elasticsearch学习笔记-倒排索引以及中文分词
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch学习笔记-倒排索引以及中文分词相关的知识,希望对你有一定的参考价值。
我们使用数据库的时候,如果查询条件太复杂,则会涉及到很多问题
1、无法维护,各种嵌套查询,各种复杂的查询,想要优化都无从下手
2、效率低下,一般语句复杂了之后,比如使用or,like %,,%查询之后数据库的索引就没有办法利用到了,这个时候的搜索就会全表扫描,数据量少的时候可能性能还能接受,但是数据量大了之后性能会直线下降,速度慢的一塌胡萝卜。。
但是呢,数据库的聚集索引查询还是极快的,
所以我们可以利用这一点尝试建立一下这样的索引结构--就是把数据库里面的每一条记录作为一个键,相同记录的Id的集合作为值,这样我们查询记录的时候就可以通过记录快速定位到数据表的id,从而就可以快速查询到这条数据了如图所示
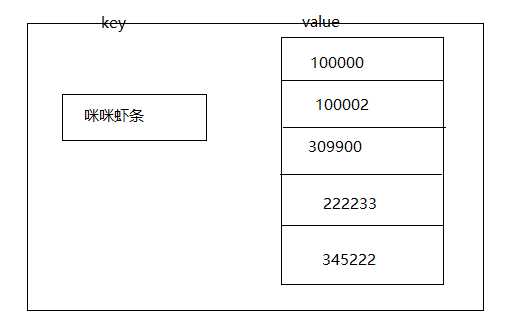
如果要搜索咪咪虾条的话,就可以带出这些value值,我们都知道key-value的查询是非常快的,所以这个耗时会很短,然后通过id来查询就会使得效率高出很多,这个思路可以用在所有字段上,但是对空间的使用会多一些,不过存储这东东还是蛮便宜的,毕竟体验才是最重要的对吧,这种就叫基本的倒排索引。
但是如果用户只搜索咪咪呢,如何能够定位到这条咪咪虾条的记录呢?
这里就涉及到了另一项比较重要的技术--中文分词
这里简要说明下中文分词:
中文分词里面有个东西必不可少,就是词库
假设我们的词库很简单,就这么几条词:1、咪咪,2、虾,3、虾条
这个时候,我们存入一条咪咪虾条,id是10000的记录的时候呢
分词就会这么干,先读第一个字,咪,然后发现没有单个的这个词,但是有一个咪咪,然后就会读取第二个字,第二个字还是咪,这个时候咪咪是一个词,然后读取第三个字,虾,发现虾是单个的一个字,词典里也有这个字,咪虾不存在,咪咪虾更加不存在,那么咪咪这个词就确定了,继续往下读,发现条,然后发现虾是一个词语,虾条也是一个词语,而现在已经读完了,所以现在分词有两种组合,虾和条,虾条,显然第一条有点扯淡,条不能作为一个词,所以就取后者,这样虾条这个词就出来了。
接着我们存入一条咪咪id 为10002的数据的时候,方法同上
然后存到搜索引擎的数据的就是这样
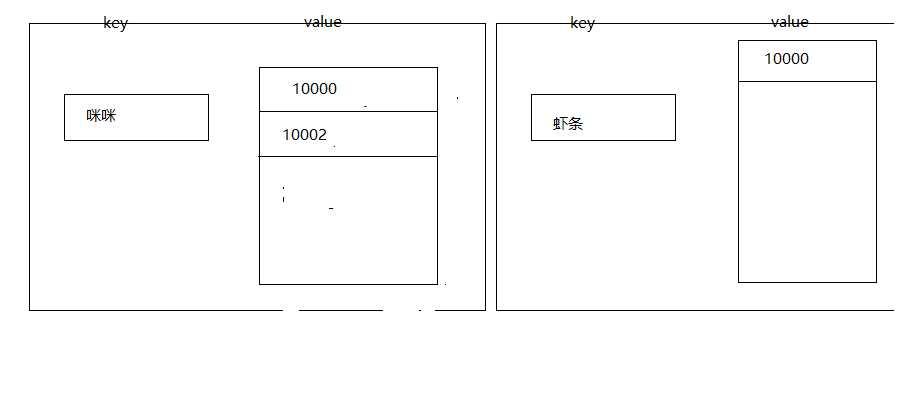
这个时候就有两条记录,咪咪对应的有两条记录,虾条对应一条
如果我们搜索虾条的话,10000就会被搜索出来,如果搜索咪咪的话,那10002和10000就会被搜索出来
如果我们搜索咪咪虾条的话,就会按照上面的分词逻辑将我们的搜索条件进行分词,然后分出来咪咪和虾条两个词,然后查询,再merge最终得到两个id:10000,10002
分词这块就我所理解也就这样了。
说了这么多,具体怎么做呢?其实很简单,一个插件就搞定,我用的是IK分词插件,安装简单,地址在这里,里面也有安装说明,安装完之后重启下就ok了
https://github.com/medcl/elasticsearch-analysis-ik
中文分词插件
目前就这么多,本人也是刚学这个,写的有什么问题欢迎指出,谢谢~
以上是关于elasticsearch学习笔记-倒排索引以及中文分词的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch学习笔记2:ES核心概念 -- 索引倒排索引类型文档
Elasticsearch学习笔记2:ES核心概念 -- 索引倒排索引类型文档