Spark HA on yarn 最简易安装。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark HA on yarn 最简易安装。相关的知识,希望对你有一定的参考价值。
机器部署:
准备两台机以上linux服务器,安装好JDK,zookeeper,hadoop
spark部署
master:hadoop1,hadoop2(备用)
worker:hadoop2,hadoop3,hadoop4
软件准备
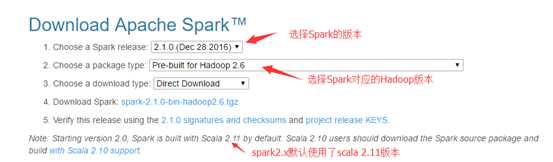
spark下载网址:http://spark.apache.org/downloads.html
当前最新版本为2.11,下载你所需要的spark版本,注意spark版本与hadoop版本要相互匹配。
安装步骤:
1.上传spark安装包到linux

2. 解压安装包到指定位置(比如说我的在apps下)
tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz -C apps/
3.配置spark
进入spark安装目录conf下
cd apps/spark-1.6.3-bin-hadoop2.6/conf/spark-env.sh
重命名spark-env.sh.template
mv spark-env.sh.template spark-env.sh
修改spark-env.sh
在该配置文件中添加配置
export JAVA_HOME=/home/kinozk/apps/jdk1.8.0_9
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark"
export HADOOP_CONF_DIR=/home/kinozk/apps/hadoop/etc/hadoop
重命名并修改slaves.template
mv slaves.template slaves
vi slaves
在该文件中红添加字节嗲你所在位置(woker节点)
hadoop2
hadoop3
hadoop4
保存退出

将配置好的Spark拷贝到其他节点上
scp -r spark-1.6.3-bin-hadoop2.6/ hadoop2:$PWD
scp -r spark-1.6.3-bin-hadoop2.6/ hadoop3:$PWD
scp -r spark-1.6.3-bin-hadoop2.6/ hadoop4:$PWD
配置环境变量
这里就不说了,跟配置hadoop,zookeeper时的配置方式下相同,
启动集群
先启动zookeeper,然后启动hadoop,最后启动spark
需要注意的是,spark与hadoop中都有start-all.sh命令,因此启动spark时进入spark安装目录的跟目录下
在hadoop1上执行sbin/start-all.sh脚本,然后在hadoop2上执行sbin/start-master.sh启动第二个Master
登录spark管理界面查看集群状态(主节点):http://hadoop1:8080/
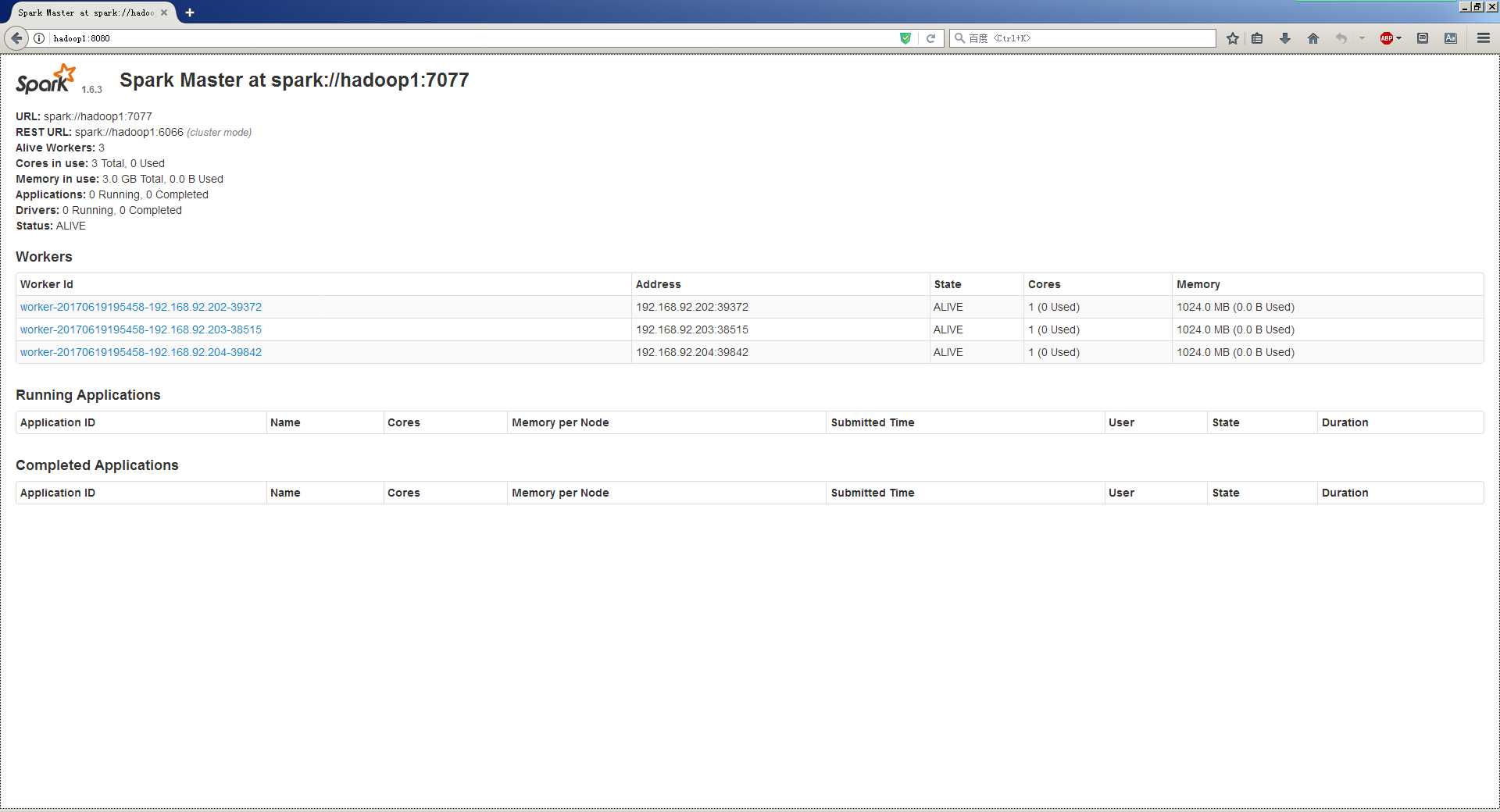
此时hadoop1节点status为alive,hadoop2节点status为standby
在hadoop1 上kill掉master进程,再登录spark管理界面查看集群状态(主节点):http://hadoop2:8080/查看hadoop2状态,是否被切换为alive状态
以上是关于Spark HA on yarn 最简易安装。的主要内容,如果未能解决你的问题,请参考以下文章