一种自动分类数据方法_初探索
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一种自动分类数据方法_初探索相关的知识,希望对你有一定的参考价值。
知识分享文档, 已替换一些可能敏感的内容
1. 本文由来
当前的防御系统, 已经存储了一定量的基本数据(例如数据a,数据c, 数据c等), 如何利用这些数据,判断不同账户是否正常,是防御的一个重点工作。 本文记录雷健辉的一个探索过程。
2. 首次判断方法
先来看看我们手头上有什么数据(一下数据由等级xx工具统计并生成):
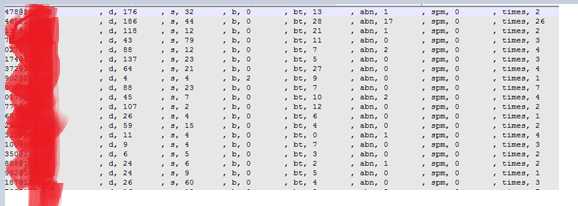
其中:
d – 数据a
s – 数据b
b – 数据c
bt – 数据d
abn – 数据e
spm – 数据f
times – 数据g
用人肉判断以上数据: 初步发现, 账号是否作弊与【数据b】【数据a】两个数据关系密切。先看组成的二维图:
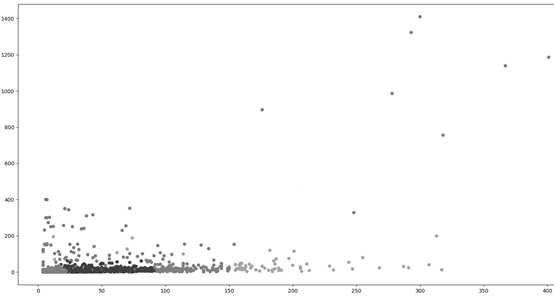
横坐标是【数据a】 , 纵坐标是【数据b】。
从正常的用户来看, 【数据a】应该是大于【数据b】的。通讯一般是熟人之间发生嘛, 有来必有回。
从上图分析可以得出一些简单 结论:
- 【数据b】过大不正常
- 【数据b】远大于【数据a】大概率不正常
- 【数据a】远大于【数据b】是大概率正常用户
根据上面的结论形成规则: 以【数据b】/ 【数据a】 = 1为分割线
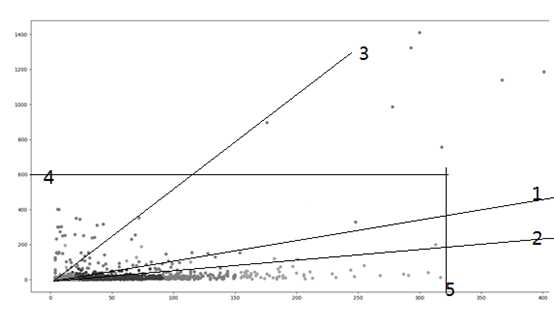
如上图
线1表示 斜率 = 1
线2表示 斜率= 0.5
线3表示 斜率= 2
线4表示 【数据b】大于600
线5表示 【数据a】大于320
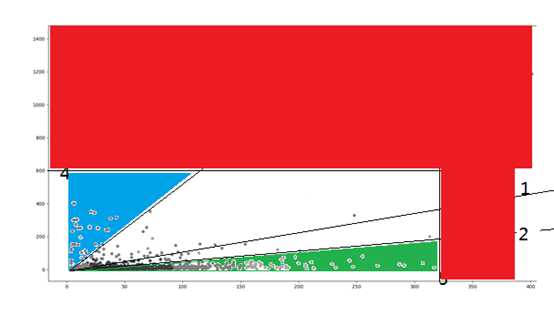
得出上面的区域
【红色】【蓝色】区域账号拉黑
【绿色】区域账号为优质
剩下【白色】区域账号为普通
判断方法已确定, 函数已写好, 太好了! 应该可以一劳永逸的解决账号判断问题了吧, 可实际的效果如何呢?
3. 一刀切的效果
令人遗憾的是, 如上面一刀切法的效果并不好。 不同范围的斜率如何确定?【数据b】的阀值如何确定? 数值定大了, 拦截效果不好; 数值定小了, 产生大量的误判。此外, 人肉确定数值的另一个副作用是, 需要人肉观察拦截效果, 不断调整阀值, 人力成本骤增。
换个角度, 让我们从代码的层面看看, 实现上面判断逻辑的代码是什么样子的:
// 1. xx用户:xxx调成3 // 数据b 非0, 数据b小于350, // 比例大于 0.5 的, // 2. 下调的: xxx调成1 // 数据b 大于600 // 数据a 大于550 // 比例大于2 拉黑 // 比例在2 - 0.5 之间的, 定为2 if (b_trust >= 500) { temp_priority = low_priority; } else if (s_d_rate <= 0.5 && s_d_rate > 0 &&double_trust < 350) { temp_priority = high_priority; } else if (s_d_rate >= 2 ) { // 补充规则: if (s_d_rate <= 5 && times <= 10) { temp_priority = middle_priority; } else { temp_priority = low_priority; } } else { temp_priority = middle_priority; }
如上图, 针对两维的数据(【数据b】,【数据a】), 代码尚算可读, 可是由于防御效果不好, 不得不加入次数(times)协同判断的“补充规则”。 想象一下,如果针对3维, 4维, 或者更高N维的数据, 要写多少个if else嵌套才能判断得清楚? 要定多少个magic number来做边界值? 即使是能写出这样的判断函数, 假如攻击方的行为有变化, 规则需要随之修改,此代码维护的成本也必定是灾难性的(谁能看得懂)。
4. 机器代替人肉
重复的东西就应该交给机器去做。 换个角度思考, 能否让机器帮我们设计判断规则, 机器帮我们确定magic number, 而我们只做监工的角色?
带着这个想法, 我做了以下尝试:
5. 收集数据
原始数据我们已经拥有, 要想让机器训练数据, 首先得有训练用的数据集。 要得到一组带有标签(是否攻击账号), 我选取的Pycluster(python的一个聚类库)来帮我做聚类,因为我不想在数千条乃至数万条数据中,人肉判断然后打标签。 通过同样的原始数据(输入【数据b】【数据a】【数据c】【数据d】 4维数据),聚类出的效果如下图:

位于左中的【浅蓝】【蓝】点, 和右上的【红】点,是攻击账户的高危地带, 需要我重点筛查。而其余颜色的账户正常度就比较高了(也并非完全没有)。
聚类+手动筛查后,得到带有标签的训练数据集:
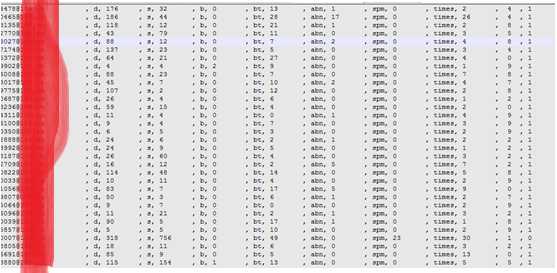
最后一位数字: 0表示攻击账户, 1表示正常账户。
倒数第二位数字: 0-9, 表示Pycluster聚类后的分类标签。
6. 开始训练
以上共1932条打好标签的账号数据。 我们希望验证一下训练预测模型的准确性。还需完成以下步骤:
随机乱序1932条数据; 抽取前200条作为测试数据(test_data); 剩余的数据(1732条)作为训练数据(train_data)。
为了生成可预测新数据的判断器, 我选用的是sklearn(python的一个机器学习库),并用其中自带的【朴素贝叶斯分类器naive_Bayes】进行分类(里面还有很多其他的分类器, 由于时间关系, 我只测试了naive_bayes)。
代码如下:
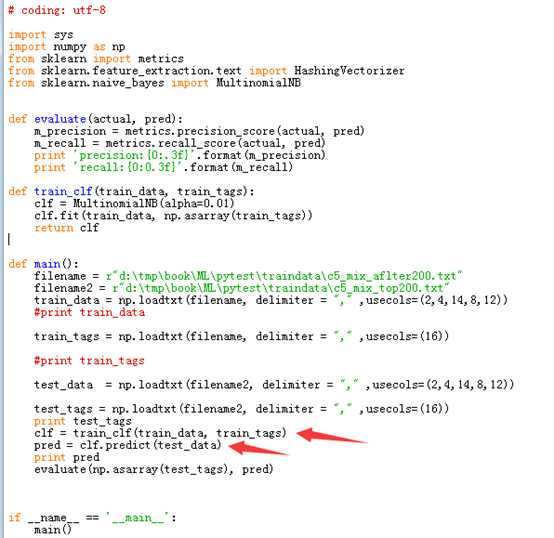
重点看两个箭头所指, 由train_clf函数训练1732条数据(train_data)后生成的 clf 就是一个判断器。 pred 就是 clf 针对测试数据(test_data)做出的预测。
运行后得出,预测准确率为:95.4%
7. 初次训练后的思考
针对95.4% 这个数字, 基本符合预期, 但是我个人认为, 这个准确率还达不到放心使用的标准的(至少需要99.9%? 几个9?)。
总结了以下几点, 有助于进一步提高准确率:
- 原始数据可进一步优化。
a) 例如数据由于某些因素, 可能不够准确。
- 拓展数据维度。
a) 现在的数据维度是不够的, 明显例子是, 部分攻击者, 和正常的某种行为的账号行为非常相似, 这样会让训练器难以判断。
- 训练模型的度量。
a) 现在只用了naive_bayes一种训练模型, 剩余的模型还有很多, 如何确定训练变量, 如何衡量不同模型的训练预测效果, 如何判断训练器是否【过拟合】或【欠拟合】, 都是进一步需要研究的领域。
8. 总结
对于机器训练数据, 好处是显而易见的。 我们要做的工作, 从人肉定规则变成为: begin ->收集数据-> 设置标签 ->训练数据(调优训练模型, 完善基础数据)-> 实际使用 -> end -> 定期重新训练新数据集, 防止模型过期 -> begin。 我们的角色也真正变成一个监工, 避免重复劳作, 从而提高生产力。
以上是关于一种自动分类数据方法_初探索的主要内容,如果未能解决你的问题,请参考以下文章