Elasticsearch学习笔记2:ES核心概念 -- 索引倒排索引类型文档
Posted Vincent9847
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch学习笔记2:ES核心概念 -- 索引倒排索引类型文档相关的知识,希望对你有一定的参考价值。
一、ES和关系型数据库的对比
| Elasticsearch | Relational DB |
| 索引(index) | 数据库(database) |
| 类型(types) | 表(tables) |
| 文档(documents) | 行(rows) |
| 字段(fields) | 列(columns) |
Elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表0,贝格类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
1.Elasticsearch的物理设计
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移。
2.逻辑设计
一个索引类型中,包含多个文档,比如说文档1 ,文档2。当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引->类型->文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串。
二、集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
可以通过GET /_cluster/health获取集群健康状况,它有红、黄、绿三种状态之分。
三、节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch 节点, 这时启动一个节点, 会默认创建并加入一个叫做“elasticsearch”的集群。
节点是Elasticsearch运行中的实例,而 集群 则包含一个或多个具有相同 cluster.name 的节点,它们协同工作,共享数据,并共同分担工作负荷。由于节点是从属集群的,集群会自我重组来均匀地分发数据。集群中的一个节点会被选为master节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集群或从集群删除节点。master节点无需参与文档层面的变更和搜索,这意味着仅有一个master节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为master节点。我们例举的集群只有一个节点,因此它会扮演master节点的角色。
作为用户,我们可以访问包括master节点在内的集群中的任一节点。每个节点都知道各个文档的位置,并能够将我们的请求直接转发到拥有我们想要的数据的节点。无论我们访问的是哪个节点,它都会控制从拥有数据的节点收集响应的过程,并返回给客户端最终的结果。这一切都是由Elasticsearch透明管理的。
四、索引
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
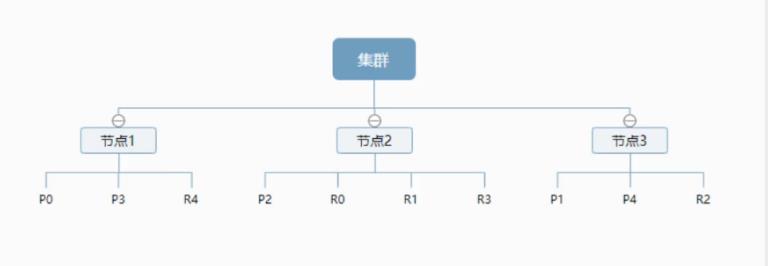
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引。默认的,如果你创建索引,那么索引将会有个5个分片( primary shard,又称主分片)构成的,每一个主分片会有一个副本( replica shard ,又称复制分片)。
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么?
五、倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever# 文档1包含的内容
To forever,study every day,good good up #文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档,两个文档都匹配,但是第一个文档比第二个匹配程度更高,如果没有别的条件,现在,这两个包含关键字的文档都将返回。
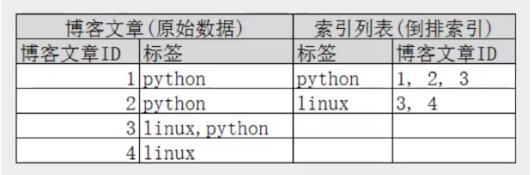
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比:
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
六、类型(types)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
七、文档(documents)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!{就是一个json对象!fastjson进行自动转换!)
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
八、分片和复制(shards & replicas)
分片:
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10 亿文档的索引占据1TB 的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点的计算能力达不到期望的复杂功能的要求。这种情况下,可以将数据切分,每部分是一个单独的apache lucene索引,称为分片。
为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量、
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制:
复制之所以重要,有两个主要原因:[高可用与高吞吐]:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch 中的每个索引被分片5 个主分片和1 个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5 个主分片和另外5 个复制分片(1 个完全拷贝),这样的话每个索引总共就有10 个分片。
以上是关于Elasticsearch学习笔记2:ES核心概念 -- 索引倒排索引类型文档的主要内容,如果未能解决你的问题,请参考以下文章