Worker所起的作用有以下几个:
1. 接受Master的指令,启动或者杀掉Executor
2. 接受Master的指令,启动或者杀掉Driver
3. 报告Executor/Driver的状态到Master
4. 心跳到Master,心跳超时则Master认为Worker已经挂了不能工作了
5. 向GUI报告Worker的状态
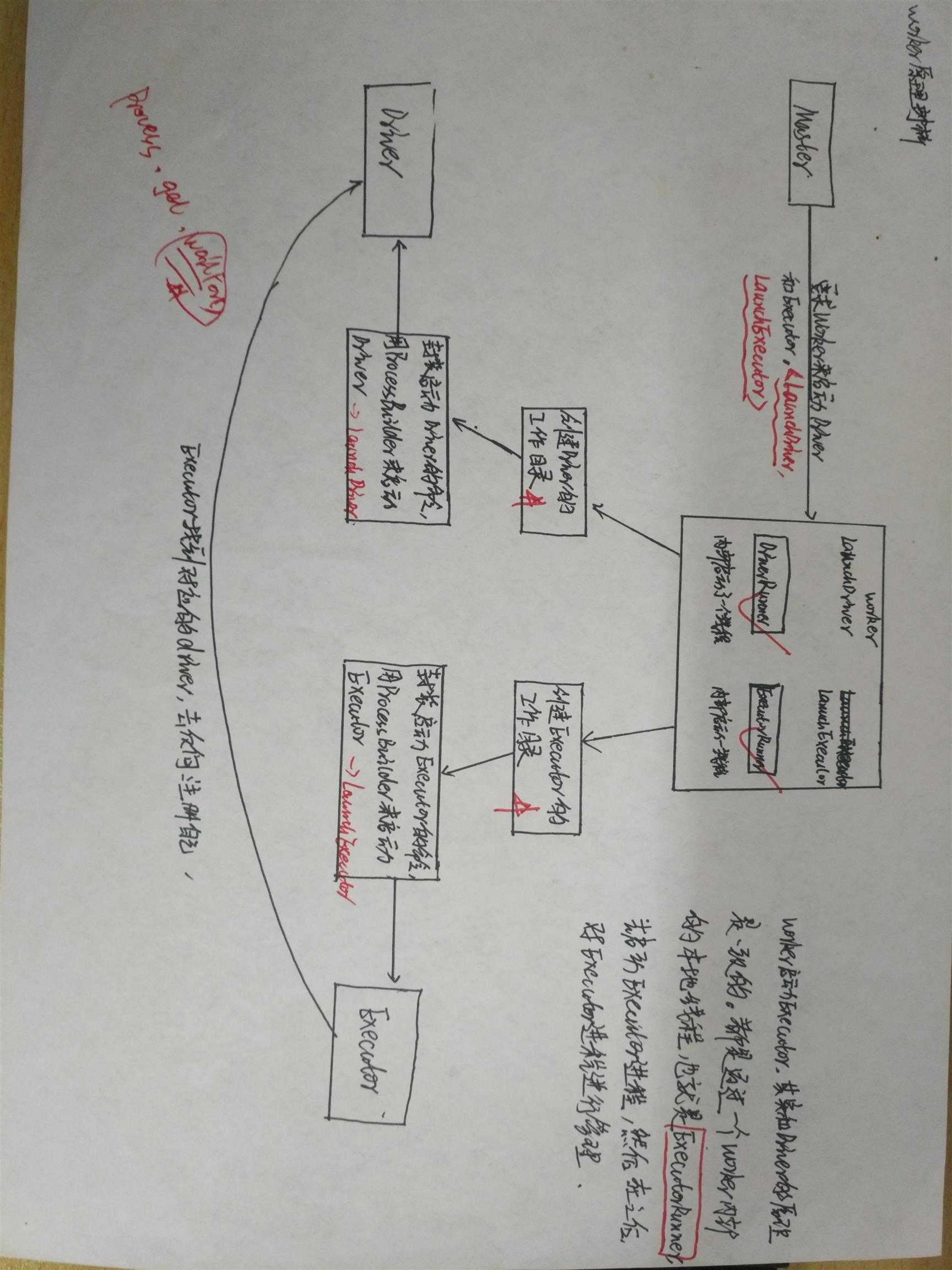
[注]其实只有cluster模式才会在worker节点上面启动Driver,而stabdalone和client都是在本地启动Driver
1, Cluster中的Driver失败的时候,如果supervise为true,则启动该Driver的Worker会负责重新启动该Driver
2, DriverRunner启动进程是通过processBuilder中的process.get.waitFor来完成;
3, ExecutorRunner启动进程与DriverRunner类似:通过processBuilder中的process.waitFor来完成;
一 重要属性
private[deploy] class Worker(
override val rpcEnv: RpcEnv, // 用于注册和维护RpcEndpoint和RpcEndpointRef
webUiPort: Int, // web ui 端口
cores: Int, // 分配给该worker的CPU核数
memory: Int, // 分配给该worker的内存容量
masterRpcAddresses: Array[RpcAddress], // master RpcAddress数组
systemName: String, // 所在节点的职责名称-->Master/Worker
endpointName: String, // worker的rpc终端名字
workDirPath: String = null, // 工作目录
val conf: SparkConf,
// SecurityManager安全管理器
val securityMgr: SecurityManager )
extends ThreadSafeRpcEndpoint with Logging {
private val host = rpcEnv.address.host
private val port = rpcEnv.address.port
Utils.checkHost(host, "Expected hostname")
// assert():如果它的条件返回错误,则终止程序执行
assert (port > 0)
// 一个后台调度线程,在指定的时间发送消息
private val forwordMessageScheduler =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("worker-forward-message-scheduler")
// 一个后台清理工作目录的线程
private val cleanupThreadExecutor = ExecutionContext.fromExecutorService(
ThreadUtils.newDaemonSingleThreadExecutor("worker-cleanup-thread"))
// 日期格式,用于构建application IDs
private def createDateFormat = new SimpleDateFormat("yyyyMMddHHmmss")
// 向Master发送心跳频率 every (heartbeat timeout) / 4 milliseconds
// 60s内master接收不到worker的心跳信息,master就认为该worker 丢失了
private val HEARTBEAT_MILLIS = conf.getLong("spark.worker.timeout", 60) * 1000 / 4
// 向master注册初始重试次数,默认是6次
private val INITIAL_REGISTRATION_RETRIES = 6
// 向master注册总的尝试次数
private val TOTAL_REGISTRATION_RETRIES = INITIAL_REGISTRATION_RETRIES + 10
private val FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND = 0.500
private val REGISTRATION_RETRY_FUZZ_MULTIPLIER = {
val randomNumberGenerator = new Random(UUID.randomUUID.getMostSignificantBits)
randomNumberGenerator.nextDouble + FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND
}
// 初始化的注册重试间隔
private val INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(10 *
REGISTRATION_RETRY_FUZZ_MULTIPLIER))
// 延长的注册重试间隔
private val PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(60
* REGISTRATION_RETRY_FUZZ_MULTIPLIER))
// 是否启用cleanup功能
private val CLEANUP_ENABLED = conf.getBoolean("spark.worker.cleanup.enabled", false)
// cleanup时间间隔
private val CLEANUP_INTERVAL_MILLIS =
conf.getLong("spark.worker.cleanup.interval", 60 * 30) * 1000
// app数据保存时间长度
private val APP_DATA_RETENTION_SECONDS =
conf.getLong("spark.worker.cleanup.appDataTtl", 7 * 24 * 3600)
private val testing: Boolean = sys.props.contains("spark.testing")
private var master: Option[RpcEndpointRef] = None // master终端
private var activeMasterUrl: String = ""
private[worker] var activeMasterWebUiUrl : String = "" // 当前有效的master url
private val workerUri = rpcEnv.uriOf(systemName, rpcEnv.address, endpointName) // worker的url
private var workerWebUiUrl: String = "" // worker的web ui url
private var registered = false // 该worker是否已经注册
private var connected = false // 该worker是否连接到master
private val workerId = generateWorkerId() // worker的id
private val sparkHome =
if (testing) {
assert(sys.props.contains("spark.test.home"), "spark.test.home is not set!")
new File(sys.props("spark.test.home"))
} else {
new File(sys.env.get("SPARK_HOME").getOrElse("."))
}
var workDir: File = null
// worker维护的一个已经完成任务的Executor id -> ExecutorRunner的映射
val finishedExecutors = new LinkedHashMap[String, ExecutorRunner]
// worker维护的一个所有driver id -> DriverRunner的映射
val drivers = new HashMap[String, DriverRunner]
// worker维护的一个所有executor id -> ExecutorRunner的映射
val executors = new HashMap[String, ExecutorRunner]
// worker维护的一个已经完成任务的driver id -> DriverRunner的映射
val finishedDrivers = new LinkedHashMap[String, DriverRunner]
// worker维护的一个application id -> app目录的映射
val appDirectories = new HashMap[String, Seq[String]]
// 该worker已经完成工作的application
val finishedApps = new HashSet[String]
二 核心方法
2.1 main方法
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
// 解析启动参数列表
val args = new WorkerArguments(argStrings, conf)
// 启动Rpc通信环境和通信终端
// 关于spark RPC 通信机制,后面再讲
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
main方法先获取配置参数创建SparkConf,通过startRpcEnvAndEndpoint启动一个RPCEnv并创建一个Endpoint,调用awaitTermination来阻塞服务端监听请求并且处理。下面细看startRpcEnvAndEndpoint方法:
2.1.1 startRpcEnvAndEndpoint()创建RpcEnv,启动Rpc服务
/**
* 启动Rpc通信环境和通信终端
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
// 创建RpcEnv
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
// 创建一个Endpoint
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, systemName, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
2.2 onstart 启动worker
/**
* onstart() 启动worker
* 其实这就是RPC生命周期的开始方法
* onStart -> receive(receiveAndReply)* -> onStop
*/
override def onStart() {
assert(!registered)
logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(
host, port, cores, Utils.megabytesToString(memory)))
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
logInfo("Spark home: " + sparkHome)
// 创建worker工作目录
createWorkDir()
// 如果ExternalShuffleService 启用了,就调用它的start方法
shuffleService.startIfEnabled()
// 创建 worker的web ui 并绑定
webUi = new WorkerWebUI(this, workDir, webUiPort)
webUi.bind()
val scheme = if (webUi.sslOptions.enabled) "https" else "http"
workerWebUiUrl = s"$scheme://$publicAddress:${webUi.boundPort}"
// 向Master注册
registerWithMaster()
metricsSystem.registerSource(workerSource)
metricsSystem.start()
// Attach the worker metrics servlet handler to the web ui after the metrics system is started.
metricsSystem.getServletHandlers.foreach(webUi.attachHandler)
}
2.3 createWorkDir 创建工作目录
/**
* createWorkDir() 创建工作目录
*/
private def createWorkDir() {
// 获取工作目录
workDir = Option(workDirPath).map(new File(_)).getOrElse(new File(sparkHome, "work"))
try {
// 创建目录
workDir.mkdirs()
// 如果目录不存在或者不是目录,则退出
if ( !workDir.exists() || !workDir.isDirectory) {
logError("Failed to create work directory " + workDir)
System.exit(1)
}
// assert断言-->如果它的条件返回错误,则终止程序执行
assert (workDir.isDirectory)
} catch {
case e: Exception =>
logError("Failed to create work directory " + workDir, e)
System.exit(1)
}
}
2.4 registerWithMaster():向master注册
/**
* registerWithMaster():向master注册
*/
private def registerWithMaster() {
registrationRetryTimer match {
// 如果没有,说明还没有注册,然后会开始去注册
case None =>
// 初始注册状态为false
registered = false
// 尝试向所有master注册
registerMasterFutures = tryRegisterAllMasters()
// 连接尝试次数初始化为0
connectionAttemptCount = 0
// 网络或者Master故障的时候就需要重新注册自己
// 注册重试次数超过阈值则直接退出
// 启动后台线程定时调度
// 发送ReregisterWithMaster请求,如果之前已经注册成功,则下一次来注册,则啥也不做
registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster))
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
// 如果已经注册了,就啥都不做
case Some(_) =>
logInfo("Not spawning another attempt to register with the master, since there is an" +
" attempt scheduled already.")
}
}
registrationRetryTimer第一次调用肯定为None,通过tryRegisterAllMasters向Master注册自己,后面还启动了一个线程在有限次数内去尝试重新注册(网络或者Master出现故障是需要重新注册)
2.5 tryRegisterAllMasters 尝试向所有的集群内所有master注册
/**
* tryRegisterAllMasters 尝试向所有的集群内所有master注册
* @return
*/
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
// 构造master RpcEndpoint,用于向master发送消息或者请求
val masterEndpoint =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
// 向指定的master注册
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
})
}
}
这里调用了rpcEnv.setupEndpointRef,RpcEndpointRef 是 RpcEnv 中的 RpcEndpoint 的引用,是一个序列化的实体以便于通过网络传送或保存以供之后使用。一个 RpcEndpointRef 有一个地址和名字。可以调用 RpcEndpointRef 的 send 方法发送异步的单向的消息给对应的 RpcEndpoint 。
整段代码意思即是:遍历所有masterRpcAddresses,调用registerWithMaster方法,并传入master端的RpcEndpoint引用RpcEndpointRef
2.6 registerWithMaster(masterEndpoint: RpcEndpointRef)向master注册
/**
* registerWithMaster(masterEndpoint: RpcEndpointRef) 向指定master注册
* @param masterEndpoint
* 通过RpcEndpointRef 和Master建立通信向Master发送RegisterWorker消息,
* 并带入workerid,host,Port,cores,内存等参数信息,并有成功或者失败的回调函数
*/
private def registerWithMaster(masterEndpoint: RpcEndpointRef): Unit = {
// 向master发送RegisterWorker请求
masterEndpoint.ask[RegisterWorkerResponse](RegisterWorker(
workerId, host, port, self, cores, memory, workerWebUiUrl))
.onComplete {
// 回调成功,则调用handleRegisterResponse
case Success(msg) =>
Utils.tryLogNonFatalError {
handleRegisterResponse(msg)
}
// 回调失败,则退出
case Failure(e) =>
logError(s"Cannot register with master: ${masterEndpoint.address}", e)
System.exit(1)
}(ThreadUtils.sameThread)
}
2.7 handleRegisterResponse 处理回调函数的结果
/**
* handleRegisterResponse(msg: RegisterWorkerResponse) 处理回调函数的结果
* @param msg
*/
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
// 如果是RegisteredWorker请求,表示已经注册成功
case RegisteredWorker(masterRef, masterWebUiUrl) =>
logInfo("Successfully registered with master " + masterRef.address.toSparkURL)
// 更新registered状态
registered = true
// 更新映射,删除其他的registeration retry
changeMaster(masterRef, masterWebUiUrl)
// 后台线程开始定时调度向master发送心跳的线程
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat)
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
// 如果启用了cleanup功能,后台线程开始定时调度发送WorkDirCleanup指令,清理目录
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(WorkDirCleanup)
}
}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
// 如果是RegisterWorkerFailed请求,表示注册失败
case RegisterWorkerFailed(message) =>
// 如果还没有注册成功,则退出
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
// 如果是MasterInStandby请求,则啥也不做
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}
当注册Worker失败收到RegisterWorkerFailed消息,则退出。
当注册的Master处于Standby状态,直接忽略。
注册Worker成功返回RegisteredWorker消息时,先标记注册成功,然后通过changeMaster更改一些变量(如activeMasterUrl,master,connected等),并删除当前其他正在重试的注册。然后新建了一个task到线程池执行,该线程每隔HEARTBEAT_MILLIS时间向自己发送一个SendHeartbeat消息,在消息处理方法receive里面可看到消息处理方法,即向Master发送心跳:
case SendHeartbeat =>
if (connected) { sendToMaster(Heartbeat(workerId, self)) }
2.8 receive 接受消息,但是不需要返回结果
/**
* receive() 同步接收消息,但是不需要返回结果
* @return
*/
override def receive: PartialFunction[Any, Unit] = synchronized {
// 如果接收的是SendHeartbeat消息,表示需要向master发送心跳请求
case SendHeartbeat =>
if (connected) { sendToMaster(Heartbeat(workerId, self)) }
// 如果接收的是WorkDirCleanup消息,表示需要清理工作目录
case WorkDirCleanup =>
// 首先通过executors获取它所对应的app id的集合
val appIds = executors.values.map(_.appId).toSet
// 获取那些已经完毕的application目录,并且递归删除之,将处理结果封装在Future对象里
val cleanupFuture = concurrent.future {
// 获取该目录下所有文件
val appDirs = workDir.listFiles()
if (appDirs == null) {
throw new IOException("ERROR: Failed to list files in " + appDirs)
}
appDirs.filter { dir =>
// 获取目录名字
val appIdFromDir = dir.getName
// 判断这个目录所在的application是否正在运行
// 如果是目录,且不再包含任何新文件,则递归删除该目录
val isAppStillRunning = appIds.contains(appIdFromDir)
dir.isDirectory && !isAppStillRunning &&
!Utils.doesDirectoryContainAnyNewFiles(dir, APP_DATA_RETENTION_SECONDS)
}.foreach { dir =>
logInfo(s"Removing directory: ${dir.getPath}")
Utils.deleteRecursively(dir)
}
}(cleanupThreadExecutor)
cleanupFuture.onFailure {
case e: Throwable =>
logError("App dir cleanup failed: " + e.getMessage, e)
}(cleanupThreadExecutor)
// 如果接收MasterChanged消息,表示master已经发生变化了
case MasterChanged(masterRef, masterWebUiUrl) =>
logInfo("Master has changed, new master is at " + masterRef.address.toSparkURL)
// 获取新的master的url和master,连接状态置为true,取消之前的尝试重新注册
changeMaster(masterRef, masterWebUiUrl)
// 创建当前节点executors的简单描述对象ExecutorDescription
val execs = executors.values.
map(e => new ExecutorDescription(e.appId, e.execId, e.cores, e.state))
// 向新的master发送WorkerSchedulerStateResponse消息
masterRef.send(WorkerSchedulerStateResponse(workerId, execs.toList, drivers.keys.toSeq))
// 如果接收到ReconnectWorker消息,表示之前worker断开,需要重新连接
case ReconnectWorker(masterUrl) =>
logInfo(s"Master with url $masterUrl requested this worker to reconnect.")
// 断开之后,需要重新向master注册
registerWithMaster()
// 如果接收到LaunchExecutor消息,表示需要发起executor
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
// 检测master是否有效
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// 创建executor目录,appId/execId
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// 获取application本地目录,如果没有则创建,最后这些目录在应用程序运行完毕之后删除掉
val appLocalDirs = appDirectories.get(appId).getOrElse {
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq
}
appDirectories(appId) = appLocalDirs
// 创建ExecutorRunner对象,主要负责管理executor进程的执行
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
// worker维护的executor id->ExecutorRunner 映射添加这个新建的 ExecutorRunner
executors(appId + "/" + execId) = manager
// 启动这个ExecutorRunner
manager.start()
// 重新计算已经使用的cpu核数和内存容量
coresUsed += cores_
memoryUsed += memory_
// 向master发送ExecutorStateChanged消息
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
case e: Exception => {
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}
}
// 如果接收ExecutorStateChanged消息,表示executor状态发生改变
case executorStateChanged @ ExecutorStateChanged(appId, execId, state, message, exitStatus) =>
handleExecutorStateChanged(executorStateChanged)
// 如果接收到KillExecutor消息,表示需要杀掉这个executor进程
case KillExecutor(masterUrl, appId, execId) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor " + execId)
} else {
val fullId = appId + "/" + execId
executors.get(fullId) match {
case Some(executor) =>
logInfo("Asked to kill executor " + fullId)
executor.kill()
case None =>
logInfo("Asked to kill unknown executor " + fullId)
}
}
// 如果接收到LaunchDriver消息,表示启动Driver
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
// 创建DriverRunner,分配资源
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
workerUri,
securityMgr)
// 加入到drivers
drivers(driverId) = driver
// 启动这个driver
driver.start()
// 重新计算当前worker使用的内存和cpu
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
}
// 如果接收到KillDriver消息,表示杀掉这个driver
case KillDriver(driverId) => {
logInfo(s"Asked to kill driver $driverId")
drivers.get(driverId) match {
case Some(runner) =>
runner.kill()
case None =>
logError(s"Asked to kill unknown driver $driverId")
}
}
// 如果接收到DriverStateChanged消息,表示driver状态改变
case driverStateChanged @ DriverStateChanged(driverId, state, exception) => {
handleDriverStateChanged(driverStateChanged)
}
// 如果接收到ReregisterWithMaster消息,表示需要重新向master注册
case ReregisterWithMaster =>
reregisterWithMaster()
// 如果接收到ApplicationFinished消息,表示application已经运行完毕
case ApplicationFinished(id) =>
finishedApps += id
// 这时候可能需要清理application目录了
maybeCleanupApplication(id)
}
2.9 receiveAndReply 接收消息吗,返回结果
/**
* receiveAndReply 接收消息,返回结果
* @param context
* @return
*/
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// 如果接收到RequestWorkerState消息,则需要返回worker的状态信息
case RequestWorkerState =>
context.reply(WorkerStateResponse(host, port, workerId, executors.values.toList,
finishedExecutors.values.toList, drivers.values.toList,
finishedDrivers.values.toList, activeMasterUrl, cores, memory,
coresUsed, memoryUsed, activeMasterWebUiUrl))
}
2.10 changeMaster获取新的master的url和master,取消之前那些重新注册尝试,因为已经发现新的master
/**
* changeMaster()
* 获取新的master的url和master,取消之前那些重新注册尝试,因为已经发现新的master
* @param masterRef
* @param uiUrl
*/
private def changeMaster(masterRef: RpcEndpointRef, uiUrl: String) {
// 获取新的master的url和master
activeMasterUrl = masterRef.address.toSparkURL
activeMasterWebUiUrl = uiUrl
master = Some(masterRef)
// 连接状态置为true
connected = true
// 取消之前那些重新注册尝试,因为已经发现新的maste
cancelLastRegistrationRetry()
}
2.11 handleExecutorStateChanged 处理executor状态改变
/**
* handleExecutorStateChanged() 处理executor状态改变
* @param executorStateChanged
*/
private[worker] def handleExecutorStateChanged(executorStateChanged: ExecutorStateChanged):
Unit = {
// 首先向master发送ExecutorStateChanged消息
sendToMaster(executorStateChanged)
// 获取Executor状态
val state = executorStateChanged.state
// 如果是完成状态
if (ExecutorState.isFinished(state)) {
val appId = executorStateChanged.appId
val fullId = appId + "/" + executorStateChanged.execId
val message = executorStateChanged.message
val exitStatus = executorStateChanged.exitStatus
// 从worker的维护的executor id和ExecuteRunner中获取ExecuteRunner
executors.get(fullId) match {
case Some(executor) =>
logInfo("Executor " + fullId + " finished with state " + state +
message.map(" message " + _).getOrElse("") +
exitStatus.map(" exitStatus " + _).getOrElse(""))
// 首先将这个ExecuteRunner移除executors映射集合
executors -= fullId
// 将它移动到处于完成状态的映射集合finishedExecutors
finishedExecutors(fullId) = executor
// 如果需要,则删除一些完成的executors
trimFinishedExecutorsIfNecessary()
// 释放CPU和内存
coresUsed -= executor.cores
memoryUsed -= executor.memory
case None =>
logInfo("Unknown Executor " + fullId + " finished with state " + state +
message.map(" message " + _).getOrElse("") +
exitStatus.map(" exitStatus " + _).getOrElse(""))
}
// 这时候可能会清理application工作目录
maybeCleanupApplication(appId)
}
}
}
2.12 handleDriverStateChanged 处理driver状态改变
/**
* handleDriverStateChanged() 处理driver状态改变
* @param driverStateChanged
*/
private[worker] def handleDriverStateChanged(driverStateChanged: DriverStateChanged): Unit = {
// 获取driver id
val driverId = driverStateChanged.driverId
val exception = driverStateChanged.exception
// 获取driver的状态
val state = driverStateChanged.state
state match {
case DriverState.ERROR =>
logWarning(s"Driver $driverId failed with unrecoverable exception: ${exception.get}")
case DriverState.FAILED =>
logWarning(s"Driver $driverId exited with failure")
case DriverState.FINISHED =>
logInfo(s"Driver $driverId exited successfully")
case DriverState.KILLED =>
logInfo(s"Driver $driverId was killed by user")
case _ =>
logDebug(s"Driver $driverId changed state to $state")
}
// 向master发送DriverStateChanged消息
sendToMaster(driverStateChanged)
// 从worker维护的driver id-->DriverRunner 映射 drivers集合移除,
// 并把它添加到处于完成状态的集合finishedDrivers
val driver = drivers.remove(driverId).get
finishedDrivers(driverId) = driver
// 如果需要,则删除一些完成的executors
trimFinishedDriversIfNecessary()
// 释放CPU和内存
memoryUsed -= driver.driverDesc.mem
coresUsed -= driver.driverDesc.cores
}
2.13 reregisterWithMaster 重新注册
/**
* reregisterWithMaster 重新注册
* 有时候会遇到网络异常或者master失败,则需要重新向master注册,如果注册超过指定的次数,则worker退出
*/
private def reregisterWithMaster(): Unit = {
Utils.tryOrExit {
// 初始化尝试连接次数加1
connectionAttemptCount += 1
// 如果之前已经注册成功的,则取消最近的重新尝试注册
if (registered) {
cancelLastRegistrationRetry()
} else if (connectionAttemptCount <= TOTAL_REGISTRATION_RETRIES) {
logInfo(s"Retrying connection to master (attempt # $connectionAttemptCount)")
// 向有效的master重新注册,如果没有,这就意味着worker仍然处于引导状态,还没有和master建立连接
// 在此种情况下,我们应该向所有的master重新注册
master match {
// 如果master存在,但是registered又是false,表示我们失去了master的连接,所以我们需要重新创建
// Master RpcEndpoint
case Some(masterRef) =>
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
val masterAddress = masterRef.address
registerMasterFutures = Array(registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
// 重新创建masterEndpoint
val masterEndpoint =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
// 然后再给新的master发送注册消息去注册
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
}))
// 如果没有则向所有master注册,否则容易出现重复的worker错误
case None =>
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
// We are retrying the initial registration
registerMasterFutures = tryRegisterAllMasters()
}
// 如果重新注册次数超过初始的阀值,那么就会使用一个更大间隔的阀值
if (connectionAttemptCount == INITIAL_REGISTRATION_RETRIES) {
registrationRetryTimer.foreach(_.cancel(true))
registrationRetryTimer = Some(
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(ReregisterWithMaster)
}
}, PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
}
} else {
logError("All masters are unresponsive! Giving up.")
System.exit(1)
}
}
}