FlowPaper中文PDF乱码的一种解决办法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlowPaper中文PDF乱码的一种解决办法相关的知识,希望对你有一定的参考价值。
[关键词]FlowPaper、PDF.js、乱码
[结论]先给出解决办法,后面的大段内容只是为了记录当时的排查过程。
PDF.js有全局变量对象PDFJS(1.8以上版本在pdf.js最后,1.5.x的版本没找到,在代码取值地方设置也可,下有说明),可以设置字体资源路径和方式(关于字体资源的说明可看此贴https://stackoverflow.com/questions/32764773/what-is-a-pdf-bcmap-file),如果采用默认不设置就可能会出现找不到资源文件乱码的情况,可根据自己项目路径写定配置路径即可。
背景:
需要对PDF进行在线展示,为了能够操作编辑不选择swf格式,而是将PDF转为html5,用到了FlowPaper(免费版)。
大部分PDF没有问题,但少量PDF出现了中文乱码情况,如下图所示:
中文都不显示,或显示为方块
图1:

图2:
由于FlowPaper底层PDF to HTML用的也是开源组件PDF.js(https://mozilla.github.io/pdf.js/),在PDF.js官方demo上测试,本来乱码的PDF是正常的,先排除了PDF本身问题(其实PDF文本也可能有原因,内置字体、版本号等,但是由于有不乱码的情况,先忽略),开始进行排查。
排查:
首先怀疑是版本问题,FlowPaper内置的是1.5.x的PDF.js,PDF.js官网最新版是1.8.xx,在线测试确实无问题,遂考虑覆盖FlowPaper内的PDF.js(FlowPaper的js压缩过,文件名改为pdf.min.js和pdf.worker.min.js)。
这里说明一下,PDF.js官网下载到的发行版zip包括两个文件夹[build]和[web],其中web内是演示程序,build内是核心js文件,两个文件夹一起放到tomcat下访问web/viewer.html即可上传PDF测试功能了。
直接替换后,FlowPaer运行正常,英文和一些中文pdf可以正常显示,说明核心功能没变化,开源的东西主要就怕版本迭代后兼容性不好,测试会乱码的pdf,在开发工具控制台可以看到如下错误:
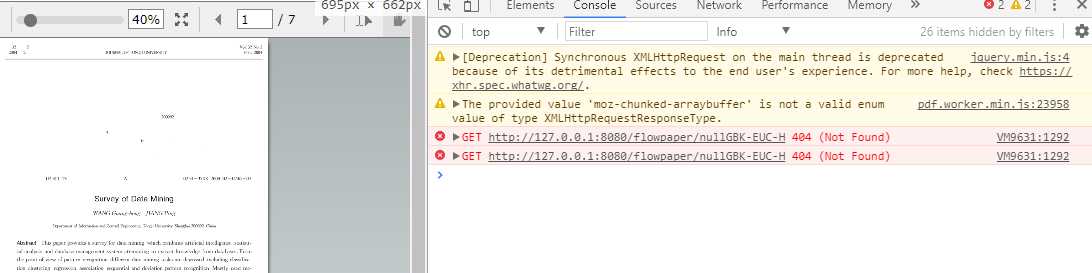
有点眉目,这个链接是不存在的肯定请求不到,检查对应的js代码,发现null是url的变量,GBK-EUC-H就是字体资源文件夹下的一个文件,感觉有戏,遂想到用偷懒的办法,在这里手工指定url和字体资源cmaps文件夹路径,让它请求到正确的地址不就好了……
验证确实有效,虽然没搞明白机制,但是项目里这个路径肯定是不变的,能用就好了,还要忙着写招标需求,赶紧发给项目组同事完事。
新问题
那边在项目集成里验证也可以,正觉得没事了,结果没一会儿报过来,原来不管乱码与否是可以选择高亮的,现在虽然不乱码了,但是选择高亮的功能不好使了,所有的文字均无法选择……

如上图所示,这个还是必须要的功能,真头大,于是重新打开tomcat和编辑器检查。
果然在本地纯HTML环境下也是不能用,但是这个功能已经在FlowPaper的js里了,又是大几万行js,看见几行js就头晕,这动辄就上万代码连个注释都没有……算了,冷静想想,可能是PDF.js 1.5.x的版本有什么函数变了?那干脆换回1.5的版本,在那个上面调试一下,估计也是字体资源路径的问题。
这里又遇到一个坑,FlowPaper带的js是压缩过的,用还原工具格式化还原后,发现不仅仅是压缩,连变量名都给混淆了,大量的函数a,函数b,变量a、b、c……好吧FlowPaper是商业软件,但你用了开源PDF.js的东西虽然不用开源,这部分代码没必要混淆了吧。
为了改的方便,既然知道了明确的版本号,直接去PDF.js官网的git上从历史版本里找到这个版本拿下来,然后覆盖上去,这样总没问题了吧?
结果又意外了,同样版本覆盖上去竟然不好使……这是什么情况?拿文本比对工具比对了一下,发现差异还真大,主要是结构都不一致了,也看不出来哪里不同了,只能把官方的源码作为阅读参照,直接在混淆代码上修改。
但是混淆代码也有问题,1.5和1.8的差异也不小,在1.8里pdf.js里的函数和赋值地方,在1.5的pdf.js里根本没有,但在pdf.worker.js里有一段逻辑是这个意思,但尝试修改之后,引发了新的问题,另外一段函数取值超限了,而那段自定义的超限函数,根本看不懂……
按照这个思路,越改需要修改的地方越多,而且本身这个也是个错误的思路,虽然想最偷懒的方式硬编码去解决,但是破坏代码原有的函数逻辑肯定是不对的。
又调了半天,文档还没进展,已经准备在QQ里给同事留言先不管了,现在用的是免费版,让他们去用收费版找厂商吧。
解决
正准备放弃,忽然想到搞了半天,cmaps下的一大堆bcmap文件到底是啥,虽然靠猜就知道和字体、编码相关,但以前确实没见过,google一下也算知其所以。结果就是这一查,彻底解决了问题。
stackoverflow上有人对这个文件也有疑问,提问了一下,虽然只有一个人回答,但回复的很详尽,也完全解决了这个问题 https://stackoverflow.com/questions/32764773/what-is-a-pdf-bcmap-file
看到里面说有默认全局设置和路径,眼前一亮,现在遇到的问题不正是资源路径的问题么,js打印出来的路径不对,那如果配置上默认路径,是不是就可以了?
1.8里有PDFJS这个全局变量,1.5版本里也有,但是没有这个属性,于是在代码中找到读取配置赋值的地方(这下这里写定值没问题了,本来就是固定配置),保存,刷新,测试,搞定!
原来PDF.js提供的demo里是设置了默认路径的,但是单纯只提取js文件到FlowPaper下是没有这个设置的,而且FlowPaper也没有带字体资源文件(免费版肯定没有),所以虽然一开始发现字体资源文件我就把文件夹放到了FlowPaper下,但是以为js里是通过相对路径来获取的。
简单的总结:
1.FlowPaper免费版没有带字体资源文件,以及pdf.js的版本较低,某些中文编码的pdf文件会出现乱码
2.开源的程序可能文档比较繁琐,或者都是英文的,但如果不去大体了解下机制,单纯从代码层面去乱试必然事倍功半
3.在没处理这个问题之前,同事想当然的认为是FlowPaper的bug,还发邮件去给开发团队询问(由于是免费版本对方当然不搭理),很多时候开发人员出问题都会先想到是bug,但更多要从自己是否使用正确入手来排查才行(虽然开源的系统bug会不少,但是稳定到一定版本之后随便就能碰到bug的几率还是少的,甚至还遇到一些同事开发中遇到问题直接指向说这个.Net Framworks有bug,这个JDK有bug,这也是属于迷之自信了,不如按下心来排查自己的问题,往往都能解决)
以上是关于FlowPaper中文PDF乱码的一种解决办法的主要内容,如果未能解决你的问题,请参考以下文章
python中matplotlib中标签中文乱码的一种解决方法
python中matplotlib中标签中文乱码的一种解决方法