Worker的内部工作原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Worker的内部工作原理相关的知识,希望对你有一定的参考价值。
一、Worker、Executor、Task 三者的关系
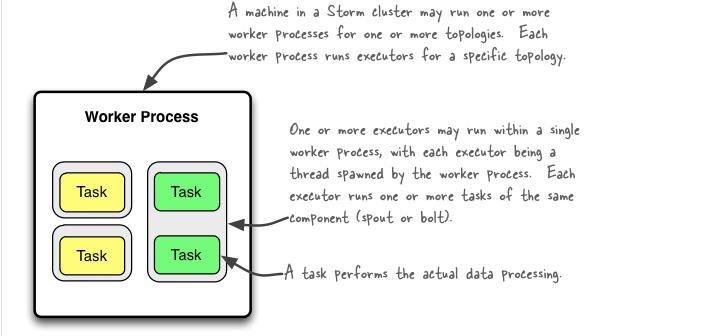
storm集群中的一台机器可能运行着一个或者多个worker进程,其从属于一个或者多个topology。一个worker进程运行着多个executor线程;每一个worker从属于一个topology;executor是单线程,每一个executor运行着相同组件(spout或者bolt)的1个或者多个task;1个task执行(spout或bolt)中的逻辑处理;用一句话来概括就是,一个worker运行着一个或者多个executor,每个executor又运行着1个或者多个task。
二、核心概念
1、 一个worker进程执行的是一个Topology的子集(不会出现一个worker进程为多个Topology服务),一个worker进程会启动一个或多个executor线程来执行一个topology的component(Spout或Bolt),因此,一个运行中的topology就是由集群中多台物理机上的多个worker进程组成的;
2、 Executor是一个被Worker进程启动的单独线程,每个executor只会运行一个topology的一个component(spout或bolt)的task(task可以是一个或多个,Storm默认是一个component只生成一个task,executor线程会在每次循环里顺序调用所有task实例);
3、 Task是最终运行spout或bolt中代码的单元(一个task即为spout或bolt的一个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)topology启动后,一个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程可以动态调整(例如:一个executor线程可以执行该component的一个或多个task实例)这意味着,对于一个component存在这样的条件,threads<=tasks(即,线程数小于task数目)。默认情况下task的数目等于executor线程数目,即一个executor线程只运行一个task。
4、调整正在运行的topology的并行度:storm rebalance topology_name -n N -e spout_name=N -e bolt_name=N
三、工作原理:
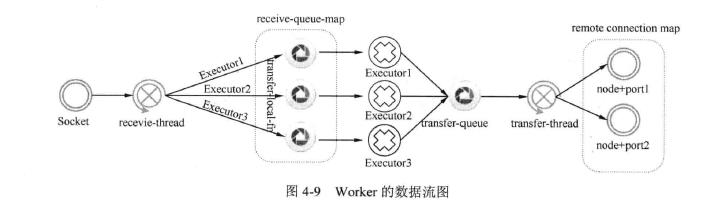
在worker中,线程间通信是通过Disruptor,而进程间的通信也就是Worker和Worker之间的通信使用的是IContext接口的具体实现,有可能是Netty也可以是ZMQ,默Netty。Worker的工作流程如图4-9所示:
每个Worker会绑定一个Socket端口作为数据的输入,此端口作为Socket的服务器端一直监听运行。根据Topology中的拓扑关系,确定需要向外通信的Task所在的Worker的地址,并同该Worker也创建好Socket连接;此时该Worker是所为Socket的客户端;
Receive Thread 调用transfer-local-fn方法负责将每个Excecutor所需要的数据放入到对应的receive-queue-map中,然后由Executor来获取自己所需要的数据,这一过程是通过Disruptor来通信的,
Executor执行完操作需要对外发送数据时,首先KryoTupleSerializer将数据序列化,然后通过Disruptor将数据放入对外的transfer-queue中,最后有transfer-thread来完成数据的发送工作。
如果Executor所需要对外发送的数据接收方和Executor是在同一个worker中节点上,则不需要执行序列化操作。调用disruptor的publish方法直接放到接收方的executor对应的队列中即可。
以上是关于Worker的内部工作原理的主要内容,如果未能解决你的问题,请参考以下文章
Spark Executor内幕彻底解密:Executor工作原理图ExecutorBackend注册源码解密Executor实例化内幕Executor具体工作内幕