HDFS架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS架构相关的知识,希望对你有一定的参考价值。
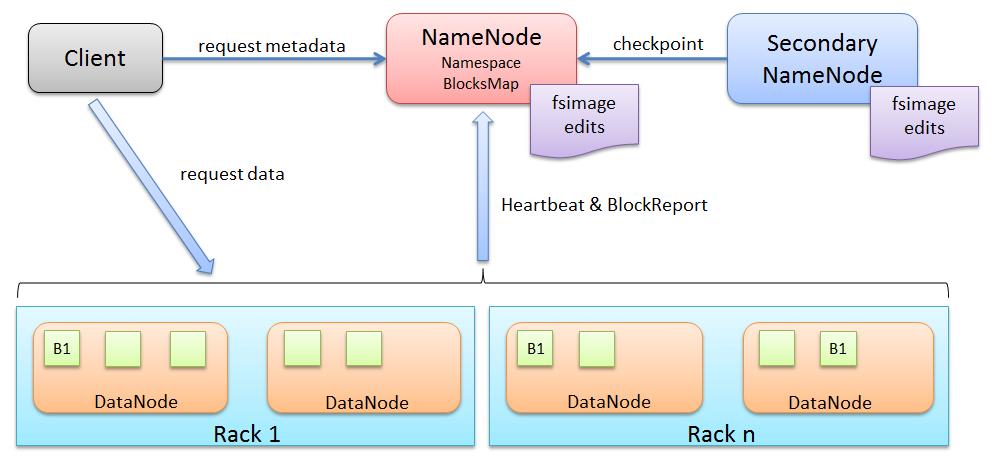
参考技术A HDFS中的文件是以数据块(Block)的形式存储的,默认最基本的存储单位是128 MB(Hadoop 1.x为64 MB)的数据块。也就是说,存储在HDFS中的文件都会被分割成128 MB一块的数据块进行存储,如果文件本身小于一个数据块的大小,则按实际大小存储,并不占用整个数据块空间。HDFS的数据块之所以会设置这么大,其目的是减少寻址开销。数据块数量越多,寻址数据块所耗的时间就越多。当然也不会设置过大,MapReduce中的Map任务通常一次只处理一个块中的数据,如果任务数太少,作业的运行速度就会比较慢。HDFS的每一个数据块默认都有三个副本,分别存储在不同的DataNode上,以实现容错功能。因此,若数据块的某个副本丢失并不会影响对数据块的访问。数据块大小和副本数量可在配置文件中更改NameNode是HDFS中存储元数据(文件名称、大小和位置等信息)的地方,它将所有文件和文件夹的元数据保存在一个文件系统目录树中,任何元数据信息的改变,NameNode都会记录。HDFS中的每个文件都被拆分为多个数据块存放,这种文件与数据块的对应关系也存储在文件系统目录树中,由NameNode维护。NameNode还存储数据块到DataNode的映射信息,这种映射信息包括:数据块存放在哪些DataNode上、每个DataNode上保存了哪些数据块。NameNode也会周期性地接收来自集群中DataNode的“心跳”和“块报告”。通过“心跳”与DataNode保持通信,监控DataNode的状态(活着还是宕机),若长时间接收不到“心跳”信息,NameNode会认为DataNode已经宕机,从而做出相应的调整策略。“块报告”包含了DataNode上所有数据块的列表信息。
DataNode是HDFS中真正存储数据的地方。客户端可以向DataNode请求写入或读取数据块,DataNode还在来自NameNode的指令下执行块的创建、删除和复制,并且周期性地向NameNode汇报数据块信息。
NodeSecondaryNameNode用于帮助NameNode管理元数据,从而使NameNode能够快速、高效地工作。它并不是第二个NameNode,仅是NameNode的一个辅助工具。HDFS的元数据信息主要存储于两个文件中:fsimage和edits。fsimage是文件系统映射文件,主要存储文件元数据信息,其中包含文件系统所有目录、文件信息以及数据块的索引;edits是HDFS操作日志文件,HDFS对文件系统的修改日志会存储到该文件中。当NameNode启动时,会从文件fsimage中读取HDFS的状态,也会对文件fsimage和edits进行合并,得到完整的元数据信息,随后会将新HDFS状态写入fsimage。但是在繁忙的集群中,edits文件会随着时间的推移变得非常大,这就导致NameNode下一次启动的时间会非常长。为了解决这个问题,则产生了SecondaryNameNode,SecondaryNameNode会定期协助NameNode合并fsimage和edits文件,并使edits文件的大小保持在一定的限制内。SecondaryNameNode通常与NameNode在不同的计算机上运行,因为它的内存需求与NameNode相同,这样可以减轻NameNode所在计算机的压力。
HDFS 架构
一、简介
Hadoop Distributed File System:Hadoop 分布式文件系统,简称HDFS。简单来说就是一个文件系统,和我们平时使用 Linux 系统操作非常类似。如下图:
二、HDFS 经典架构
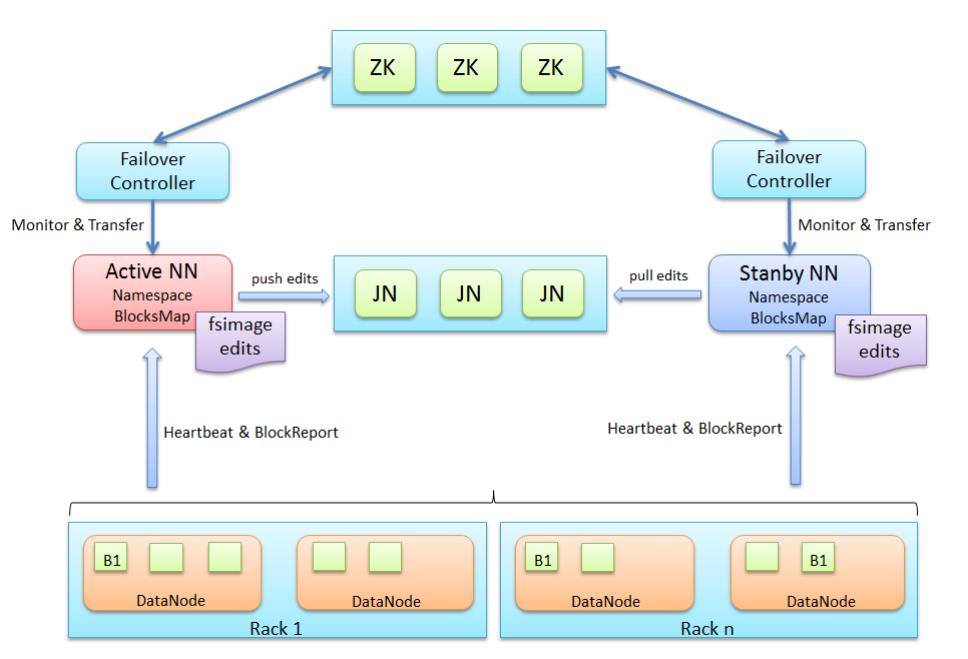
三、HDFS HA 架构
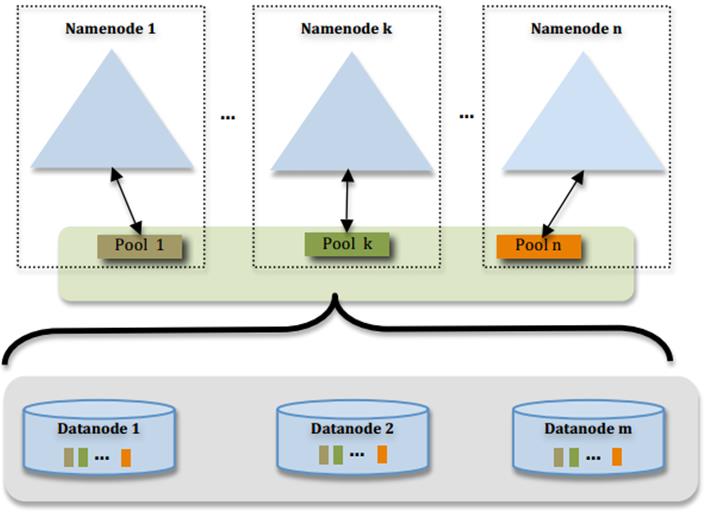
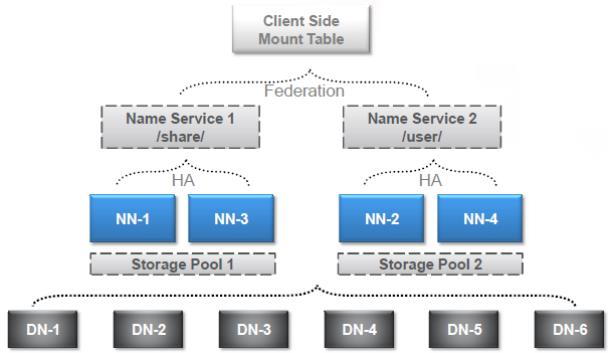
四、HDFS Federation 架构
五、HDFS 完全架构
以上是关于HDFS架构的主要内容,如果未能解决你的问题,请参考以下文章