爬虫学习——网页解释器简介
Posted ryuuku
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习——网页解释器简介相关的知识,希望对你有一定的参考价值。
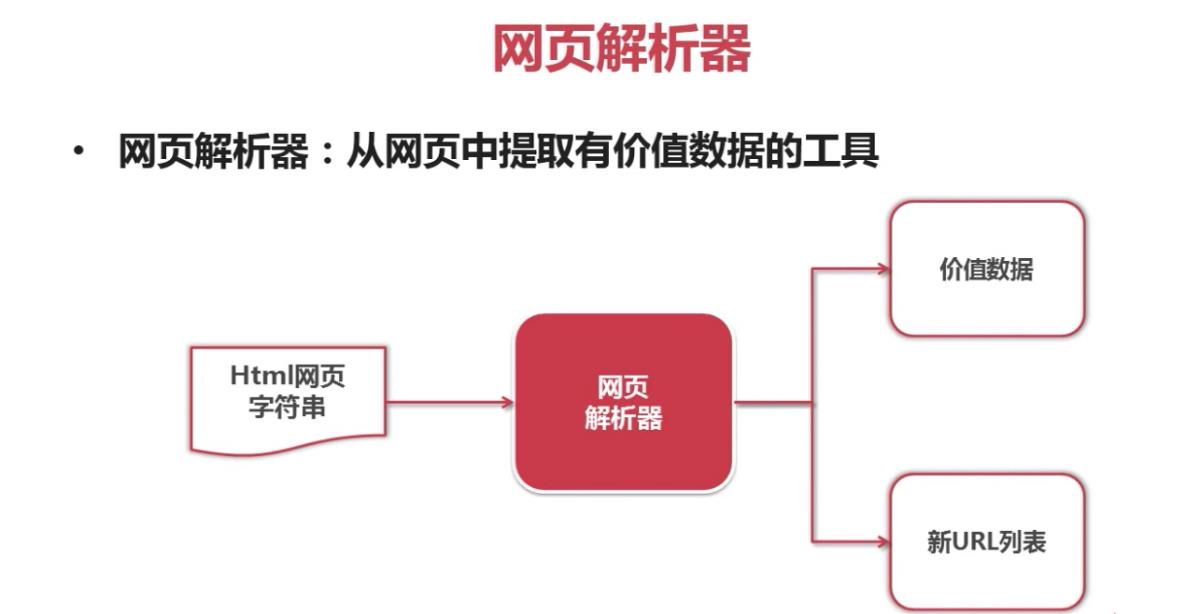
一、Python的网页解析器
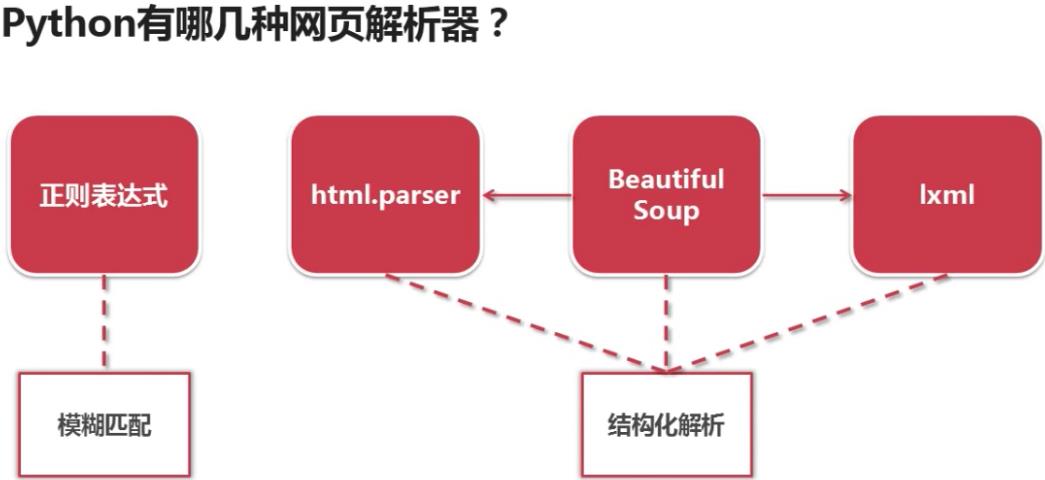
- 正则表达式:将整个网页文档当作字符串,然后使用模糊匹配的方式,来提取出有价值的数据和新的url
优点:看起来比较直观
缺点:若文档比较复杂,这种解析方式会显得很麻烦
2.html.parser:此为python自带的解析器
3.lxml:第三方插件解析器,可解析html和xml网页
4.Beautiful Soup:强大的第三方插件解析器,可使用html.parser和lxml解析器
其中正则表达式采用模糊匹配的表达方式;html.parser、lxml、Beautiful Soup采用结构化解析的方式
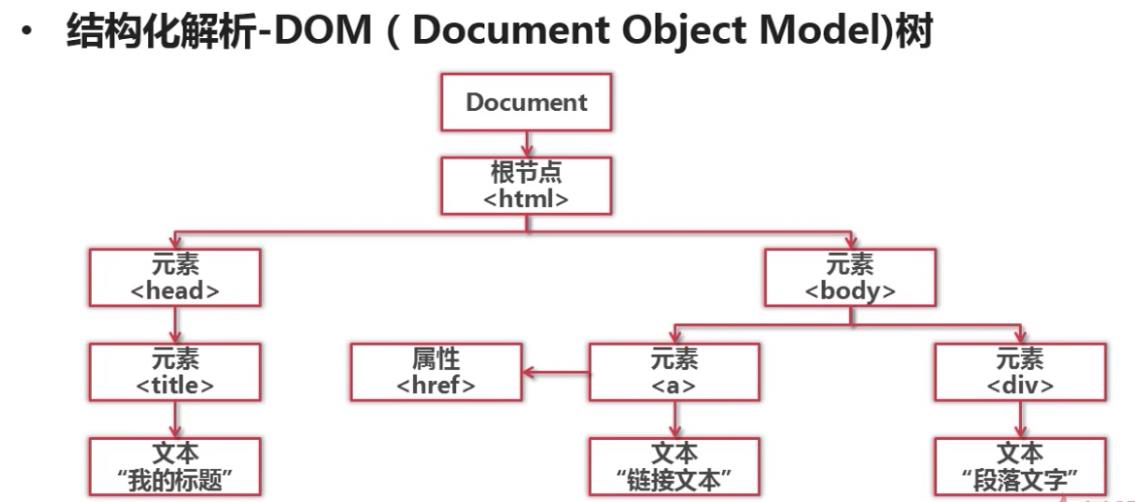
二、什么是结构化解析
将整个网页文档加载成一个DOM树,就是将文档转化为DOM树模型,以树的方式进行上下级的遍历和访问。
以上是关于爬虫学习——网页解释器简介的主要内容,如果未能解决你的问题,请参考以下文章