LinkedHashMap:我还能实现LRU
Posted 张英爱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinkedHashMap:我还能实现LRU相关的知识,希望对你有一定的参考价值。
众所周知,LinkedHashMap继承自HashMap,在原先的HashMap的基础上,它增加了Entry的双向链接。
有意思的是基于这种实现特性,LinkedHashMap 在迭代遍历时,取得键值对的顺序的依据是其插入次序或者是最近最少使用(LRU)的次序。
LRU算法根据数据的历史访问记录来淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”,从而实现在定量缓存空间下缓存内容的管理,常用于浏览器和移动端各应用等本地缓存管理。
通过access方式创建LinkedHashMap即可实现基本的LRU算法,可看源码中LinkedHashMap的构造函数:

/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
查看源码可知,其中LinkedHashMap的取得键值对的顺序是由其构造函数中传入的第三个参数accessOrder决定,当其为false时,即为选用插入次序;为true时,即为选用LRU的次序。
而在我们利用LinkedHashMap实现LRU的关键在于重写下面这个方法
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
下面我就使用LinkedHashMap实现LRU做了两个test。
第一个test的目的是为了验证LinkedHashMap实现LRU的可行性,即其根据访问时间来管理内部元素的排序,具体实现如下:
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
Map<Integer,Integer> map = new LinkedHashMap<>(16,0.75f,true);
for(int i=0;i<16;i++)
map.put(i, i);
for(Iterator<Map.Entry<Integer, Integer>> iterator=map.entrySet().iterator();iterator.hasNext();) {
System.out.print(iterator.next().getKey()+" ");
}
System.out.println();
map.get(5);
for(Iterator<Map.Entry<Integer, Integer>> iterator=map.entrySet().iterator();iterator.hasNext();) {
System.out.print(iterator.next().getKey()+" ");
}
}
}
输出情况如下:
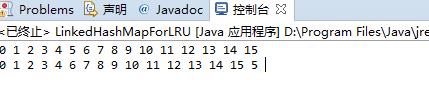
可见访问过的5确实被放到链表的末尾。
第二个test即是一个简单的实现LRU功能的LinkedHashMap,直接贴代码:
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
class LRULinkedHashMap<K,V> extends LinkedHashMap<K,V>{
private int capacity;
private static final long serialVersionUID=1L;
/**
* LRULinkedHashMap的含参构造器
* @param capacity 指定的缓存最大容量
*/
LRULinkedHashMap(int capacity){
super(16,0.75f,true);
this.capacity=capacity;
}
@Override
/**
* 当map中存储元素大于了最大缓存容量时,删除链表顶端元素即最近最少使用元素。
* 输出当前最少使用的元素的键值对
*/
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// TODO 自动生成的方法存根
System.out.println("("+eldest.getKey()+","+eldest.getValue()+")");
return size()>capacity;
}
}
public class LinkedHashMapForLRU {
public static void main(String[] args) {
Map<Integer, Integer> map = new LRULinkedHashMap<Integer,Integer>(5);
//存入7个键值对
for(int i=0;i<7;i++)
map.put(i, i);
//输出最后保存在缓存中的键值对
for(Iterator<Map.Entry<Integer,Integer>> it = map.entrySet().iterator();it.hasNext();) {
System.out.print(it.next().getKey()+" ");
}
}
}
输出情况如下:

可见我们实现的LRULinkedHashMap确实发挥了它的作用。
那LinkedHashMap在源码中是怎么实现LRU算法的呢?
接下来从Map的初始化构造、put、get这三个方面结合源码展开
初始化构造函数:
初始化构造在前面已经提到过,这里直接贴上LinkedHashMap的几个构造函数
public LinkedHashMap() {
super();
accessOrder = false;
}
构造一个以插入顺序排序的空LinkedHashMap,,其默认初始容量为16,并且负载系数为0.75
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
构造一个以插入顺序排序的空LinkedHashMap,,其负载系数为0.75,根据传入的参数参数决定其初始容量
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
构建一个以插入顺序排序的空LinkedHashMap,根据传入的参数决定其初始容量和负载系数。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
构建一个空LinkedHashMap,根据传入的参数决定其初始容量、负载系统及排序方式。
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
而最后这种构造函数则是构建一个指定Map的LinkedHashMap,默认负载系统为0.75,而初始容量则足够容纳指定的Map。
Put:
通过查看源码发现LinkedHashMap并没有重写父类HashMap的put方法,下面我们先看一下HashMap的put方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
发现它调用了putVal(hash(key), key, value, false, true),下面的即是其调用的putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
其中调用了两个关键的方法
void afterNodeAccess(Node<K,V> p)和 void afterNodeInsertion(boolean evict),而这两个方法实现关于插入节点和节点访问的细节,
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
从 if (evict && (first = head) != null && removeEldestEntry(first)) ,我们就能看到了调用了 removeEldestEntry(first)。即当该方法返回为真时,会调用方法来删除链表头。
而另一个重要的方法afterNodeAccess()则完成了在每一次节点访问后节点顺序的管理,想必这个方法会在get()方法中得到调用,下面我们就来看一下get()方法。
get():
LinkedHashMap重写了get()方法和getOrDefault()方法。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
对比HashMap中的get()
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
这里添加了对accessOrder的判断,即当为LRU模式下,会调用afterNodeAccess();这个方法会管理链表的排序,将最近访问过的结点放到链表末尾。
到这里我们应该基本上理清了LinkedHashMap对LRU算法的支持的实现手段。
即通过构造函数中的accessOrder参数来选择建Map模式,通过 afterNodeAccess(Node<K,V> p)在结点被访问后的顺序管理,
afterNodeInsertion(boolean evict)方法实现结点插入后,根据removeEldestEntry(first)的返回结果来进行结点的删除操作。
后记:
当然直接继承LinkedHashMap来实现LRU,在多线程环境下极有可能会出现问题,因为LinkedHashMap不是一个线程安全的容器,所以如果我们想要基于这种容器实现并发环境下的LRU的话,需要增加线程同步的处理。
其中一种处理方式是调用Collections.synchronizedMap()。
而另外一种方法不通过继承来重写LinkedHashMap,而是通过组合的方式实现,并且对map的get()、put()、remove()、size()等操作进行加锁(synchronized),或者在此基础上进行同步上的优化。
以上是关于LinkedHashMap:我还能实现LRU的主要内容,如果未能解决你的问题,请参考以下文章