的方法
? 贝叶斯信念网络
? 神经网络
? 支持向量机
分类的两个主要过程
训练/学习过程
预测/应用过程
决策树归纳
构建决策树的主要算法
- Hunt (最早的决策树归纳算法之一)
- CART (较为复杂,只适用于小规模数据的拟合)
- ID3 (无法处理数值属性,需要将数值属性进行离散化预处理)
- C4.5 (ID3的升级版本,基本算法同ID3,可以处理数值属性)
- SLIQ,SPRINT(主要使用与大数据的处理)
Hunt算法构造决策树的基本步骤
1. 开始,将所有记录看成一个节点;
2. 选择一个属性测试条件,将数据集分割为较小的子集,并创建为一个子节点;
3. 对于分割的每一个子集节点使用父节点剩余的属性测试条件继续分割,直到分割子集的类标属性成分单一;
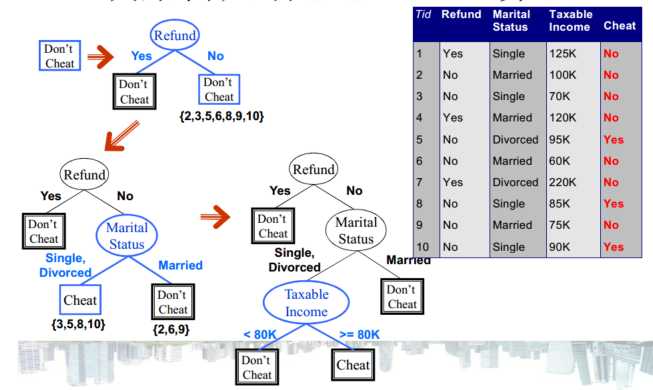
ID3算法构造决策树的基本步骤
1. 开始,所有记录看作一个节点;
2. 遍历每个变量的每一种分割方式,找到最好的分割点;
3. 分割成两个节点N1 和N2 ;
4. 对N 1 和N 2 分别继续执行2-3步,直到每个节点的不纯性足够低为止;
基于决策树分类的优点
- 构造树的代价不高
- 对未知记录归类非常迅速
- 规模较小的树容易解释
- 对很多简单的数据集,准确率可以与其他分类
决策树归纳的2个主要的设计问题
1、如何划分训练集
1)如何指定属性测试条件
? 依赖于属性类型
– 标称属性– 序数属性– 连续属性/数值属性
? 依赖于测试的输出个数
– 二路划分:将属性值划分成两个子集,如果基于数值属性,则将属性离散化为序数属性(有静态划分和动态划分2种方式),– 多路划分: 输出个数取决于该属性不同属性值的个数,如果是基于数值属性,则考虑所有的划分点,寻找最佳划分点(A<v)or(A>v);
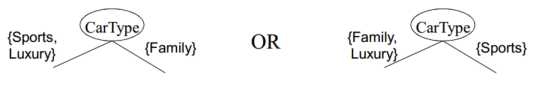
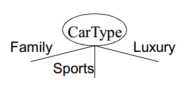
2)如何确定最佳划分
①结点不纯性的度量
- 要求划分后子女结点的不纯性度量的值越低越好(即节点纯度越高);
②有3种不纯性度的量度:
- Gini指标(Gini Index)p(j | t) 是类j在结点t的出现概率Gini指标的取值范围
max 1 - 1/nc,出现的情况是t对应的记录集在所有类中均匀分布min 0,出现的情况是t对应的所有记录都属于同一个类
- 熵(Entropy)熵的取值范围
max log2 nc,出现的情况是t对应的记录集在所有类中均匀分布;min 0,出现的情况是t对应的所有记录都属于同一个类;
- 误分率(Misclassification error)误分率的取值范围max 1 - 1/nc,出现的情况是t对应的记录集在所有类中均匀分布min 最小0,出现的情况是t对应的所有记录都属于同一个类
③基于不同不纯性度量指标划分方式
- 基于Gini指标的划分(使用于CART, SLIQ, SPRINT)当一个结点p输出k个子女时,该划分的总Gini指标计算为:ni = 子女结点i对应的记录个数,n = 结点p对应的记录个数- 基于信息的划分(ID3算法引入)结点p输出k个子女;ni 是第i个子女对应的记录个数由于划分导致熵减少;选择熵减少量最大的划分点,即信息增益最大的划分点
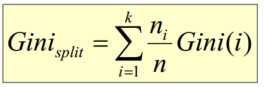
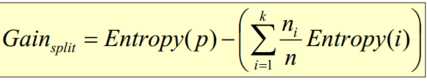
2、何时停止划分
- 当所有记录从属同一个类时停止扩展结点
Hunt算法引入的条件
- 当所有记录中对应属性的取值都相同时停止扩展
再划分不能改变当前训练集的类分布
- 早期停止
防止过分拟合
决策树归纳在Rapidminer中的实现
ID3算法,对应的算子是【ID3】,要先使用【Discretize】算子进行离散化预处理
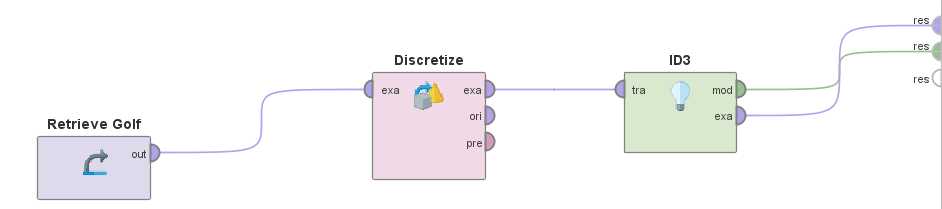
C4.5算法,对应的算子是【Decision Tree】
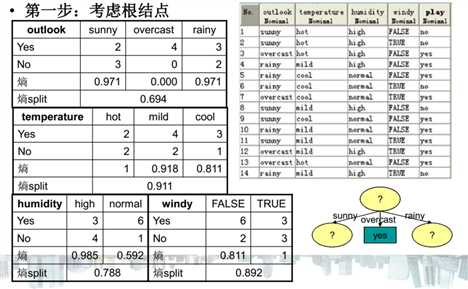
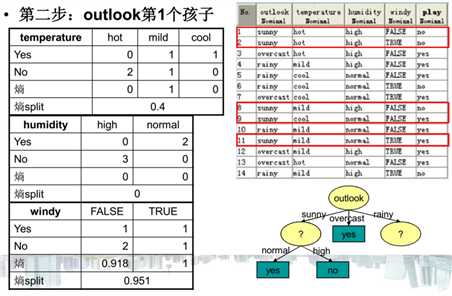
关于ID3算法的计算流程

以上是关于02. 基本分类:基于决策树的分类的主要内容,如果未能解决你的问题,请参考以下文章