bioperl 自动化下载genbank 中的序列
Posted 庐州月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了bioperl 自动化下载genbank 中的序列相关的知识,希望对你有一定的参考价值。
当我们想要从genbank 中下载序列的时候,总需要点击右上角的download 按钮,选择对应的格式,然后通过浏览器进行下载,这样反复的点击很费时间了
其实可以通过bioperl 自动化的完成下载;
代码如下:
#!/usr/bin/env perl use Bio::SeqIO; use Bio::DB::GenBank; my ($acc, $out_dir) = @ARGV; die "Usage:perl $0 <acc_number> <out_dir>\\n" if scalar @ARGV != 2; system qq{mkdir -p $out_dir} if not -d $out_dir; my $seq_obj = retriev_seq($acc); download_seq($seq_obj, \'fasta\', qq{>$out_dir/sequence.fasta}); download_seq($seq_obj, \'genbank\', qq{>$out_dir/sequence.gb}); sub retriev_seq { my $acc = shift; my $db_obj = Bio::DB::GenBank->new; my $seq_obj = $db_obj->get_Seq_by_acc($acc); return $seq_obj; } sub download_seq { my $seq_obj = shift; my $fmt = shift; my $out = shift; my $seqio_obj = Bio::SeqIO->new(-file => $out, -format => $fmt ); $seqio_obj->write_seq($seq_obj); }
这个脚本接受两个参数,第一个参数为 序列对应的编号,第二个参数为输出的目录
以 https://www.ncbi.nlm.nih.gov/nuccore/NC_024541.1 为例:
通过浏览器下载是这个样子的:
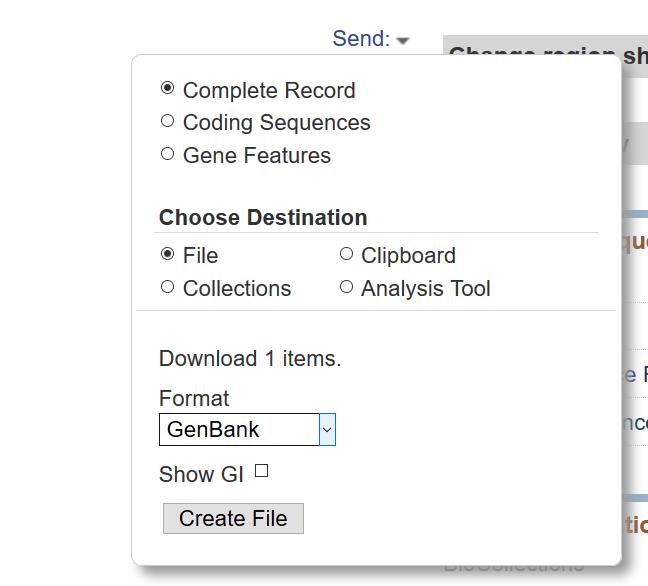
点击Send 按钮,在弹出的对话框中选择下载的序列的区间,对应的格式
通过脚本下载是这个样子的,首先得到序列对应的编号,如下图所示:

然后运行下面的命令:
perl download_reference.pl NC_024541 ./
这样通过序列对应的编号就可以自动化的下载对应的序列了
其实,bioperl 当中还提供了其他的检索序列的方式,比如按照 gi号,功能非常强大。
参考资料:
http://bioperl.org/howtos/Beginners_HOWTO.html
以上是关于bioperl 自动化下载genbank 中的序列的主要内容,如果未能解决你的问题,请参考以下文章
怎么找Genbank呀,上哪里去搜?要找基因的序列不知道,怎么知道呢