LinkedHashMap实现LRU算法--高频面试题
Posted 会编程的老六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinkedHashMap实现LRU算法--高频面试题相关的知识,希望对你有一定的参考价值。
LinkedHashMap实现LRU算法--高频面试题
至于LRU算法是什么,相信大家都已经有所了解了,那么在这里就不作描述了。
一、什么是LinkedHashMap?
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
不难从源码中看出,实现了Map接口,是HashMap的子类。LinkedHashMap 相对于 HashMap 的源码比,是很简单的。它继承了 HashMap,仅重写了几个方法,以改变它迭代遍历时的顺序。
整体结构
直接上图,直观的了解一下它的结构:简单来看就是使用双向链表将hashmap中的节点根据插入顺序进行首尾连接。但是后面插入和查找数据的时候会将顺序进行细微的改动。后面会提到。
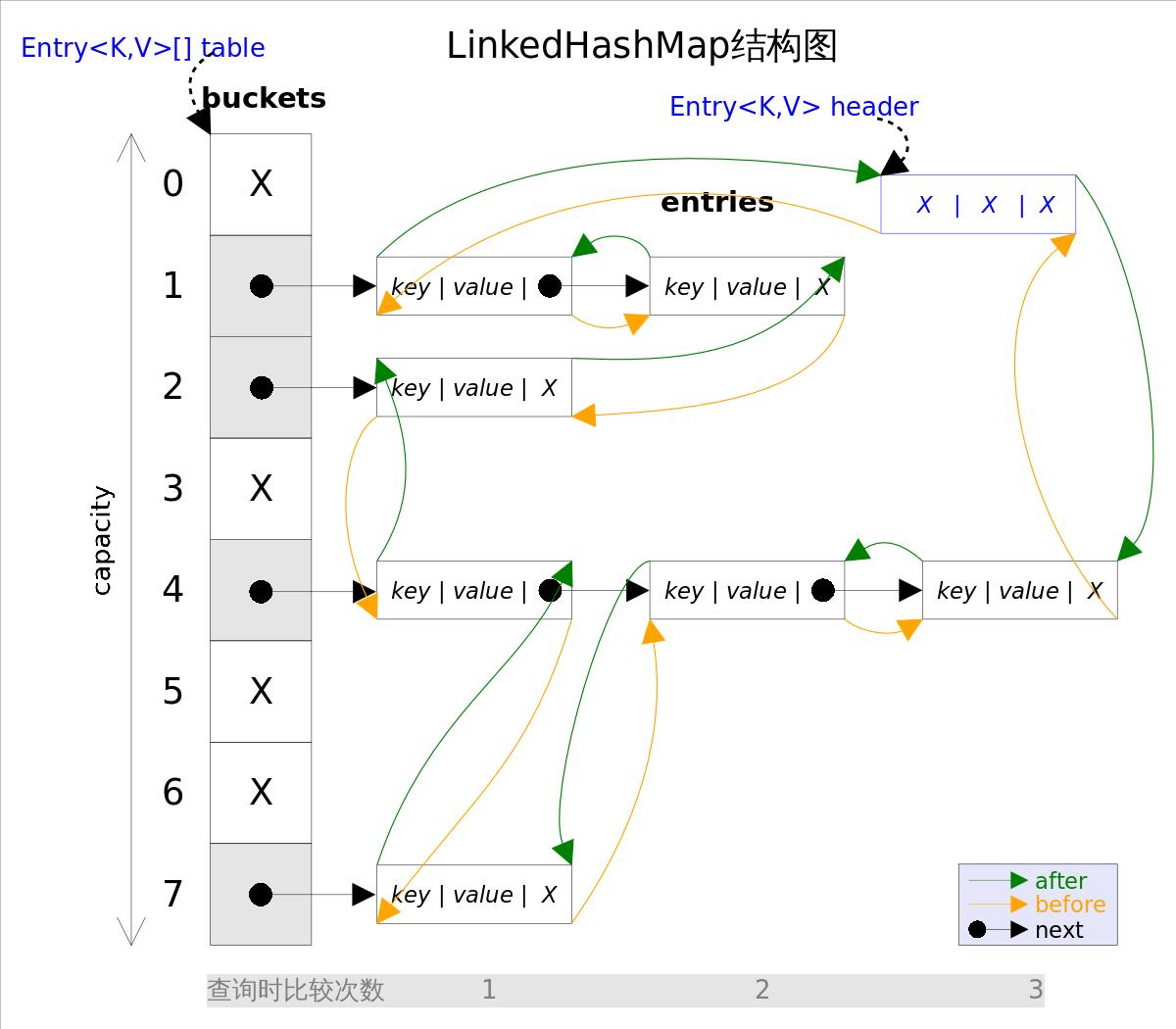
构造方法
public LinkedHashMap(int initialCapacity, float loadFactor)
super(initialCapacity, loadFactor);
accessOrder = false;
public LinkedHashMap(int initialCapacity)
super(initialCapacity);
accessOrder = false;
public LinkedHashMap()
super();
accessOrder = false;
public LinkedHashMap(Map<? extends K, ? extends V> m)
super();
accessOrder = false;
putMapEntries(m, false);
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
基本和hashmap没有什么太大差别。其中的accessOrder是什么呢?
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
使用了一个boolean类型值来控制迭代时的节点顺序。当accessOrder设置为false时,会按照插入顺序进行排序,当accessOrder为true是,会按照访问顺序,也就是插入还是访问时会将当前节点放置到尾部,尾部代表的是最近访问的数据。注意:JDK1.6是反过来的,jdk1.6头部是最近访问的。
Node
LinkedHashMap 的节点 Entry<K,V> 继承自 HashMap.Node<K,V>
static class Entry<K,V> extends HashMap.Node<K,V>
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next)
super(hash, key, value, next);
这里的before“指向”上一个Node节点,after“指向”下一个Node节点。
新增部分
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
不难理解就是一个是整个双向链表的头节点,另一个是整个双向链表的尾节点。
新增方法
重写了HashMap中的构建新节点的方法:newNode(); 在每次插入数据时都会构建新节点,通过linkNodeLast(LinkedHashMap.Entry<K,V> p) 将新节点链接在内部双向链表的尾部。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e)
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p)
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else
p.before = last;
last.after = p;
查找方法
public V get(Object key)
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
void afterNodeAccess(Node<K,V> e) // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e)
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else
p.before = last;
last.after = p;
tail = p;
++modCount; //注意!!!
LinkedHashMap的改动是:在accessOrder为true时,会去调用void afterNodeAccess(Node<K,V> e),将这个节点移动到整个双向链表的末尾。
注意:调用void afterNodeAccess(Node<K,V> e)后,最后会修改modCount的值。这会导致:如果在将整个双向链表进行迭代输出的时候去查询节点数据的话(执行void afterNodeAccess(Node<K,V> e)),就会触发 fail-fast 机制。也就是快速失败机制,是java集合(Collection)中的一种错误检测机制。当在迭代集合的过程中该集合在结构上发生改变的时候,就有可能会发生fail-fast,即抛出 ConcurrentModificationException异常。fail-fast机制并不保证在不同步的修改下一定会抛出异常,它只是尽最大努力去抛出,所以这种机制一般仅用于检测bug。顺带一提ArrayList在使用迭代器遍历时如果使用remove删除元素,也会触发fail-fast机制。
删除元素
对remove(); 并没有做改动。但是重写了:
void afterNodeRemoval(Node<K,V> e) // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
也就是说,删除节点的话还会把结点从双向链表删除。也就是将删掉节点头尾节点进行连接。
补充
- 对于
containsValue(),因为双向链表的缘故,只需要遍历双向链表去判断value是否相等就好了。而原来的hashmap中则需要进行两次遍历。
//hashmap
public boolean containsValue(Object value)
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0)
for (int i = 0; i < tab.length; ++i) //遍历Node数组,tab所存储元素为每个链表的第一个元素
for (Node<K,V> e = tab[i]; e != null; e = e.next) //循环链表,判断值是否相同
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
return false;
//LinkedHashMap
public boolean containsValue(Object value)
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) //双向链表遍历
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
return false;
- 双链表节点的顺序在 LinkedHashMap 的增、删、改、查时都会更新。以满足按照插入顺序输出,还是访问顺序输出。
二、使用LinkedHashMap实现LRU算法
public static int[] LRU (int[][] operators, int k)
// write code here
//注意初始化的时候需要定义好是否需要按照访问顺序来进行,如果这里默认是false就不会将get操作的值放至双向链表末尾
LinkedHashMap<Integer,Integer> linkedHashMap = new LinkedHashMap(k,0.75f,true);
ArrayList<Integer> list = new ArrayList<>();
int flag = 0;
//开始读取操作
for (int[] operator : operators)
//如果是set操作
if (operator[0] == 1)
//优先判断是否超出预定大小
if(linkedHashMap.size() >= k)
//获取双向链表中的第一个entry
Map.Entry<Integer, Integer> first = linkedHashMap.entrySet().iterator().next();
System.out.println(first.getKey()+" "+first.getValue());
//将这个entry删除
linkedHashMap.remove(first.getKey());
//最后加入值
linkedHashMap.put(operator[1],operator[2]);
//如果是get操作
if (operator[0] == 2)
//判断是否存在
if (linkedHashMap.containsKey(operator[1]))
//存在值就存入到list中
list.add(linkedHashMap.get(operator[1]));
else
//不存在就存-1到list中
list.add(-1);
//为了更加直观看出整个过程,在每次操作一次后都会遍历一边。正式环境中要删除,因为会导致超时
for(Map.Entry<Integer, Integer> entry : linkedHashMap.entrySet())
System.out.println("key:" + entry.getKey() + " value:" + entry.getValue());
System.out.println("=============================");
//将其转换成数组格式,一开始定义数组如果有空间没有用到会是0值
int[] array = new int[list.size()];
for (Integer item : list)
array[flag++] = item;
return array;
以上是关于LinkedHashMap实现LRU算法--高频面试题的主要内容,如果未能解决你的问题,请参考以下文章