哈希表之一初步原理了解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希表之一初步原理了解相关的知识,希望对你有一定的参考价值。
考虑如下场景:小明住在芳华小区,芳华小区中有很多幢房子,每个房子有十几二十层,每层有4个住户;
现在小红要去找小明玩耍,现在假设小红只知道小明住在芳华小区,但是不知道住在哪一幢,哪一层和哪一户,】、
那么小红要怎么才能找到小明呢?
那么毫无疑问,小红只有在芳华小区中一家一家地敲门问小明住在哪儿?
(此时不允许小红叫一个收破烂的拿着喇叭在楼下喊:"小明,额想你!")
这个时候,如果小红有芳华小区的所有住户的明细的话,就可以从明细上找到小明住的地方,然后根据这个地方在芳华小区中找到小明,
而不需要敲遍小区所有住户的门。
同样,现在内存中有一数组,我们需要判断在数据中是否存在某个元素的时候,如果没有其他额外的信息,唯一的办法就是遍历这个数组,
因为这个时候我们只有这个这个数组的下标可用。
那么联想到上面小红找小明的例子,其实有类似之处,数组中的元素和下标现在是没什么联系的;不能根据元素值来定位到元素如果存在
在数组中的时候应该在哪个位置,要是我们想小红一样,也有一个"住户的明细"的话,任意给一个元素,我们根据元素的值找到其对应
在数组中的下标的值,然后直接根据这个下标的值直接去访问数组,便可以知道这个元素是否存在了。
现在出现了两个需要注意的东西:
(1)"住户的明细"
(2)找到
"住户的明细"其实从数学上来说可以看做一个对应关系,一个映射,也就是现在要讨论的哈希表。这个表记录了元素和其在数组中下标的
对应关系,待会我们就会对某个数组做一张这样的表;
"找到",其实就是根据元素的值计算出其在数组中的下标(位置)。
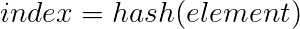
哈希表中有个两需要解决的问题:
(1)找到一个尽可能将元素分散的放到数组中去,不要让不同的元素都分到同一个位置去了
(2)万一确实通过hash函数计算之后分到了同一个地方,我们得有相应的措施来处理这种情况
现在有如下几个数:1,2,4,5,7,8,10,11;现在为了方便查找,我们可以这样放
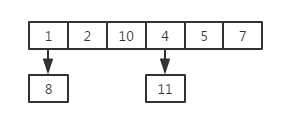
这里的数据放置的规则很简单:
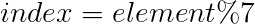
1%7=1,放到数组的第1个位置;
2%7=2,放到数组的第2个位置;
......
11%7=4,放到数组的第4个位置;
这里元素的值对7求余就是所选择的hash函数。如果我们要找数组中是否存在某个数x,可以用x%7求得一个数,
这个数就是在这个数组中应该存在的位置,此时直接通过这个位置定位数组中的这个元素,就可以很快的判断这个数在数组中
存不存,而不需要一个一个遍历数组。
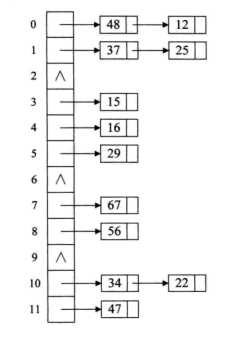
图中可以看到1和8对7求余的余数是相同的,导致了它们被放到了同一个位置上,这就是属于冲突的情况。
哈希表中解决冲突的情况有两种方法:
一种方法就是如果冲突了的话就纵向的添加冲突的元素,如图中那样,先用hash算出元素应该出现的坑,然后在通过链表进行普通查找;
另一种方法就是继续横向的添加,具体怎么添加还没摸清楚~,反正hash基本原理就是这样的。
哈希表的如果建的好的话,查找元素的时间复杂度是O(n)哦,典型的时间换取空间。
有助于理解的图:
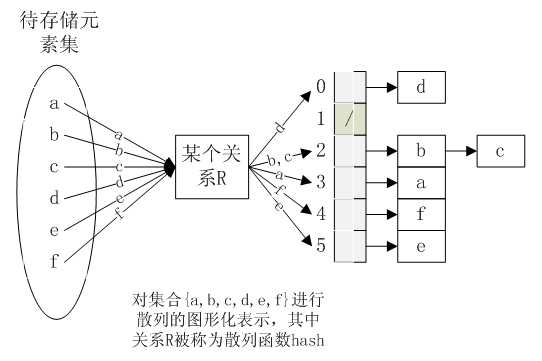
下面用C来写一个简单的hash表:
1 #include<stdio.h> 2 #include<stdlib.h> 3 4 #define LIST_LENGTH 100 5 6 typedef struct Item Item; 7 8 struct Item { // 用链表来解决冲突 9 int value; 10 int index; 11 Item * next; 12 }; 13 14 typedef struct List { 15 Item *head; 16 Item *end; 17 } List; 18 19 void insertItem(List *list, Item *item) { 20 21 int key = (unsigned int)(item->value) % LIST_LENGTH; // 键的计算方法 22 // 判断list中是否存在元素 23 if(!list[key].head) { // 这个槽之前没有元素 24 list[key].head = item; 25 list[key].end = item; 26 } else { // 已经有元素放到了这个位置 27 list[key].end->next = item; 28 list[key].end = item; 29 } 30 } 31 32 int searchValue(List *list, int value) { 33 // 计算出元素的键值 34 int key = (unsigned int)(value) % LIST_LENGTH; 35 Item *p = list[key].head; 36 37 while(p) { 38 if(value == p->value) { 39 return p->index+1; // 万一元素在数组中的索引就是在0处, 直接返回0的话和后面返回的0冲突了 40 } 41 p = p->next; 42 } 43 return 0; 44 } 45 46 int main(void) { 47 48 int array[] = {2, 3, 5, 7, 8, 9, -3, -8, 22, 13}; 49 int num = 10; // 数组元素的个数 50 int i = 0; 51 List list[LIST_LENGTH]; // 直接分配了这么一个结构体数组存放链表和key的对应关系 52 memset(list, 0, sizeof(List) * LIST_LENGTH); 53 54 Item item[10]; // 直接分配了一个结构体数组存放元素 55 memset(item, 0, sizeof(Item) * num); 56 57 // 遍历数组, 先将元素组装为一个结构体元素, 你可以看做面向对象编程中的对象 58 for(i=0; i<num; i++) { 59 item[i].value = array[i]; 60 item[i].index = i; 61 insertItem(list, &item[i]); // 把对象的引用放到hash表中 62 } 63 64 int test_arr[] = {-34, 2, 5, 42, -32, 12, 6, -8}; 65 int num2 = 8; 66 67 printf("数组元素为:"); 68 for(i=0; i<num; i++) { 69 printf("%d ", array[i]); 70 } 71 printf("\\n"); 72 printf("测试数组元素为:"); 73 for(i=0; i<num2; i++) { 74 printf("%d ", test_arr[i]); 75 } 76 printf("\\n\\n"); 77 78 for(i=0; i<num2; i++) { 79 int position = searchValue(list, test_arr[i]); 80 if(position) { 81 printf("数组array中存在元素%d, 下标为%d\\n", test_arr[i], position-1); 82 } else { 83 printf("数组array中不存在元素%d\\n", test_arr[i]); 84 } 85 } 86 87 return 0; 88 }
后续会关注的有:
1. 哈希表的变种,不过目前也就知道又一个一致性hash,这个实在memcached这个缓存框架中会用到;
2. java中其实已经实现了哈希表这种数据结构,用起来很方便,到时候可以跟一下源码;
3. java中的equals方法和hashcode方法的关系是什么样的,以及这两个方法应该如何去写才比较好;
以上是关于哈希表之一初步原理了解的主要内容,如果未能解决你的问题,请参考以下文章