Python之路:进程线程
Posted Stefan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python之路:进程线程相关的知识,希望对你有一定的参考价值。
本节内容
一、进程与线程区别
1.1 什么是线程
1.2 什么是进程
1.3 进程与线程的区别
二、Python GIL全局解释器锁
三、线程
3.1 threading模块
3.2 Join & Daemon
3.3 线程锁(互斥锁Mutex)
3.4 RLock(递归锁)
3.5 Semaphore(信号量)
3.6 Events
3.7 Queue队列
3.8 生产者消费者模型
四、进程
4.1 多进程multiprocessing
4.2 进程间通讯
4.3 Queue队列
4.4 Pipes
4.5 Managers
4.6 进程同步
4.7 进程池
一、进程与线程区别
1.1 什么是线程(thread)?
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions.
Suppose you‘re reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers.
If you have a roommate, and she‘s using the same technique, she can take the book while you‘re not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were.
Threads work in the same way. A CPU is giving you the illusion that it‘s doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU.
On a more technical level, an execution context (therefore a thread) consists of the values of the CPU‘s registers.
Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads.
Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
1.2 什么是进程(process)?
An executing instance of a program is called a process.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
1.3 进程与线程的区别?
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
二、Python GIL(Global Interpreter Lock)
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
上面的核心意思就是,无论你启动多少个线程,你有多少个cpu, Python在执行的时候在同一时刻只允许一个线程运行。
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython 就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
这篇文章透彻的剖析了GIL对python多线程的影响,强烈推荐:http://www.dabeaz.com/python/UnderstandingGIL.pdf
三、线程
3.1 threading模块
线程有2种调用方式,如下:
直接调用:
import threading
import time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__ == ‘__main__‘:
t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例
t1.start() #启动线程
t2.start() #启动另一个线程
print(t1.getName()) #获取线程名
print(t2.getName())
继承式调用:
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == ‘__main__‘:
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
3.2 Join & Daemon
Some threads do background tasks, like sending keepalive packets, or performing periodic garbage collection, or whatever. These are only useful when the main program is running, and it‘s okay to kill them off once the other, non-daemon, threads have exited.
Without daemon threads, you‘d have to keep track of them, and tell them to exit, before your program can completely quit. By setting them as daemon threads, you can let them run and forget about them, and when your program quits, any daemon threads are killed automatically.
import time
import threading
def run(n):
print(‘[%s]------running----\n‘ % n)
time.sleep(2)
print(‘--done--‘)
def main():
for i in range(5):
t = threading.Thread(target=run,args=[i,])
#time.sleep(1)
t.start()
t.join(1)
print(‘starting thread‘, t.getName())
m = threading.Thread(target=main,args=[])
m.setDaemon(True) #将主线程设置为Daemon线程,它退出时,其它子线程会同时退出,不管是否执行完任务
m.start()
#m.join(timeout=2)
print("---main thread done----")Note:Daemon threads are abruptly stopped at shutdown. Their resources (such as open files, database transactions, etc.) may not be released properly. If you want your threads to stop gracefully, make them non-daemonic and use a suitable signalling mechanism such as an Event.
3.3 线程锁(互斥锁Mutex)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况?
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print(‘--get num:‘,num )
time.sleep(1)
num -=1 #对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print(‘final num:‘, num )
正常来讲,这个num结果应该是0, 但在python 2.7上多运行几次,会发现,最后打印出来的num结果不总是0,为什么每次运行的结果不一样呢? 哈,很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
*注:不要在3.x上运行,不知为什么,3.x上的结果总是正确的,可能是自动加了锁
加锁版本:
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print(‘--get num:‘,num )
time.sleep(1)
lock.acquire() #修改数据前加锁
num -=1 #对此公共变量进行-1操作
lock.release() #修改后释放
num = 100 #设定一个共享变量
thread_list = []
lock = threading.Lock() #生成全局锁
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print(‘final num:‘, num )
3.4 RLock(递归锁)
递归锁是指在如上所述的锁中再包含子锁
import threading,time
def run1():
print("grab the first part data")
lock.acquire()
global num
num +=1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2+=1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print(‘--------between run1 and run2-----‘)
res2 = run2()
lock.release()
print(res,res2)
if __name__ == ‘__main__‘:
num,num2 = 0,0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print(‘----all threads done---‘)
print(num,num2)
3.5 Semaphore(信号量)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如停车场有10个车位,那最多只允许10个车停放,后面的车只能等里面有车出来才能再进去。
import threading,time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s\n" %n)
semaphore.release()
if __name__ == ‘__main__‘:
num= 0
semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
while threading.active_count() != 1:
pass #print threading.active_count()
else:
print(‘----all threads done---‘)
print(num)
3.6 Events
An event is a simple synchronization object;
the event represents an internal flag, and threads
can wait for the flag to be set, or set or clear the flag themselves.
event = threading.Event()
# a client thread can wait for the flag to be set
event.wait()
# a server thread can set or reset it
event.set()
event.clear()
If the flag is set, the wait method doesn’t do anything.
If the flag is cleared, wait will block until it becomes set again.
Any number of threads may wait for the same event.
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。
import threading,time
import random
def light():
if not event.isSet():
event.set() #wait就不阻塞 #绿灯状态
count = 0
while True:
if count < 10:
print(‘\033[42;1m--green light on---\033[0m‘)
elif count <13:
print(‘\033[43;1m--yellow light on---\033[0m‘)
elif count <20:
if event.isSet():
event.clear()
print(‘\033[41;1m--red light on---\033[0m‘)
else:
count = 0
event.set() #打开绿灯
time.sleep(1)
count +=1
def car(n):
while 1:
time.sleep(random.randrange(10))
if event.isSet(): #绿灯
print("car [%s] is running.." % n)
else:
print("car [%s] is waiting for the red light.." %n)
if __name__ == ‘__main__‘:
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in range(3):
t = threading.Thread(target=car,args=(i,))
t.start()
3.7 Queue队列
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
- class
queue.Queue(maxsize=0) #先入先出
- class
queue.LifoQueue(maxsize=0) #last in fisrt out- class
queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列 - class
-
Constructor for a priority queue. maxsize is an integer that sets the upperbound limit on the number of items that can be placed in the queue. Insertion will block once this size has been reached, until queue items are consumed. If maxsize is less than or equal to zero, the queue size is infinite.
The lowest valued entries are retrieved first (the lowest valued entry is the one returned by
sorted(list(entries))[0]). A typical pattern for entries is a tuple in the form:(priority_number, data).
- exception
queue.Empty -
Exception raised when non-blocking
get()(orget_nowait()) is called on aQueueobject which is empty.
- exception
queue.Full -
Exception raised when non-blocking
put()(orput_nowait()) is called on aQueueobject which is full.
Queue.qsize()
Queue.empty() #return True if empty
Queue.full() # return True if full
Queue.put(item, block=True, timeout=None)-
Put item into the queue. If optional args block is true and timeout is None (the default), block if necessary until a free slot is available. If timeout is a positive number, it blocks at most timeout seconds and raises the
Fullexception if no free slot was available within that time. Otherwise (block is false), put an item on the queue if a free slot is immediately available, else raise theFullexception (timeout is ignored in that case).
Queue.put_nowait(item)-
Equivalent to
put(item, False).
Queue.get(block=True, timeout=None)-
Remove and return an item from the queue. If optional args block is true and timeout is None (the default), block if necessary until an item is available. If timeout is a positive number, it blocks at most timeout seconds and raises the
Emptyexception if no item was available within that time. Otherwise (block is false), return an item if one is immediately available, else raise theEmptyexception (timeout is ignored in that case).
Queue.get_nowait()-
Equivalent to
get(False).
Two methods are offered to support tracking whether enqueued tasks have been fully processed by daemon consumer threads.
Queue.task_done()-
Indicate that a formerly enqueued task is complete. Used by queue consumer threads. For each
get()used to fetch a task, a subsequent call totask_done()tells the queue that the processing on the task is complete.If a
join()is currently blocking, it will resume when all items have been processed (meaning that atask_done()call was received for every item that had beenput()into the queue).Raises a
ValueErrorif called more times than there were items placed in the queue. Queue.join() block直到queue被消费完毕-
3.8 生产者消费者模型
import time,random
import queue,threading
q = queue.Queue()
def Producer(name):
count = 0
while count <20:
time.sleep(random.randrange(3))
q.put(count)
print(‘Producer %s has produced %s baozi..‘ %(name, count))
count +=1
def Consumer(name):
count = 0
while count <20:
time.sleep(random.randrange(4))
if not q.empty():
data = q.get()
print(data)
print(‘\033[32;1mConsumer %s has eat %s baozi...\033[0m‘ %(name, data))
else:
print("-----no baozi anymore----")
count +=1
p1 = threading.Thread(target=Producer, args=(‘A‘,))
c1 = threading.Thread(target=Consumer, args=(‘B‘,))
p1.start()
c1.start() -
四、进程
序. multiprocessing
python 中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
4.1 Process
创建进程的类:Process([group [, target [, name [, args [, kwargs]]]]]),target表示调用对象,args表示调用对象的位置参数元组。kwargs表示调用对象的字典。name为别名。group实质上不使用。
方法:is_alive()、join([timeout])、run()、start()、terminate()。其中,Process以start()启动某个进程。
属性:authkey、daemon(要通过start()设置)、exitcode(进程在运行时为None、如果为–N,表示被信号N结束)、name、pid。其中daemon是父进程终止后自动终止,且自己不能产生新进程,必须在start()之前设置。
例4.1.1:创建函数并将其作为单个进程
import multiprocessing
import time
def worker(interval):
n = 5
while n > 0:
print("The time is {0}".format(time.ctime()))
time.sleep(interval)
n -= 1
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print "p.pid:", p.pid
print "p.name:", p.name
print "p.is_alive:", p.is_alive()结果
p.pid: 8736 p.name: Process-1 p.is_alive: True The time is Tue Apr 21 20:55:12 2015 The time is Tue Apr 21 20:55:15 2015 The time is Tue Apr 21 20:55:18 2015 The time is Tue Apr 21 20:55:21 2015 The time is Tue Apr 21 20:55:24 2015
例4.1.2:创建函数并将其作为多个进程
import multiprocessing
import time
def worker_1(interval):
print "worker_1"
time.sleep(interval)
print "end worker_1"
def worker_2(interval):
print "worker_2"
time.sleep(interval)
print "end worker_2"
def worker_3(interval):
print "worker_3"
time.sleep(interval)
print "end worker_3"
if __name__ == "__main__":
p1 = multiprocessing.Process(target = worker_1, args = (2,))
p2 = multiprocessing.Process(target = worker_2, args = (3,))
p3 = multiprocessing.Process(target = worker_3, args = (4,))
p1.start()
p2.start()
p3.start()
print("The number of CPU is:" + str(multiprocessing.cpu_count()))
for p in multiprocessing.active_children():
print("child p.name:" + p.name + "\tp.id" + str(p.pid))
print "END!!!!!!!!!!!!!!!!!"
结果
The number of CPU is:4 child p.name:Process-3 p.id7992 child p.name:Process-2 p.id4204 child p.name:Process-1 p.id6380 END!!!!!!!!!!!!!!!!! worker_1 worker_3 worker_2 end worker_1 end worker_2 end worker_3
例4.1.3:将进程定义为类
import multiprocessing
import time
class ClockProcess(multiprocessing.Process):
def __init__(self, interval):
multiprocessing.Process.__init__(self)
self.interval = interval
def run(self):
n = 5
while n > 0:
print("the time is {0}".format(time.ctime()))
time.sleep(self.interval)
n -= 1
if __name__ == ‘__main__‘:
p = ClockProcess(3)
p.start()
注:进程p调用start()时,自动调用run()
结果
the time is Tue Apr 21 20:31:30 2015 the time is Tue Apr 21 20:31:33 2015 the time is Tue Apr 21 20:31:36 2015 the time is Tue Apr 21 20:31:39 2015 the time is Tue Apr 21 20:31:42 2015
例4.1.3:将进程定义为类
4.1.4.1不加daemon属性:
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print "end!"
结果
end! work start:Tue Apr 21 21:29:10 2015 work end:Tue Apr 21 21:29:13 2015
4.1.4.2加上daemon属性:
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.daemon = True
p.start()
print "end!"
结果:
end!
注:因子进程设置了daemon属性,主进程结束,它们就随着结束了。
4.1.4.3 设置daemon执行完结束的方法:
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.daemon = True
p.start()
p.join()
print "end!"
结果
work start:Tue Apr 21 22:16:32 2015 work end:Tue Apr 21 22:16:35 2015 end!
4.2 Lock
当多个进程需要访问共享资源的时候,Lock可以用来避免访问的冲突。
import multiprocessing
import sys
def worker_with(lock, f):
with lock:
fs = open(f, ‘a+‘)
n = 10
while n > 1:
fs.write("Lockd acquired via with\n")
n -= 1
fs.close()
def worker_no_with(lock, f):
lock.acquire()
try:
fs = open(f, ‘a+‘)
n = 10
while n > 1:
fs.write("Lock acquired directly\n")
n -= 1
fs.close()
finally:
lock.release()
if __name__ == "__main__":
lock = multiprocessing.Lock()
f = "file.txt"
w = multiprocessing.Process(target = worker_with, args=(lock, f))
nw = multiprocessing.Process(target = worker_no_with, args=(lock, f))
w.start()
nw.start()
print "end"
结果(输出文件)
Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lockd acquired via with Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly Lock acquired directly
4.3 Semaphore
Semaphore用来控制对共享资源的访问数量,例如池的最大连接数。
import multiprocessing
import time
def worker(s, i):
s.acquire()
print(multiprocessing.current_process().name + "acquire");
time.sleep(i)
print(multiprocessing.current_process().name + "release\n");
s.release()
if __name__ == "__main__":
s = multiprocessing.Semaphore(2)
for i in range(5):
p = multiprocessing.Process(target = worker, args=(s, i*2))
p.start()
结果
Process-1acquire Process-1release Process-2acquire Process-3acquire Process-2release Process-5acquire Process-3release Process-4acquire Process-5release Process-4release
4.4 Event
Event用来实现进程间同步通信。
import multiprocessing
import time
def wait_for_event(e):
print("wait_for_event: starting")
e.wait()
print("wairt_for_event: e.is_set()->" + str(e.is_set()))
def wait_for_event_timeout(e, t):
print("wait_for_event_timeout:starting")
e.wait(t)
print("wait_for_event_timeout:e.is_set->" + str(e.is_set()))
if __name__ == "__main__":
e = multiprocessing.Event()
w1 = multiprocessing.Process(name = "block",
target = wait_for_event,
args = (e,))
w2 = multiprocessing.Process(name = "non-block",
target = wait_for_event_timeout,
args = (e, 2))
w1.start()
w2.start()
time.sleep(3)
e.set()
print("main: event is set")
结果
wait_for_event: starting wait_for_event_timeout:starting wait_for_event_timeout:e.is_set->False main: event is set wairt_for_event: e.is_set()->True
4.4 Queue
Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full 异常。
get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为 True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为 False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。Queue的一段示例代码:
import multiprocessing
def writer_proc(q):
try:
q.put(1, block = False)
except:
pass
def reader_proc(q):
try:
print q.get(block = False)
except:
pass
if __name__ == "__main__":
q = multiprocessing.Queue()
writer = multiprocessing.Process(target=writer_proc, args=(q,))
writer.start()
reader = multiprocessing.Process(target=reader_proc, args=(q,))
reader.start()
reader.join()
writer.join()
结果
1
4.5 Pipe
Pipe方法返回(conn1, conn2)代表一个管道的两个端。Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说 conn1和conn2均可收发。duplex为False,conn1只负责接受消息,conn2只负责发送消息。
send和recv方法分别是发送和接受消息的方法。例如,在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。如果管道已经被关闭,那么recv方法会抛出EOFError。
import multiprocessing
import time
def proc1(pipe):
while True:
for i in xrange(10000):
print "send: %s" %(i)
pipe.send(i)
time.sleep(1)
def proc2(pipe):
while True:
print "proc2 rev:", pipe.recv()
time.sleep(1)
def proc3(pipe):
while True:
print "PROC3 rev:", pipe.recv()
time.sleep(1)
if __name__ == "__main__":
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc1, args=(pipe[0],))
p2 = multiprocessing.Process(target=proc2, args=(pipe[1],))
#p3 = multiprocessing.Process(target=proc3, args=(pipe[1],))
p1.start()
p2.start()
#p3.start()
p1.join()
p2.join()
#p3.join()
结果
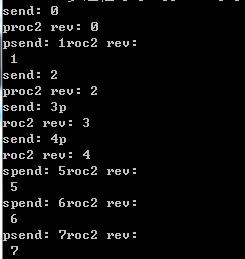
4.6 Pool
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
4.6.1 使用进程池(非阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3)
for i in xrange(4):
msg = "hello %d" %(i)
pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print "Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~"
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print "Sub-process(es) done."
一次执行结果
mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~ello 0 msg: hello 1 msg: hello 2 end msg: hello 3 end end end Sub-process(es) done.
函数解释:
- apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的(理解区别,看例1例2结果区别)
- close() 关闭pool,使其不在接受新的任务。
- terminate() 结束工作进程,不在处理未完成的任务。
- join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
执行说明:创建一个进程池pool,并设定进程的数量为3,xrange(4)会相继产生四个对象[0, 1, 2, 4],四个对象被提交到pool中,因pool指定进程数为3,所以0、1、2会直接送到进程中执行,当其中一个执行完事后才空出一个进程处理对象3,所以会出现输出“msg: hello 3”出现在"end"后。因为为非阻塞,主函数会自己执行自个的,不搭理进程的执行,所以运行完for循环后直接输出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()处等待各个进程的结束。
4.6.2 使用进程池(阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3)
for i in xrange(4):
msg = "hello %d" %(i)
pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print "Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~"
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print "Sub-process(es) done."
一次执行的结果
msg: hello 0 end msg: hello 1 end msg: hello 2 end msg: hello 3 end Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~ Sub-process(es) done.
4.6.3 使用进程池,并关注结果
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
return "done" + msg
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=4)
result = []
for i in xrange(3):
msg = "hello %d" %(i)
result.append(pool.apply_async(func, (msg, )))
pool.close()
pool.join()
for res in result:
print ":::", res.get()
print "Sub-process(es) done."
一次执行结果
msg: hello 0 msg: hello 1 msg: hello 2 end end end ::: donehello 0 ::: donehello 1 ::: donehello 2 Sub-process(es) done.
4.6.4 使用多个进程池
#coding: utf-8
import multiprocessing
import os, time, random
def Lee():
print "\nRun task Lee-%s" %(os.getpid()) #os.getpid()获取当前的进程的ID
start = time.time()
time.sleep(random.random() * 10) #random.random()随机生成0-1之间的小数
end = time.time()
print ‘Task Lee, runs %0.2f seconds.‘ %(end - start)
def Marlon():
print "\nRun task Marlon-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 40)
end=time.time()
print ‘Task Marlon runs %0.2f seconds.‘ %(end - start)
def Allen():
print "\nRun task Allen-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 30)
end = time.time()
print ‘Task Allen runs %0.2f seconds.‘ %(end - start)
def Frank():
print "\nRun task Frank-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 20)
end = time.time()
print ‘Task Frank runs %0.2f seconds.‘ %(end - start)
if __name__==‘__main__‘:
function_list= [Lee, Marlon, Allen, Frank]
print "parent process %s" %(os.getpid())
pool=multiprocessing.Pool(4)
for func in function_list:
pool.apply_async(func) #Pool执行函数,apply执行函数,当有一个进程执行完毕后,会添加一个新的进程到pool中
print ‘Waiting for all subprocesses done...‘
pool.close()
pool.join() #调用join之前,一定要先调用close() 函数,否则会出错, close()执行后不会有新的进程加入到pool,join函数等待素有子进程结束
print ‘All subprocesses done.‘
一次执行结果
parent process 7704 Waiting for all subprocesses done... Run task Lee-6948 Run task Marlon-2896 Run task Allen-7304 Run task Frank-3052 Task Lee, runs 1.59 seconds. Task Marlon runs 8.48 seconds. Task Frank runs 15.68 seconds. Task Allen runs 18.08 seconds. All subprocesses done.
以上是关于Python之路:进程线程的主要内容,如果未能解决你的问题,请参考以下文章