问答系统介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了问答系统介绍相关的知识,希望对你有一定的参考价值。
参考技术A 这是我的第一篇技术博客,也是对近期学习的问答系统进行一个小结,方便回顾所学。文章难免有错误之处,欢迎大家批评指正,不胜感激。下面将从两个方面对问答系统进行小结:
一、常见的问答系统种类及介绍
二、问答系统中的常用技术
1.根据问题所属的知识领域来分类:
(1) 开放域闲聊性。 举例:微软小冰
(2) 面向FAQ和任务型。举例:京东JIMI、苹果Siri
(3)限定域知识型。 举例:左手医生(问答模型、信息检索)
2.根据答案生成阶段的技术分类:
(1)检索式 (2)生成式
3.依据答案来源分类:
(1)基于知识图谱问答系统
(2)机器阅读理解的问答系统
(3)基于问答对的问答系统
定义:给定自然语言处理问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。对事实性问答任务而言(如政策问题)这种做法依赖于知识图谱,准确率比较高。要求知识图谱是比较大规模的,因为KB-QA无法给出在知识图谱之外的答案。下面给出常见分类:
(1)基于符号表示的KB-QA(传统的语义解析方法)
(2)基于向量表示的KB-QA(知识表示学习的方法)
评价标准:召回率(Recall)、精确率(Precision)、F1
常用数据集:WebQuestion、SimpleQuestion、NLPCC KBQA数据集(中文)
(1)基于符号表示的KB-QA(传统的语义解析方法)
定义:该方法是一种偏语言学的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式,通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句在知识库中进行查询,从而得出答案。
语义解析传统方法:
问题->短语检测->资源映射->语义组合->逻辑表达式
语义解析目前一般做法:
建图->主题词链接->确定核心推导链->增加约束和聚合函数
将语义解析简化为查询图生成,将其表述为具有分阶段状态和动作的搜索问题。
(2)基于向量表示的KB-QA(基于表示学习的方法)
定义:把知识库问答看做一个语义匹配过程。通过表示学习知识库以及用户问题的语义表示,得到低维空间的数值向量,再通过数值计算,直接匹配与用户问句语义最相似的答案。即问答任务就可以看成问句语义向量与知识库中实体、边的语义向量相似度计算的过程。
随着深度学习的发展,基于表示学习的知识库问答取得了较好的效果。
一般做法:
问题和答案映射向量->向量匹配->计算问题-答案score->优化问题->候选答案选择
详细过程:
问题和答案映射向量:
如何学习问题向量:把问题用LSTM进行建模
如何学习答案向量:答案不能简单映射成词向量,一般是利用到答案实体,答案类型,答案路径,答案关系,答案上下文信息。分别和问句向量做相似度计算,最终的相似度为几种相似度之和。代表性的论文 [1]Dong, ACL. Question answering over freebase with multi-column convolutional neural networks.2015提出Multi-column CNN,在答案端加入了更多信息,答案类型、答案路径以及答案周围的实体和关系三种特征向量分别和问句向量做相似度计算,最终的相似度为三种相似度之和。
向量匹配、计算问题-答案score:把这些特征分别映射成不同的向量,作为答案的其中一个向量(而不是直接拼接起来),最后用这些特征向量依次和问题做匹配,把score加起来作为总的score。
优化问题、候选答案选择:一般用Margin Loss,极大化问题对正确答案的score,同时极小化问题对错误答案的score。当模型训练完成后,通过score进行筛选,取最高分的作为最终答案。
早期方法使用记忆网络来做,论文:Bordes, arXiv. Large-scale simple question answering with memory networks.2015.首先通过Input模块来处理问题,加入知识库信息,将三元组通过输入模块变换为一条一条的记忆向量,再通过匹配主语获得候选记忆,进行cos匹配来获取最终记忆,将最终记忆中的宾语输出作为答案。在WebQuestions上得到了42.4的F1-score,在SimpleQuestions上得到了63.9的Accuracy。
接着,又有很多位学者提出了其他基于知识表示学习的方法。其中论文[Xie.2018]提出一种基于深度学习的主题实体抽取模型,结合了问句单词级别和字符级别的嵌入表示来学习问题的序列表示,并利用双向LSTM对单词序列编码,最后使用CNN网络根据单词的上下文信息预测单词是否为主题词。在答案选择部分,文章提出一种基于自注意力机制的深度语义表示模型。使用双向LSTM和CNN网络来构建深度语义模型,并提出一种基于局部和全局上下文的自注意力机制用于计算单词的注意力权重。考虑语义表示学习和实体抽取任务之间的具有相互辅助作用,文章提出深度融合模型,将基于自注意力机制的深度语义表示模型与主题实体抽取模型结合,用多任务学习的方式进行联合训练。在NLPCC-ICCPOL 2016数据集上得到了83.45的F1-score。
今年,Huang, WSDM. Knowledge graph embedding based question answering.2019 提出KEQA模型,不同于以往的直接计算问句和答案语义相似度的方法,本文尝试通过关系和实体学习模型从问句分别重构出实体和关系的知识表示,并进一步重构出三元组的知识表示,最终答案为知识库中与重构三元组最接近的三元组。同时文章也评估了不同的知识表示学习方法TransE,TransH, TransR对KEQA模型精度的影响。
1)基于符号的方法,缺点是需要大量的人工规则,构建难度相对较大。优点是通过规则可以回答更加复杂的问题,有较强的可解释性.
2)基于向量的方法,缺点是目前只能回答简单问题,可解释性差。优点是不需要人工规则,构建难度相对较小。
1)复杂问句,目前End2End的模型只能解决简单问答。
2)多源异构知识库问答。对于开放域问答,单一的知识库不能完全回答所有问题。
3)训练语料,知识库中有实体和关系,除此之外还可能有描述实体的文本信息,或许可以结合结构化知识和非结构化文本。
4)对话中的自然语言形式回复。传统的自动问答都是采用一问一答的形式。然而在很多场景下,需要提问者和系统进行多轮对话交互,实现问答过程。这时,需要系统返回用户的答案不再只是单一实体、概念、关系的形式,而是需要是以自然语言的形式返回答案。这就需要自动生成自然语言的回复。现有方法多利用 sequence-to-sequence 模型进行自然语言生成,在这一过程中,如何与知识库相结合,将知识库问答的答案加入自然语言回复中,仍是亟待解决的问题。
机器阅读理解在 NLP 领域近年来备受关注,自 2016 年 EMNLP 最佳数据集论文 SQuAD 发表后,各大企业院校都加入评测行列。利用机器阅读理解技术进行问答即是对非结构化文章进行阅读理解得到答案,可以分成匹配式QA,抽取式QA和生成式QA,目前绝大部分是抽取式QA。阅读理解花样很多,但是基本框架差异不大。
SQuAD(斯坦福问答数据集):这是一个阅读理解数据集,由众包人员基于一系列维基百科文章的提问和对应的答案构成,其中每个问题的答案是相关文章中的文本片段或区间。SQuAD 一共有 107,785 个问题,以及配套的 536 篇文章。
(1)匹配式QA
给定文章、问题和一个候选答案集(一般是实体或者单词),从候选答案中选一个score最高的作为答案。这种形式比较像选择题型,已经基本上没人做了。
(2)抽取式 QA
让用户输入若干篇非结构化文本及若干个问题,机器自动在阅读理解的基础上,在文本中自动寻找答案来回答用户的问题。抽取式 QA 的某个问题的答案肯定出现在某篇文章中。抽取式 QA 的经典数据集是 SQuAD。
(3)生成式QA
目前只有MSRA的MS MARCO数据集,针对这个数据集,答案形式是这样的:
1)答案完全在某篇原文
2)答案分别出现在多篇文章中
3)答案一部分出现在原文,一部分出现在问题中
4)答案的一部分出现在原文,另一部分是生成的新词
5)答案完全不在原文出现(Yes / No 类型)
随着互联网技术的成熟和普及, 网络上出现了常问问题(frequent asked questions, FAQ)数据, 特别是在 2005 年末以来大量 的社区问答(community based question answering, CQA)数据(例如 Yahoo!Answer)出现在网络上, 即有了大量的问题答案对数据, 问答系统进入了开放领域、基于问题答案对时期。
一般过程:问题分析 ->信息检索->答案抽取
问题分析阶段:和基于自由文本的问答系统的问题分析部分基本一样, 不过还多了几个不同的研究点:
(1)问题主客观的判断
(2)问题的紧急性(通常在CQA数据中)
信息检索阶段:该阶段目标是如何根据问题的分析结果去缩小答案 可能存在的范围,其中存在两个关键问题:
(1)检索模型(找到和问题类似的问题)
(2)两个问题相似性判断(返回答案或返回相似问题列表)
答案抽取部分:在答案抽取部分, 由于问题答案对已经有了答案, 答案抽取最重要的工作就是判断答案的质量.研究怎么从问题的众多答案中选择一个最好的答案.
下面网址给出了一些论文和近期研究成果:
https://blog.csdn.net/class_guy/article/details/81535287
参考文献:
[1]Berant.EMNLP.Semantic parsing on freebase from question-answer pairs.2013
[2]Yih.ACL.Semantic Parsing via Staged Query Graph Generation:Question Answering with Knowledge Base.2015
[3]Dong, ACL. Question answering over freebase with multi-column convolutional neural networks.2015
[4]Hao, ACL. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge.
[5]Bordes, arXiv. Large-scale simple question answering with memory networks.2015
[6]Huang, WSDM. Knowledge graph embedding based question answering.2019
[8]Susht.知乎.一份关于问答系统的小结.2018
计算机毕业设计之SpringBoot智能问答平台系统 智能客服平台系统
介绍
针对某高校招生咨询常见的一些业务提问,设计一个基于自动问答系统。用户可以用普通的问句对自动问答系统提问,自动问答系统将从知识库或者互联网中搜索相应的答案,然后把答案直接返回给用户,使用语言为中文。可以快速改造为其他类型的问答系统。
软件架构
springboot mybatis mysql DWR技术
开源地址
https://gitee.com/bysj2021/wenda
功能介绍
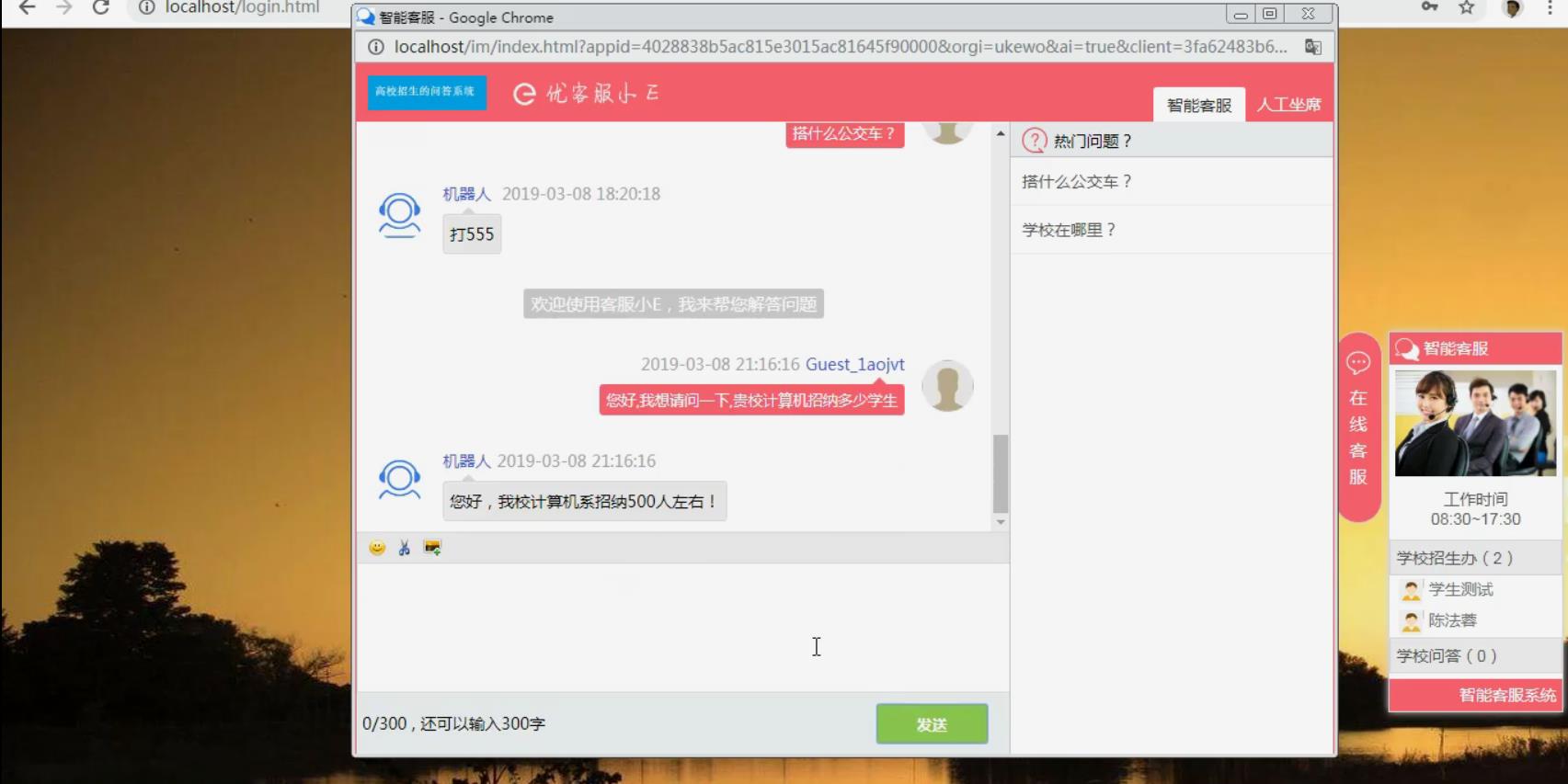
1.实现自动回答模块:
本系统实现对输入问题的自动回答,即根据用户输入问题,系统能自动搜索问答库,返回较合适的回答给用户。
2.实现后台数据库可视化操作模块:
本系统需要有强大的问答库支持,在不断完善问答库规模的同时,需要实现对问题库、回答库和关键词库等数据库的可视化管理,方便用户进行查询、添加、 删除和更新操作。
3.用户管理模块:
系统所有用户角色的管理,要有不同的角色和权限
4.数据库导出导入功能:
实现数据库中数据的批量导入导出功能。
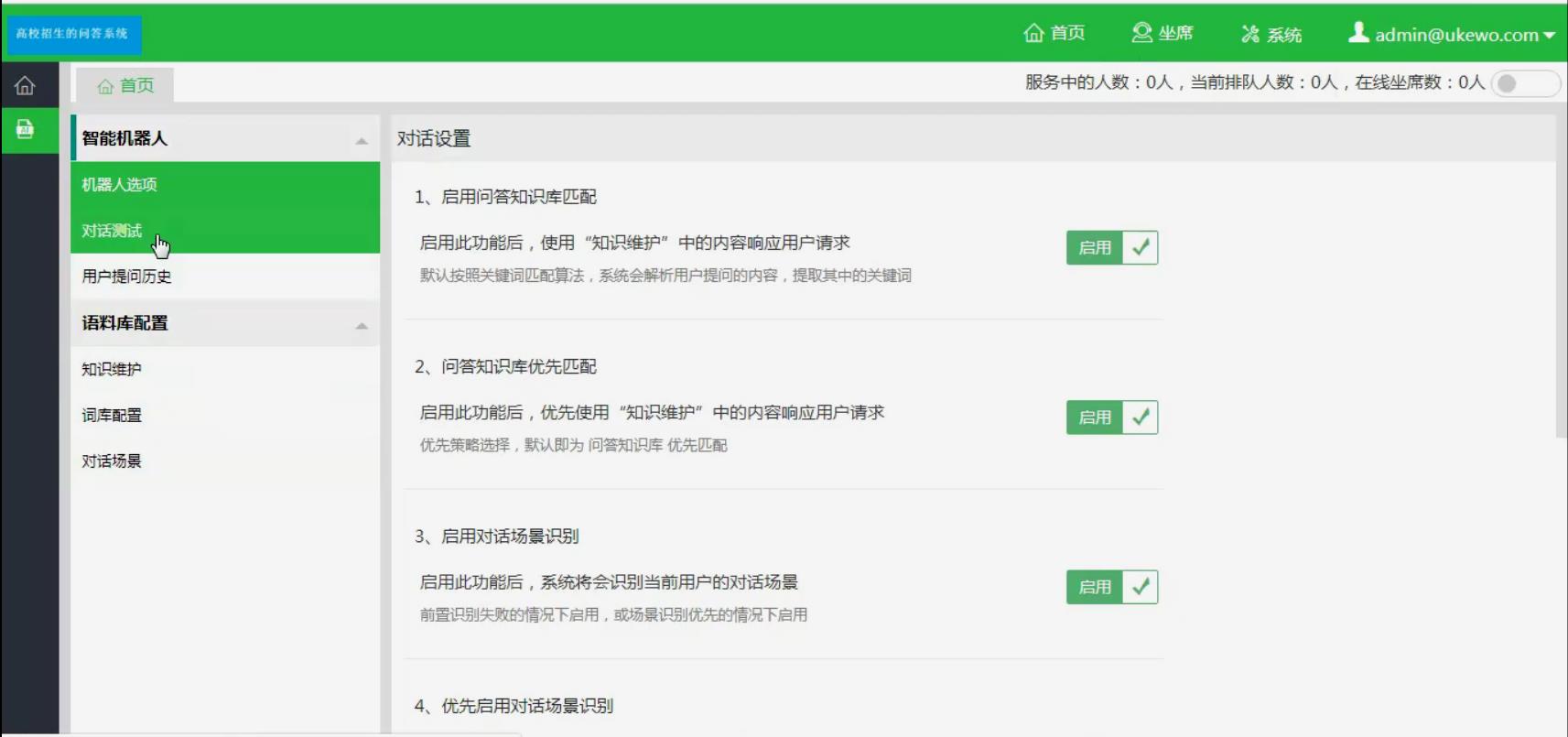
5.参数设置:
在系统主界面中,实现相关参数的设置。参数设置包括针对某些常见问题的 回答设置,屏蔽一些不友好用户。
6.词库构建:
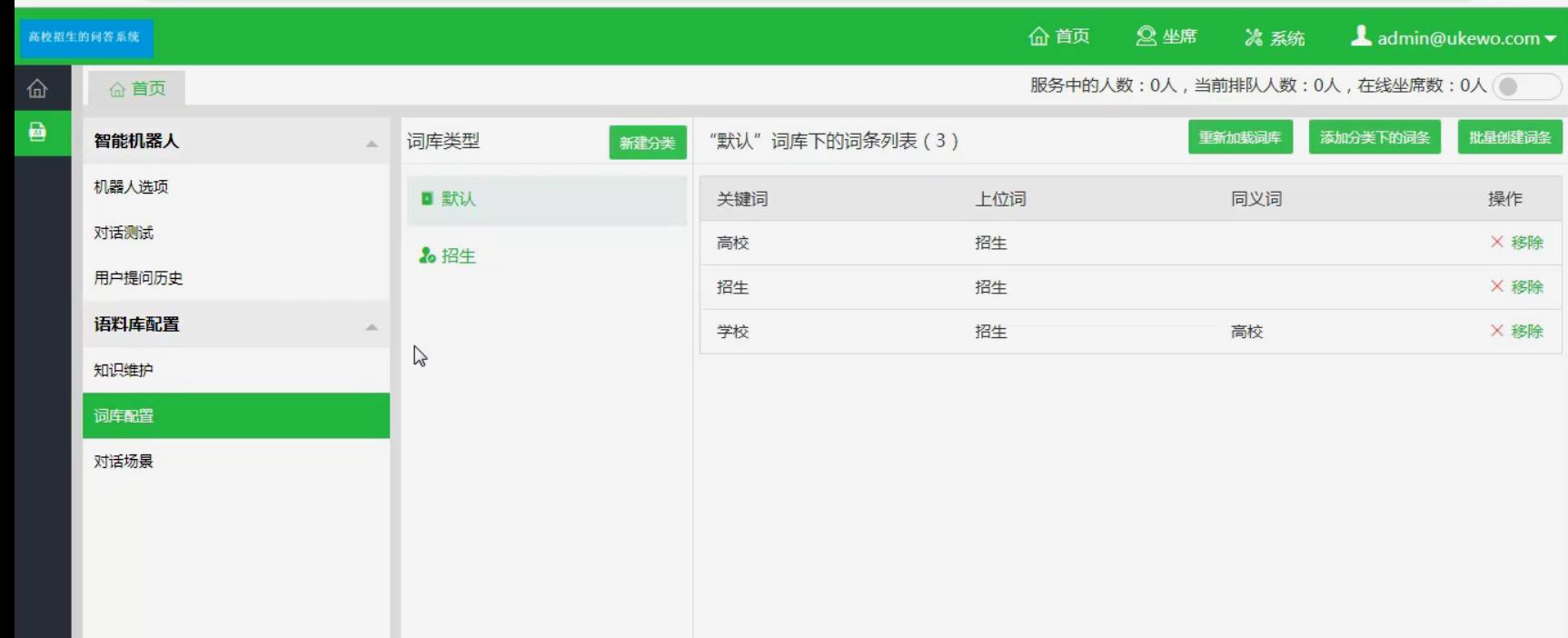
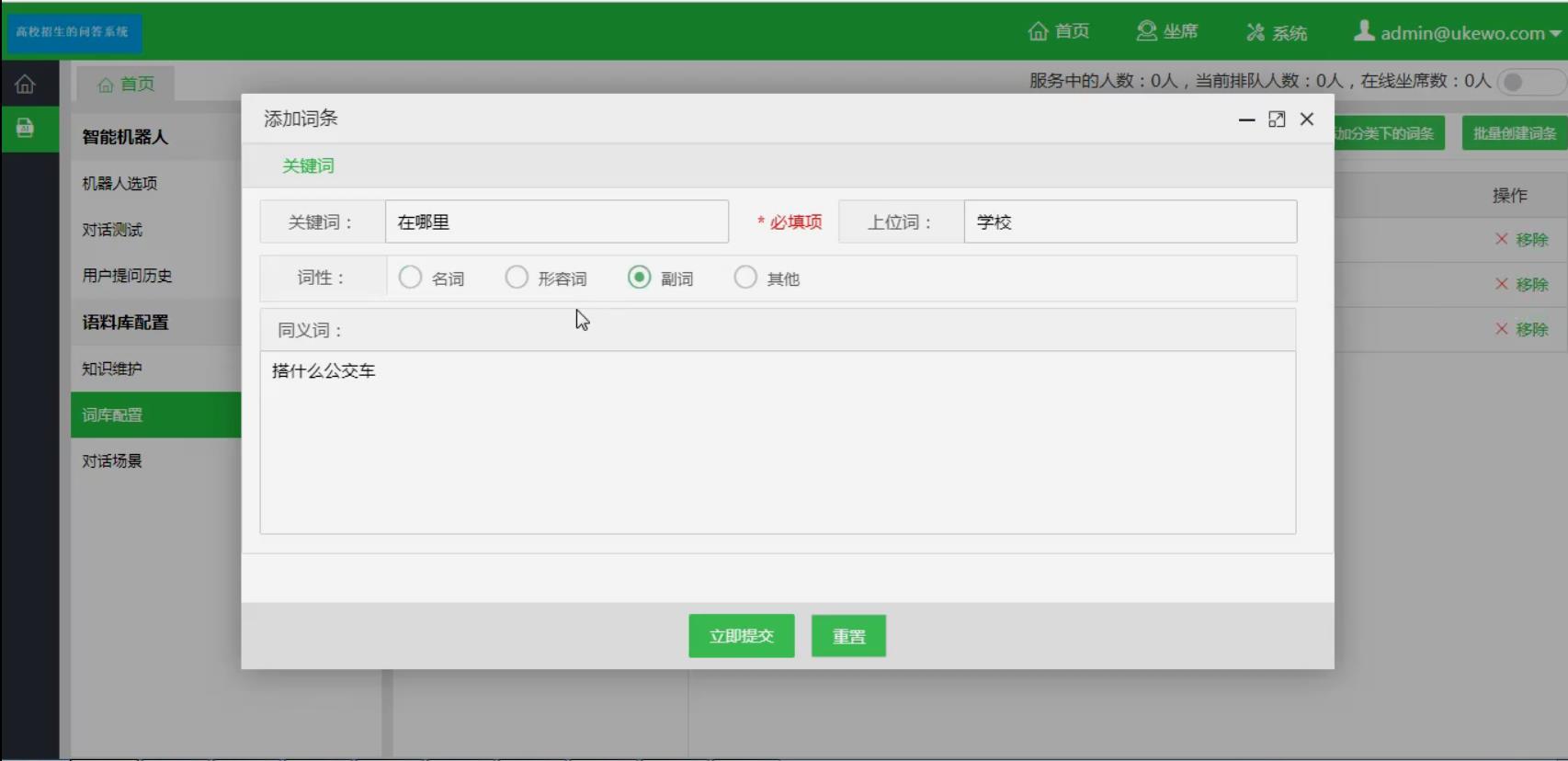
构建适用聊天环境的专门词汇库,结合现在的词汇库,确保系统回答的准确性。
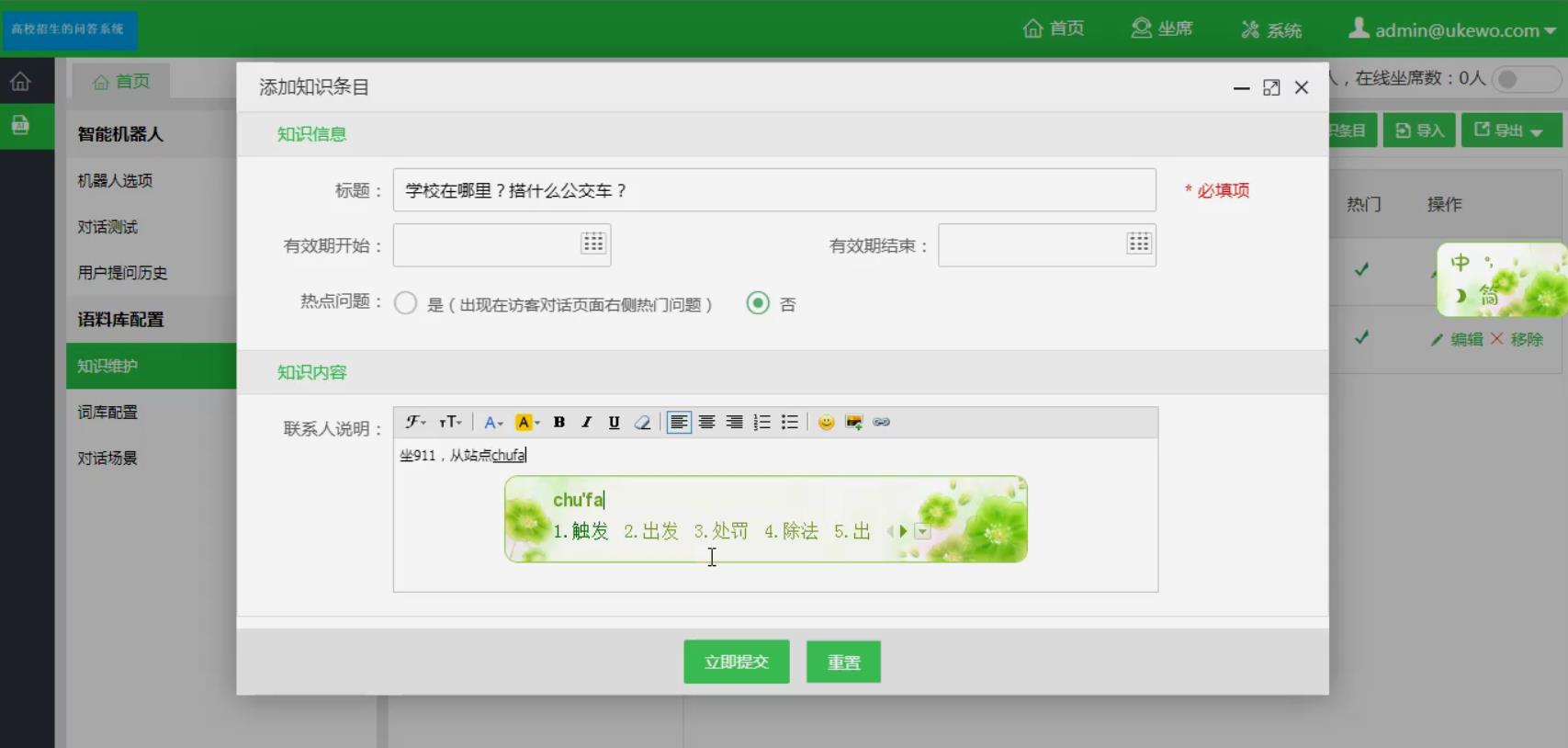
7.多分句回复:
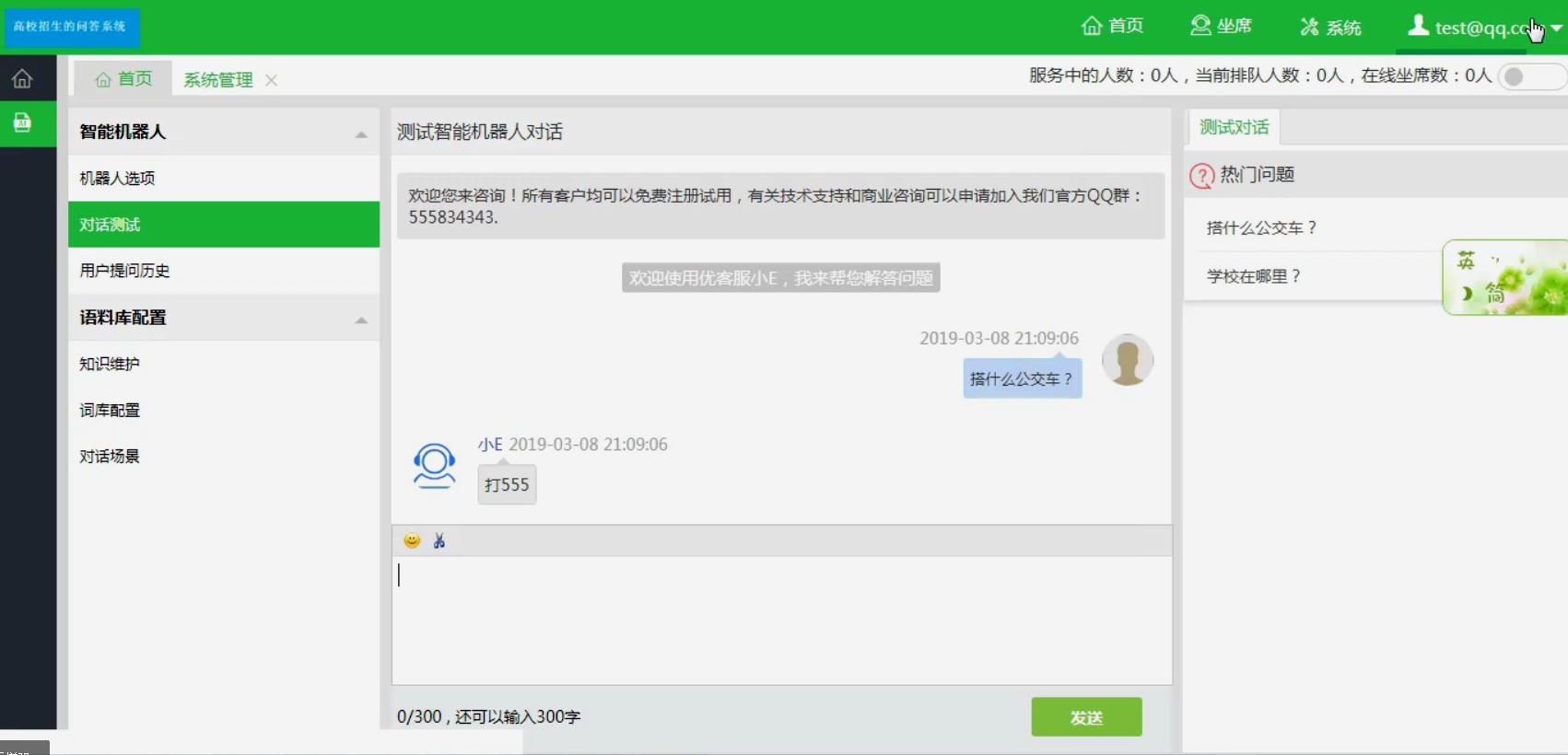
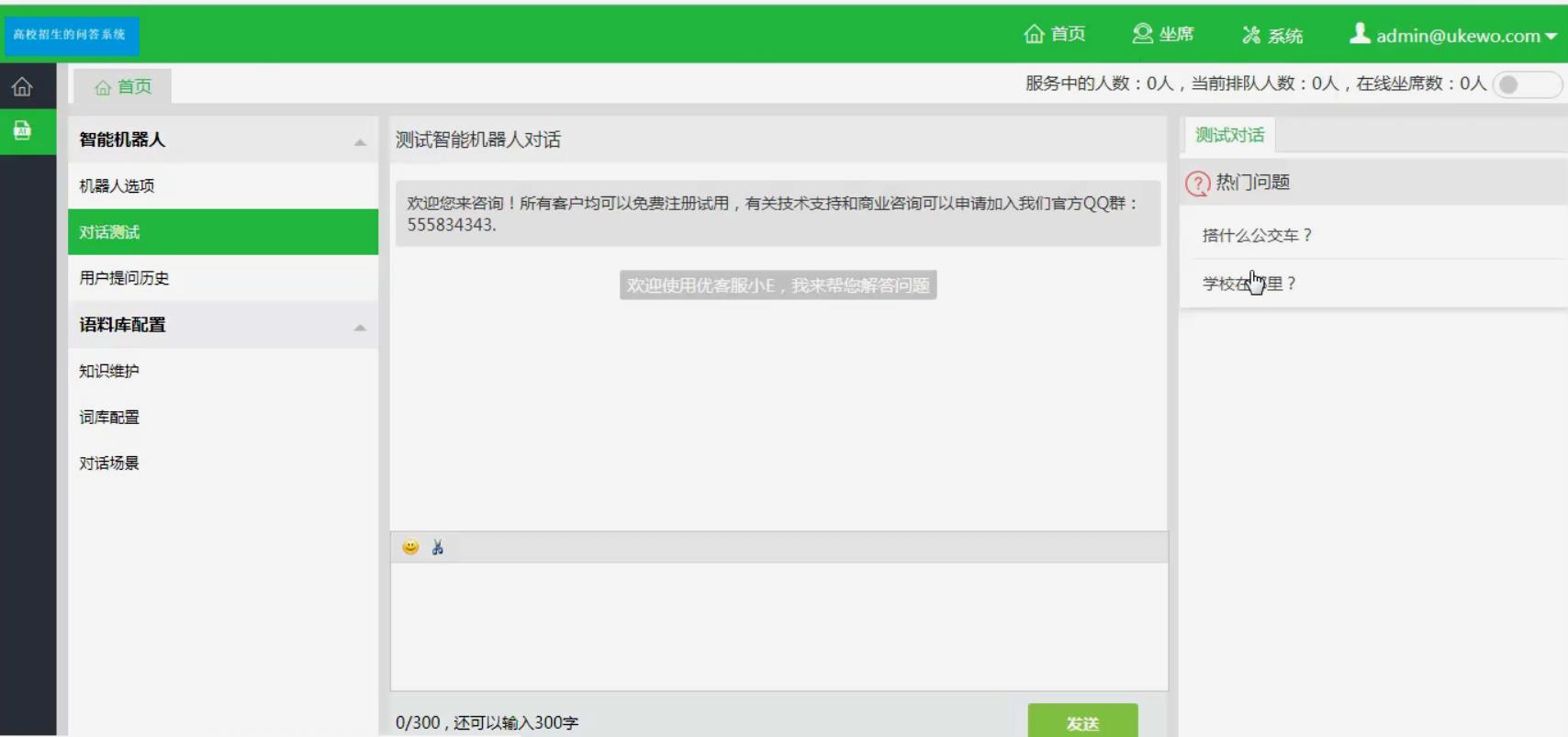
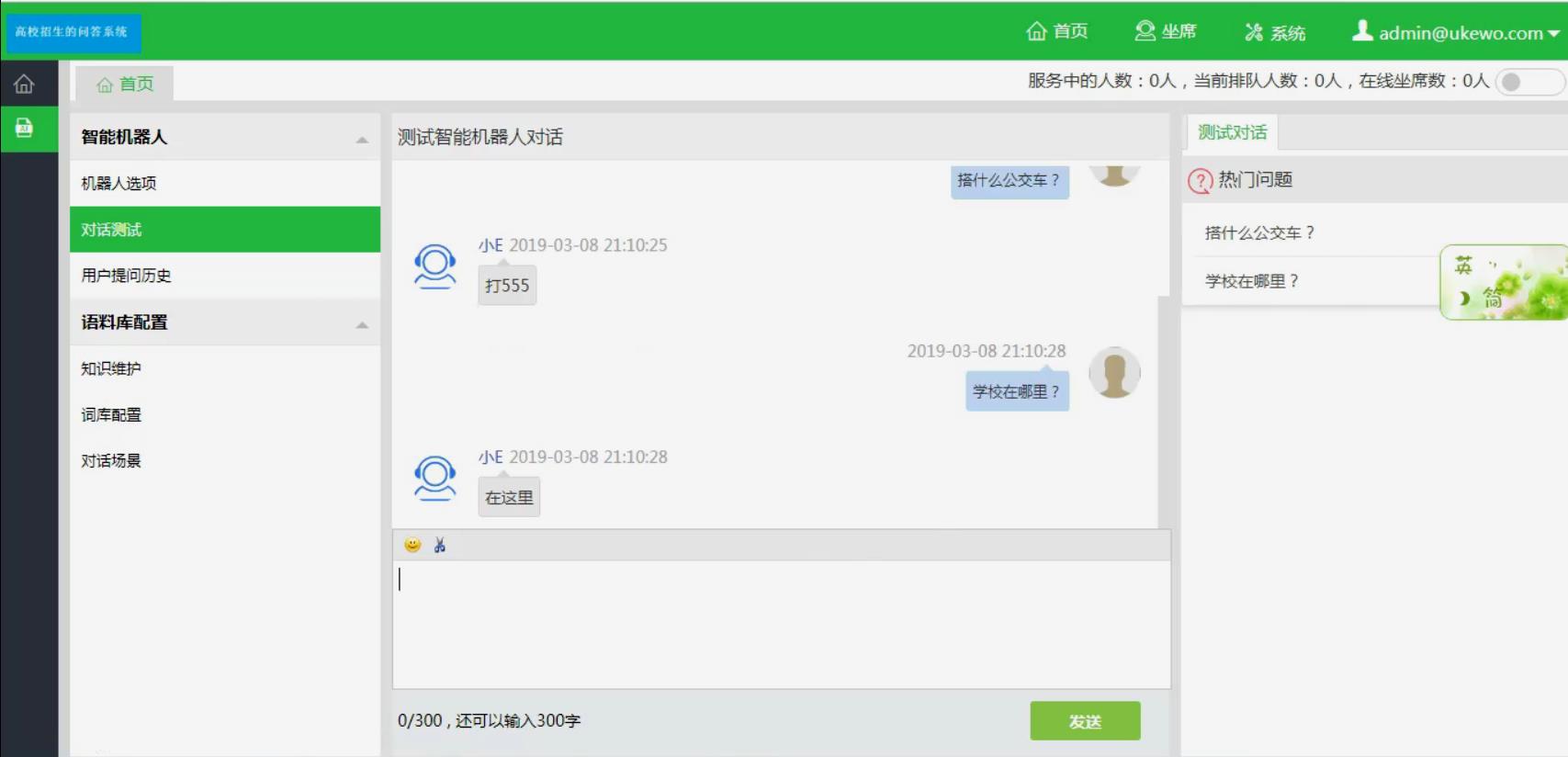
实现对多分句问话的回复。在实际的问答环境中,一条问答记录包含有多个分句,它们可能包含各自的问题,如:“学校在哪里?搭什么公交车?”能进行2个问题均能识别并回答。
8.相似度小于阀值通路的处理:
对相似度值小于阀值的处理。建立一个默认回答表,如果在问题库中找不到相似度值大于阀值的句子,就从该表中随机选取一个句子作为回复返回,应具备添加、删除的默认回答表的功能。
9.记录导出功能:
能将记录输入的问答文本和产生的回复到一个文本文件中,以备做机器学习的样本。
10.问题统计管理:
可自动统计用户关注信息,并做图表显示。
选做:可以考虑通过机器学习做成具备一定AI的形式。
运行截图
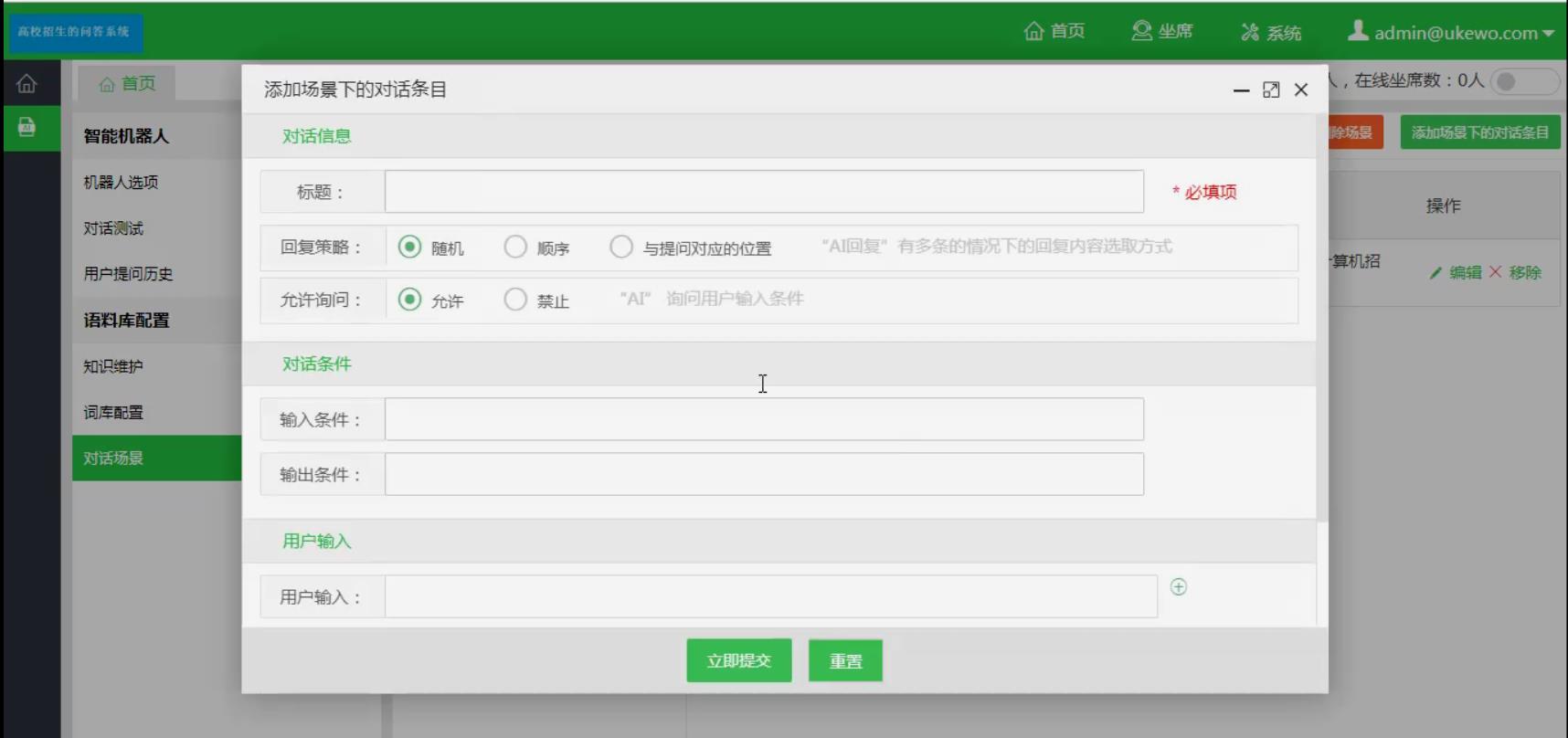
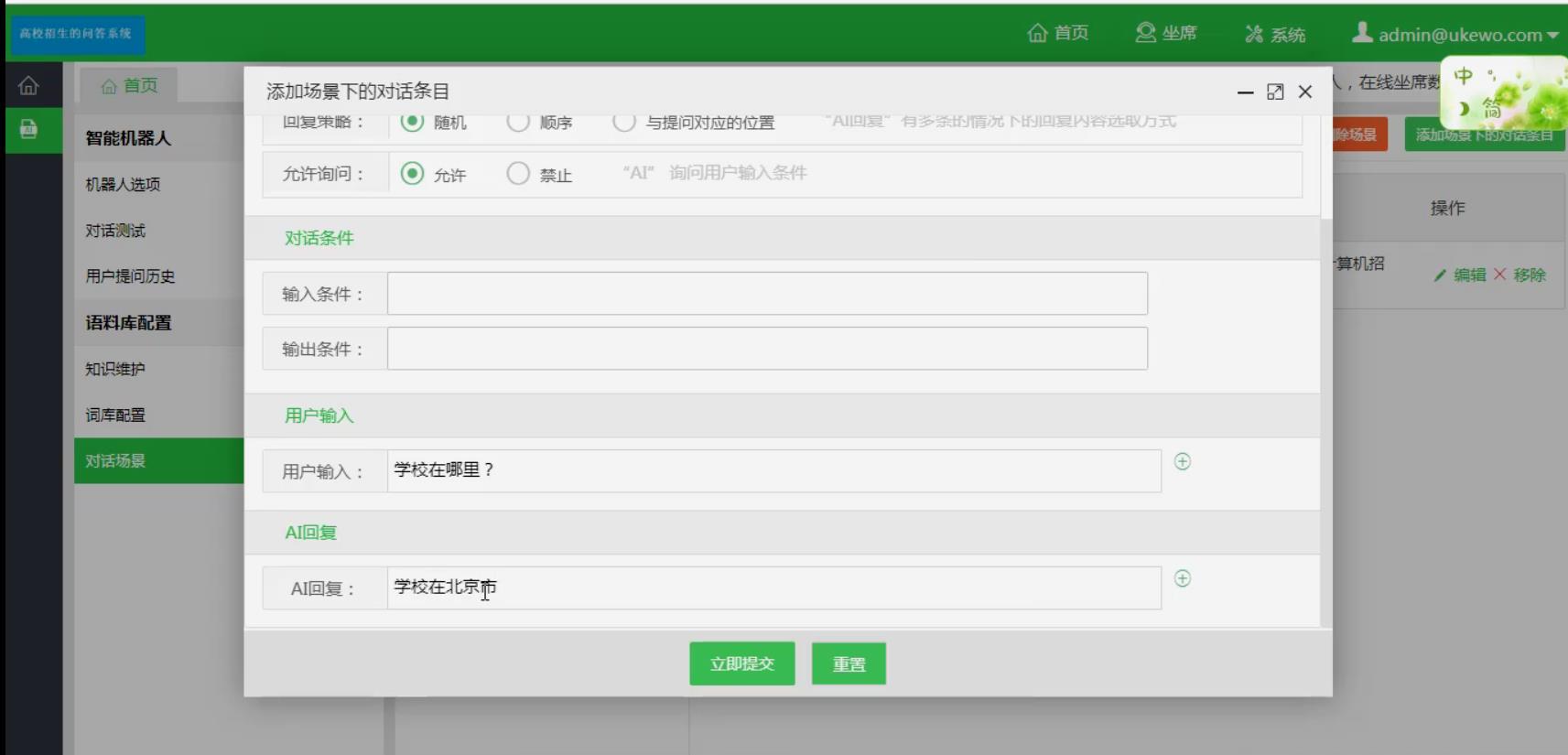
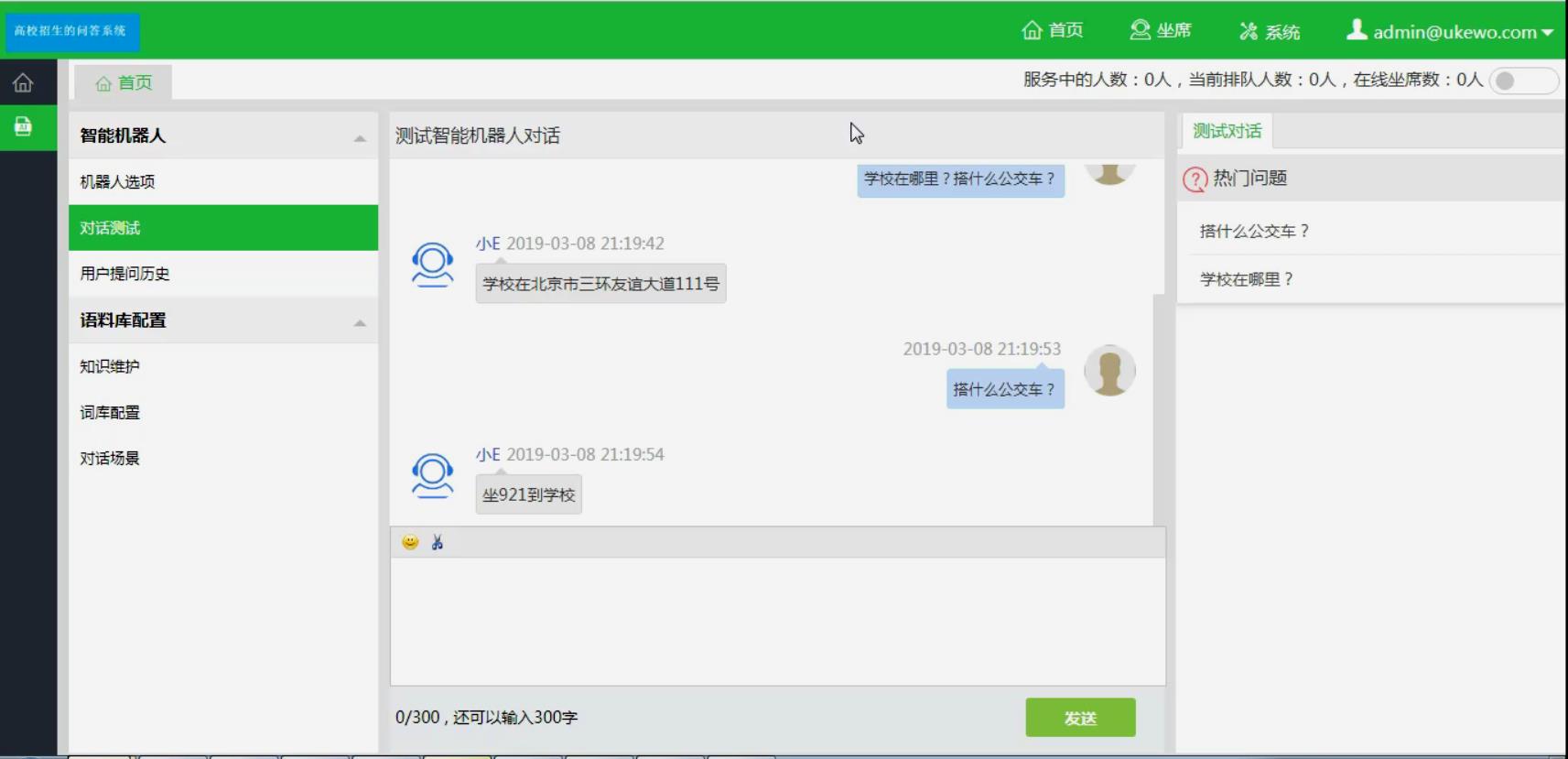
以上是关于问答系统介绍的主要内容,如果未能解决你的问题,请参考以下文章